Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens
Abstract: Chain-of-Thought (CoT) prompting has been shown to improve LLM performance on various tasks. With this approach, LLMs appear to produce human-like reasoning steps before providing answers (a.k.a., CoT reasoning), which often leads to the perception that they engage in deliberate inferential processes. However, some initial findings suggest that CoT reasoning may be more superficial than it appears, motivating us to explore further. In this paper, we study CoT reasoning via a data distribution lens and investigate if CoT reasoning reflects a structured inductive bias learned from in-distribution data, allowing the model to conditionally generate reasoning paths that approximate those seen during training. Thus, its effectiveness is fundamentally bounded by the degree of distribution discrepancy between the training data and the test queries. With this lens, we dissect CoT reasoning via three dimensions: task, length, and format. To investigate each dimension, we design DataAlchemy, an isolated and controlled environment to train LLMs from scratch and systematically probe them under various distribution conditions. Our results reveal that CoT reasoning is a brittle mirage that vanishes when it is pushed beyond training distributions. This work offers a deeper understanding of why and when CoT reasoning fails, emphasizing the ongoing challenge of achieving genuine and generalizable reasoning.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper looks at a popular trick for getting AI LLMs to “show their work,” called Chain-of-Thought (CoT). That’s when you prompt a model with something like “Let’s think step by step,” and it writes out its reasoning before giving the final answer. Many people think this means the model is truly reasoning like a person. The authors argue that, most of the time, the model isn’t really reasoning—it’s just very good at copying patterns from its training data. When the problems look different from what it saw during training, its “reasoning” often falls apart.
The main questions the paper asks
- Does Chain-of-Thought show real reasoning, or is it mostly pattern-matching based on the training data?
- When does CoT work, and when does it fail?
- How sensitive is CoT to changes in:
- the kind of task,
- how long the reasoning chain is, and
- the way the question is worded?
How the researchers tested their ideas
To study this fairly, the authors built a clean, controlled “sandbox” called DataAlchemy. Think of it like a science lab where they can carefully control every ingredient.
- They trained small LLMs from scratch (not the giant internet-trained ones), so they knew exactly what the model had seen.
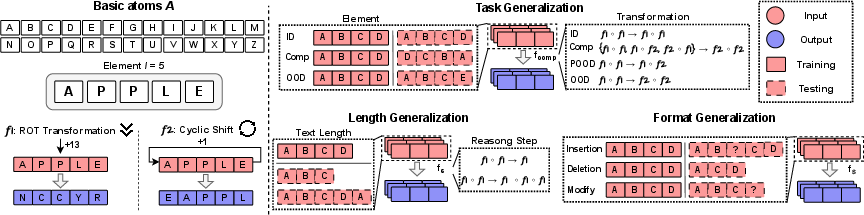
- They created simple, puzzle-like tasks using an alphabet (A–Z). An “element” is just a short string of letters, like APPLE.
- They defined two basic “transformations” (rules) the model must learn:
- ROT: shift each letter forward by a fixed number (e.g., A→N if shifting by 13).
- POSITION SHIFT: rotate the whole string (e.g., APPLE → EAPPL by moving letters around).
- They chained these transformations to mimic multi-step reasoning (like step 1, then step 2, then step 3).
- Then they challenged the model in three ways: 1) Task changes: new transformations or new combinations of transformations; new letter strings. 2) Length changes: different input lengths or different numbers of steps. 3) Format changes: rewording or tweaking how the question is written.
An analogy: they taught the model to solve simple secret codes using examples, then checked if it could still solve them when the rules, length, or wording were slightly different.
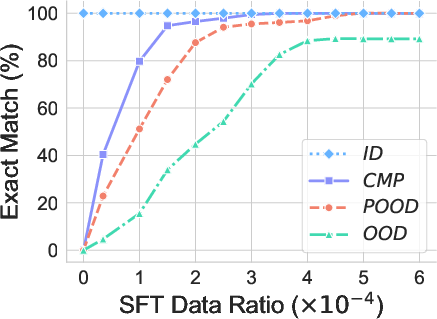
They also tried “fine-tuning” (giving the model a small number of examples from the new situation) to see if that quickly “patches” the problem.
What they found and why it matters
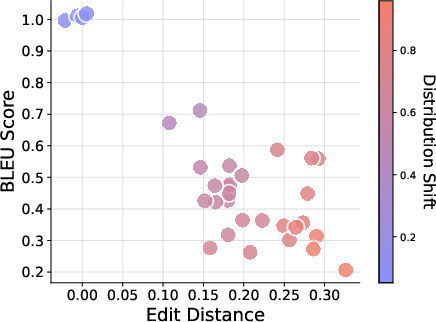
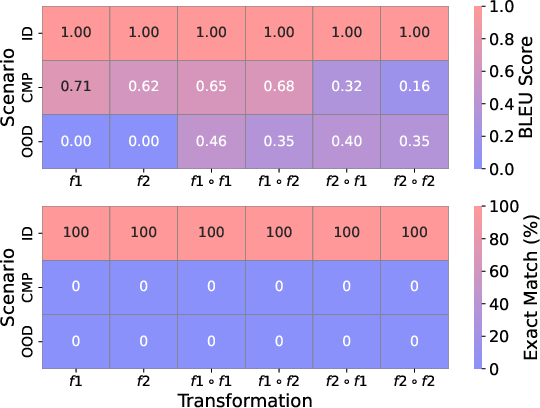
- CoT works well when test questions look like the training ones. But even modest changes can make it fail fast.
- The model often writes fluent, step-by-step explanations that sound smart but lead to wrong or inconsistent conclusions. In other words, the “reasoning” can be a mirage—convincing text without solid logic underneath.
- Three kinds of generalization were especially fragile:
- Task generalization: New transformations or new mixes of known transformations often break CoT. The model may produce a familiar-looking chain of steps but the final answer is wrong, or it gives the right answer with steps that don’t make sense (unfaithful reasoning).
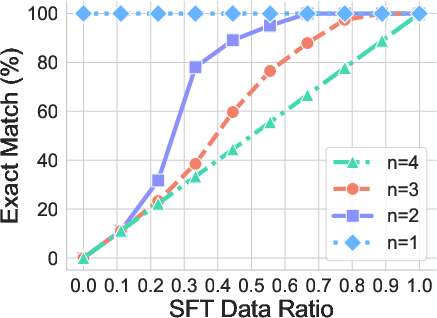
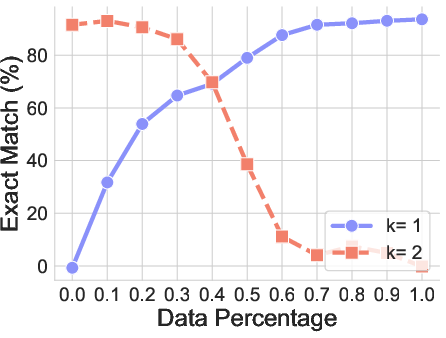
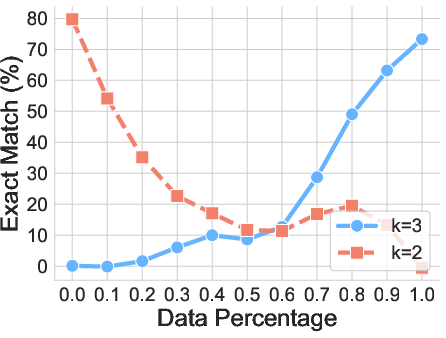
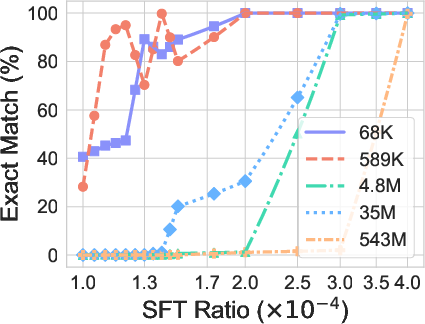
- Length generalization: If the model trained on 4-letter strings and 2-step solutions, it usually fails on 3- or 5-letter strings or 1- or 3-step solutions. It tends to force its answers into the familiar lengths it learned.
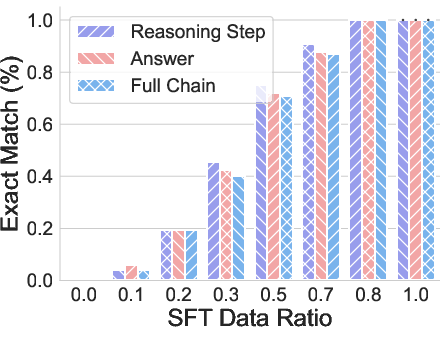
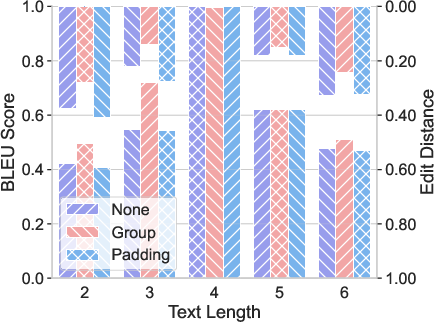
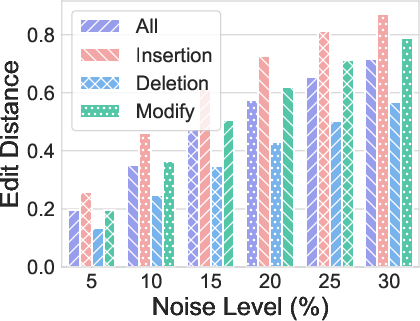
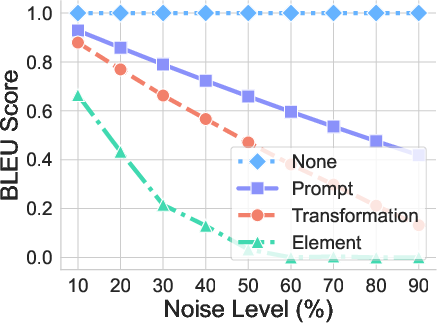
- Format generalization: Small changes to how the question is written (inserting, deleting, or modifying tokens) can sharply hurt performance, especially when changes touch the important parts (the element or the transformation instructions).
- Fine-tuning helps quickly—but mostly because it adds the new pattern to the model’s “comfort zone.” This is like expanding the bubble of familiar examples, not teaching the model to reason in a deeper way.
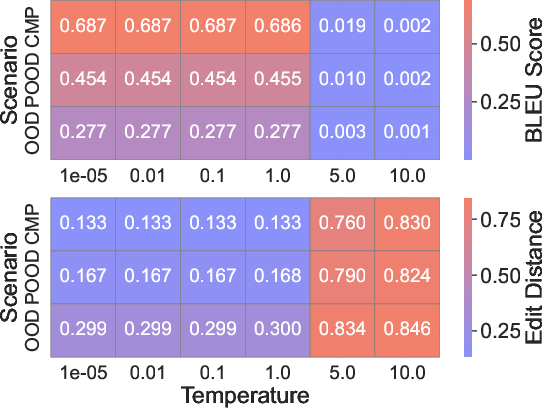
- Changing the sampling temperature (how “creative” the model is) or the model size didn’t fix the core issue: the pattern-matching nature of CoT remained.
Why it matters: If we assume CoT equals real reasoning, we risk trusting fancy-looking explanations that aren’t reliable—especially when tasks differ from training. That’s dangerous in areas like medicine, finance, or law.
What this means going forward
- Don’t confuse neat-looking reasoning steps with genuine understanding. CoT can produce “fluent nonsense.”
- Test models beyond their comfort zone. Use out-of-distribution (OOD) tests—new tasks, new lengths, new formats—to see how robust they really are.
- Fine-tuning is a useful quick fix but not a true solution. It teaches the model specific new patterns, not general reasoning skills.
- We need better methods and training that aim for real, consistent reasoning, not just pattern replication that looks like reasoning.
Bottom line
Chain-of-Thought often mirrors what the model has memorized or interpolated from its training data. It looks like reasoning, but it’s usually pattern-matching. When the puzzle changes—even a bit—the illusion often breaks. To build trustworthy AI, we must go beyond CoT-as-usual and develop models that can truly generalize their thinking.
Collections
Sign up for free to add this paper to one or more collections.