- The paper introduces a counterfactual pair generation technique that automates image-text augmentation to enhance CLIP's compositional reasoning.
- It employs a block-based diffusion strategy with dynamic weighting and specialized loss functions to accurately synthesize complex scene compositions.
- Experimental benchmarks like ARO and Winoground demonstrate improved visual reasoning and reduced training data needs compared to conventional methods.
Enhancing CLIP's Compositionality Reasoning with Counterfactual Sets
Introduction
The paper "A Visual Leap in CLIP Compositionality Reasoning through Generation of Counterfactual Sets" (2507.04699) addresses the challenges associated with Vision-LLMs (VLMs) in compositional reasoning. Despite advances in AI applications such as image retrieval and visual question answering, VLMs often fail to accurately interpret attributes, positions, and relationships among objects This results in superficial interpretations and biases which can lead to errors in advanced multimodal dialogue systems. High-quality detailed image-text pairs are lacking in existing datasets, leaving room for improvement.
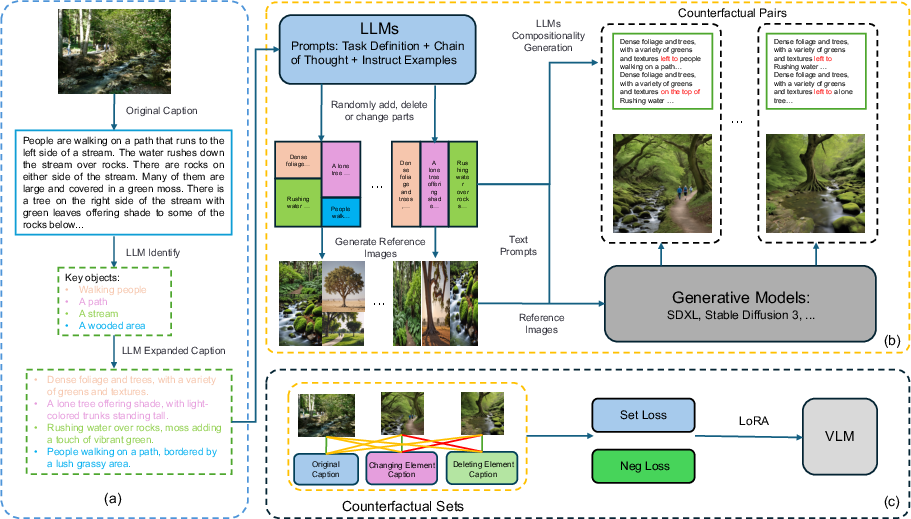
Figure 1: Generating image-text counterfactual sets involves several steps: (a) An LLM identifies and diversifies core entities from dense text descriptions. (b) Dense captions are processed through an LLM to obtain structured regional captions, which are used to generate individual images and a reference image. These regional captions are further processed to create a Compositionality Caption. (c) The reference image and Compositionality Caption are input into a diffusion model to generate images that match the Compositionality Caption, forming Counterfactual Pairs. Multiple Counterfactual Pairs are grouped into Counterfactual Sets, and specific loss functions are designed for these sets to efficiently fine-tune the text and image encoders of the CLIP model using LORA.
Methodology
Counterfactual Data Augmentation
The paper proposes generating synthetic counterfactual image-text pairs through an automated process that negates the need for manual annotation. The technique draws inspiration from solving jigsaw puzzles, wherein diverse entities are adjusted in attributes, positions, and contexts to reflect complex textual compositions in an image. LLMs are leveraged to parse textual descriptions, identify key entities, and diversify them through context enhancements. This structured data guides image generation by defining precise positioning and attributes of elements. The construction of high-quality counterfactual datasets is achieved through diversified descriptions and carefully controlled compositions of spatial and attribute modifications.
Block-based Diffusion Generation Strategy
The authors introduce a block-based diffusion approach, decomposing the image generation process into semantic regions corresponding to entities in the scene. Each region is generated as an independent block with detailed descriptions parsed from input prompts. LLMs are used to derive global scene descriptions and local positional coordinates that guide the diffusion process through text-to-image models. The technique integrates global and local processing by dynamically manipulating cross-attention layers for coherent outcome integration.
The innovation lies in a dynamic weighting mechanism that adjusts the influence of local and global guides during diffusion. Spatial masks restrict influence to predefined positions, enhancing fidelity and accuracy in composition. This approach is fundamental for generating images consistent with complex compositional relationships described in text, resulting in coherent outputs synthesized under stringent semantic guidelines.
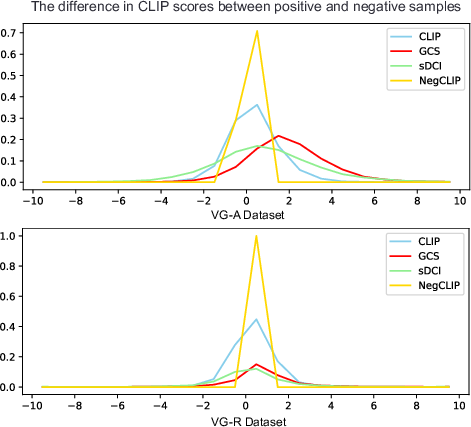
Figure 2: Compare CLIP-score differences between positive and negative descriptions on VG-A and VG-R datasets (Y-axis: proportion). Other fine-tuned models show limited improvement, while our method enlarges the gap.
Training Losses
A novel loss function specifically tailored for counterfactual datasets is presented. It restructures conventional contrastive learning into efficient intra-set and inter-set optimization while negating extensive negative sampling. Positive and negative samples within each counterfactual set contribute to the intra-set committee, and inter-set loss determines likeness across representative samples. The loss structure offers innovations that drive higher computational efficiency and enhance visual reasoning scopes.
Experimental Validation
Experiments validate the efficacy of the proposed method as superior over existing annotated datasets for visual reasoning. Extensive benchmarking against the ARO, VL-Checklist, Winoground, and sDCI benchmarks demonstrates significant performance improvements. This elevation highlights reduced training data requirements and enhanced understanding of complex relational tasks beyond conventional training sets.
Ablation studies confirm the synergistic impact of novel losses and generated data on the performance of VLMs. The block-based diffusion strategy delivers notable enhancements in image synthesis quality, maintaining robustness and generalization across tasks, thus gearing towards practical AI implementations in advanced reasoning challenges.
The results indicate that augmenting training datasets with counterfactual pairs substantially elevates model comprehension, particularly in compositionality reasoning. Metrics such as CLIP-score differences validate the heightened accuracy rates achieved through the proposed methodologies.
Conclusion
The paper offers a substantial contribution to VLM compositional reasoning through an automated block-based diffusion approach that efficiently generates high-quality counterfactual data. Significant advancements are visible in spatial reasoning capabilities and accuracy, surpassing existing frameworks with larger annotated datasets. The novel paired loss function effectively economizes computational demands while enhancing model performance across complex relational benchmarks. This foundational work promises scalable solutions in AI vision-language applications, paving pathways for deeper compositional understanding aligned with text-image congruency.

