What Has a Foundation Model Found? Using Inductive Bias to Probe for World Models
Published 9 Jul 2025 in cs.LG and cs.AI | (2507.06952v2)
Abstract: Foundation models are premised on the idea that sequence prediction can uncover deeper domain understanding, much like how Kepler's predictions of planetary motion later led to the discovery of Newtonian mechanics. However, evaluating whether these models truly capture deeper structure remains a challenge. We develop a technique for evaluating foundation models that examines how they adapt to synthetic datasets generated from some postulated world model. Our technique measures whether the foundation model's inductive bias aligns with the world model, and so we refer to it as an inductive bias probe. Across multiple domains, we find that foundation models can excel at their training tasks yet fail to develop inductive biases towards the underlying world model when adapted to new tasks. We particularly find that foundation models trained on orbital trajectories consistently fail to apply Newtonian mechanics when adapted to new physics tasks. Further analysis reveals that these models behave as if they develop task-specific heuristics that fail to generalize.
The paper introduces an inductive bias probe to assess if foundation models capture genuine world models by comparing model predictions with an oracle benchmark.
It demonstrates that despite high next-token prediction accuracy, foundation models rely on task-specific heuristics rather than true generalization.
Empirical results across orbital mechanics, lattice problems, and Othello reveal that models often develop superficial representations, necessitating revamped training strategies.
Probing Foundation Models for World Models Using Inductive Bias
This paper introduces a novel framework for evaluating whether foundation models have learned underlying world models by examining their inductive biases when adapted to new tasks. The core idea is that a foundation model that has captured a world model should exhibit an inductive bias towards the functions and relationships dictated by that world model. The "Inductive Bias Probe" technique involves adapting the foundation model to synthetic datasets generated from a postulated world model and measuring the alignment of the model's inductive bias with the world model. The paper demonstrates that foundation models often excel at training tasks but fail to develop inductive biases towards the underlying world model, indicating a lack of true understanding and generalization capabilities.
Inductive Bias Probe Framework
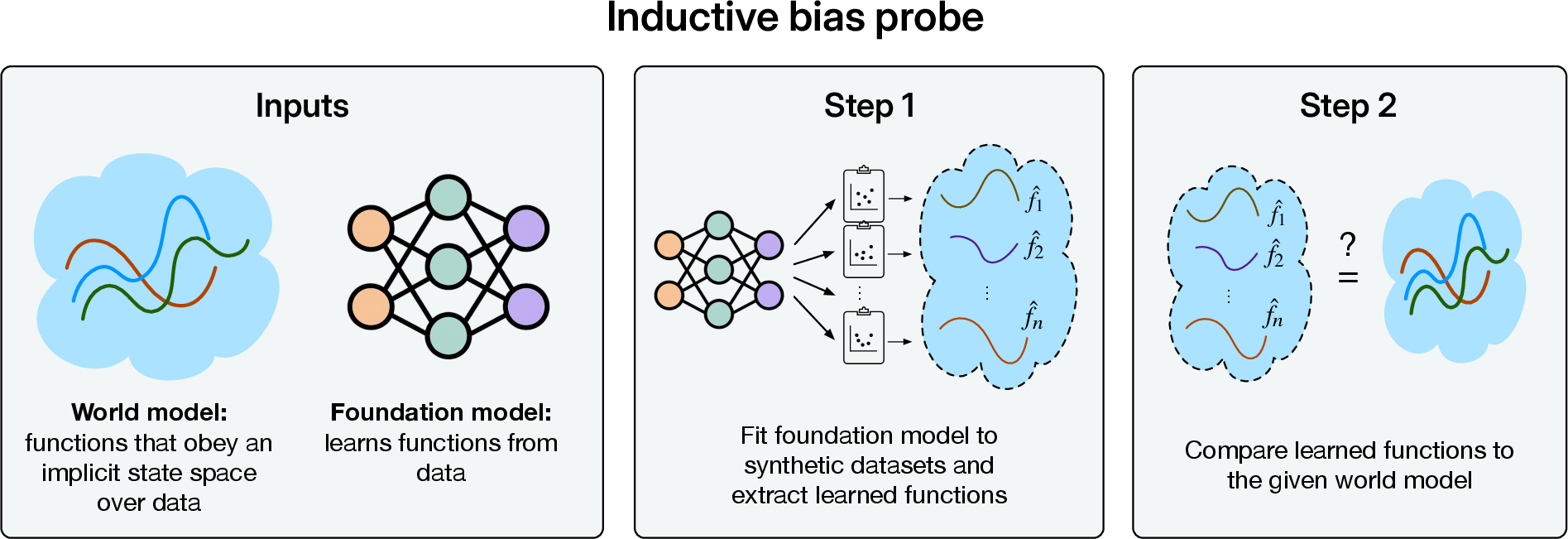
The paper formalizes the concept of an inductive bias probe, which assesses the extent to which a foundation model's behavior aligns with a postulated world model. The framework involves:
Defining a World Model: Characterizing the domain with a state space Φ and a mapping ϕ:X→Φ that associates each input x∈X with a state ϕ(x)∈Φ.
Generating Synthetic Datasets: Creating datasets D consistent with the world model, where outputs y are deterministic functions of the state, i.e., y=g(ϕ(x)) for some g:Φ→Y.
Applying the Foundation Model: Adapting the foundation model to the synthetic datasets, resulting in a prediction function mD:X→Y.
Measuring Extrapolative Predictability: Quantifying how predictable the foundation model's outputs are for one input from those of another, denoted as I(xi,xj).
Comparing to an Oracle Model: Calibrating the results against an oracle model that has direct access to the true state space Φ and admissible functions G, calculating its extrapolative predictability I∗(xi,xj).
Quantifying Inductive Bias: Defining the inductive bias (IB) towards the world model as the expected extrapolative predictability of the foundation model, conditioned on the oracle's extrapolative predictability falling within a specific range:
IB(s,s)=EXi,Xj[I(Xi,Xj)∣s≤I∗(Xi,Xj)≤s]
The inductive bias probe effectively tests whether the foundation model extrapolates in a manner consistent with the postulated world model by comparing its behavior to that of an oracle that operates directly on the state space.
Figure 1: An inductive bias probe measures whether a foundation model has an inductive bias toward a given world model. The probe involves repeatedly fitting a foundation model to small, synthetic datasets and comparing the functions it learns to the functions in the given world model.
Applications and Results
The paper presents empirical results from three domains: orbital mechanics, lattice problems, and the game of Othello.
Orbital Mechanics
A transformer model was trained to predict the locations of planets in motion across various solar systems. While the model demonstrated high accuracy in predicting trajectories, the inductive bias probe revealed a low inductive bias toward Newtonian mechanics. When fine-tuned to predict force vectors, the model's predictions implied a nonsensical law of gravitation. Symbolic regression applied to the model's force predictions yielded different, seemingly unrelated laws for different subsets of the data (Table 1), indicating that the model learned task-specific heuristics rather than a generalizable physical law. These results highlight that accurate sequence prediction does not necessarily imply a deep understanding of the underlying physical principles.
Lattice Problems
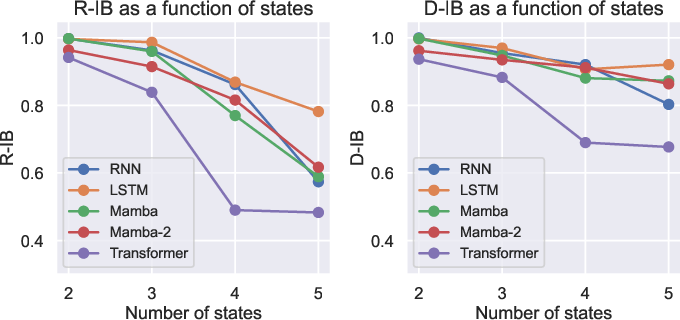
The lattice problem involves an agent moving along a line segment with a finite number of positions. The inductive bias probe revealed that while models exhibited high inductive biases when the number of states was small, the biases decreased as the number of states increased (Figure 2). This suggests that the models struggle to generalize to more complex state spaces.
Figure 2: Inductive bias probe results (R-IB and D-IB) for the lattice problem as a function of the underlying number of states. A different model is pre-trained on data consistent with each number of states and its inductive bias for that state structure is recorded using the metrics in \Cref{sec:framework}.
Othello
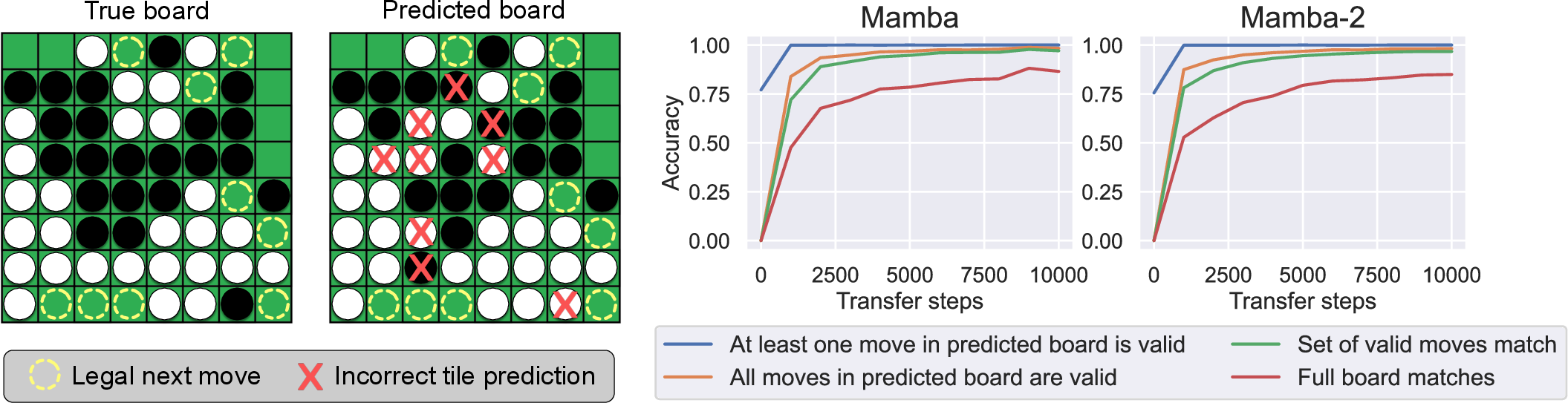
The board game Othello served as another testbed for evaluating world models. Despite the models' ability to generate legal moves nearly 100% of the time when pretrained to play Othello, the inductive bias probe indicated poor inductive bias towards the true board state. Further analysis revealed that the models tend to group together distinct board states with the same set of legal next moves, suggesting that they rely on the next-token partition rather than the complete board state for extrapolation. The transfer learning experiment to new functions of state shows that models with low inductive bias perform worse at transfer. (Figure 3)
Figure 3: On the left, a true Othello board implied by a sequence, and on the right, the predicted board from a model fine-tuned to predict boards. Although the prediction has errors, the set of predicted next tokens exactly matches the true board. On the right, metrics about board reconstruction during fine-tuning. Consistently, even as Mamba models struggle to recover full boards, they recover them well enough such that the sets of valid next moves match those in the true boards.
Implications and Future Directions
The findings suggest that foundation models may rely on superficial patterns and heuristics rather than developing genuine world models. This has significant implications for the reliability and generalizability of these models in real-world applications. The paper proposes that models may be relying on coarsened state representations or non-parsimonious representations. The next-token prediction objective appears to incentivize models to group together sequences with distinct states but equivalent sets of legal next tokens. This highlights the importance of considering alternative training objectives and architectures that encourage the development of more robust world models.
Future work should focus on methods for automatically constructing the world model implicit in a foundation model's behavior. This would enable more comprehensive and unbiased evaluations of foundation models and guide the development of models with stronger generalization capabilities.
Conclusion
The inductive bias probe provides a valuable tool for assessing the extent to which foundation models have learned underlying world models. The empirical results reveal that many sequence models, despite excelling at next-token prediction tasks, exhibit limited inductive bias toward genuine world models. These models may be relying on coarsened state representations or non-parsimonious representations. This work underscores the need for new approaches to training and evaluating foundation models that promote the development of robust, generalizable world models.