- The paper demonstrates that high-level semantics are captured by a few principal components in LLMs’ latent spaces.
- Experimental results reveal that semantic representations become linearly separable via SVMs, especially in the deeper layers of the models.
- The study highlights that chain-of-thought prompts yield distinct latent structures, paving the way for geometry-aware interventions for model safety.
This essay examines the paper "LLMs Encode Semantics in Low-Dimensional Linear Subspaces" (2507.09709), which explores how high-level semantic information is organized within the latent spaces of LLMs. Through extensive experimentation, the paper demonstrates that LLMs encode semantics in low-dimensional linear subspaces, leading to linearly separable representations across diverse semantic domains.
Intrinsic Dimensionality of Representations
The study conducts a comprehensive analysis of the intrinsic dimensionality of latent spaces across various transformer models. It is observed that a small number of principal components account for nearly all the variance in hidden states, indicating that the semantic information is compressed into low-dimensional linear subspaces.
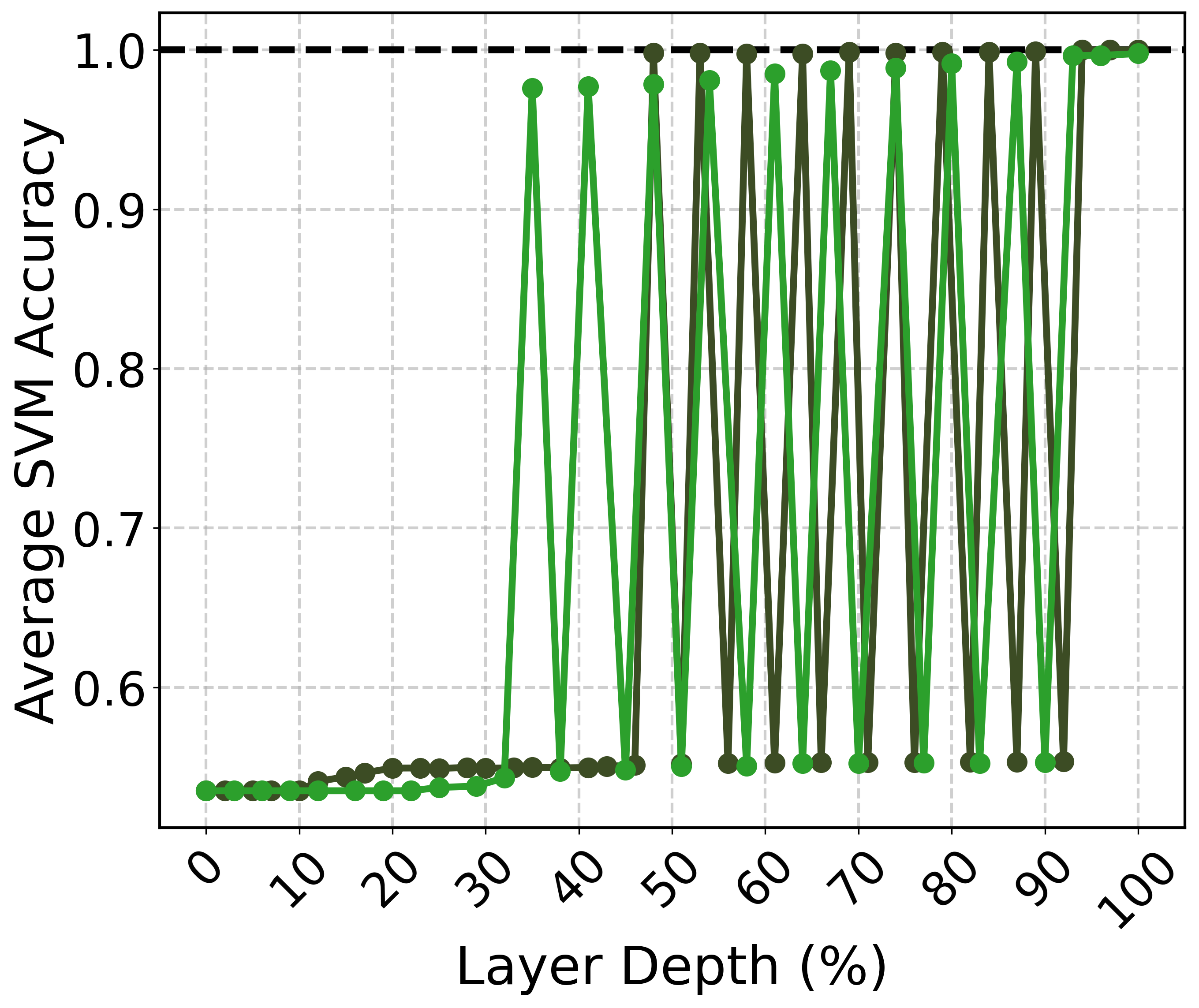
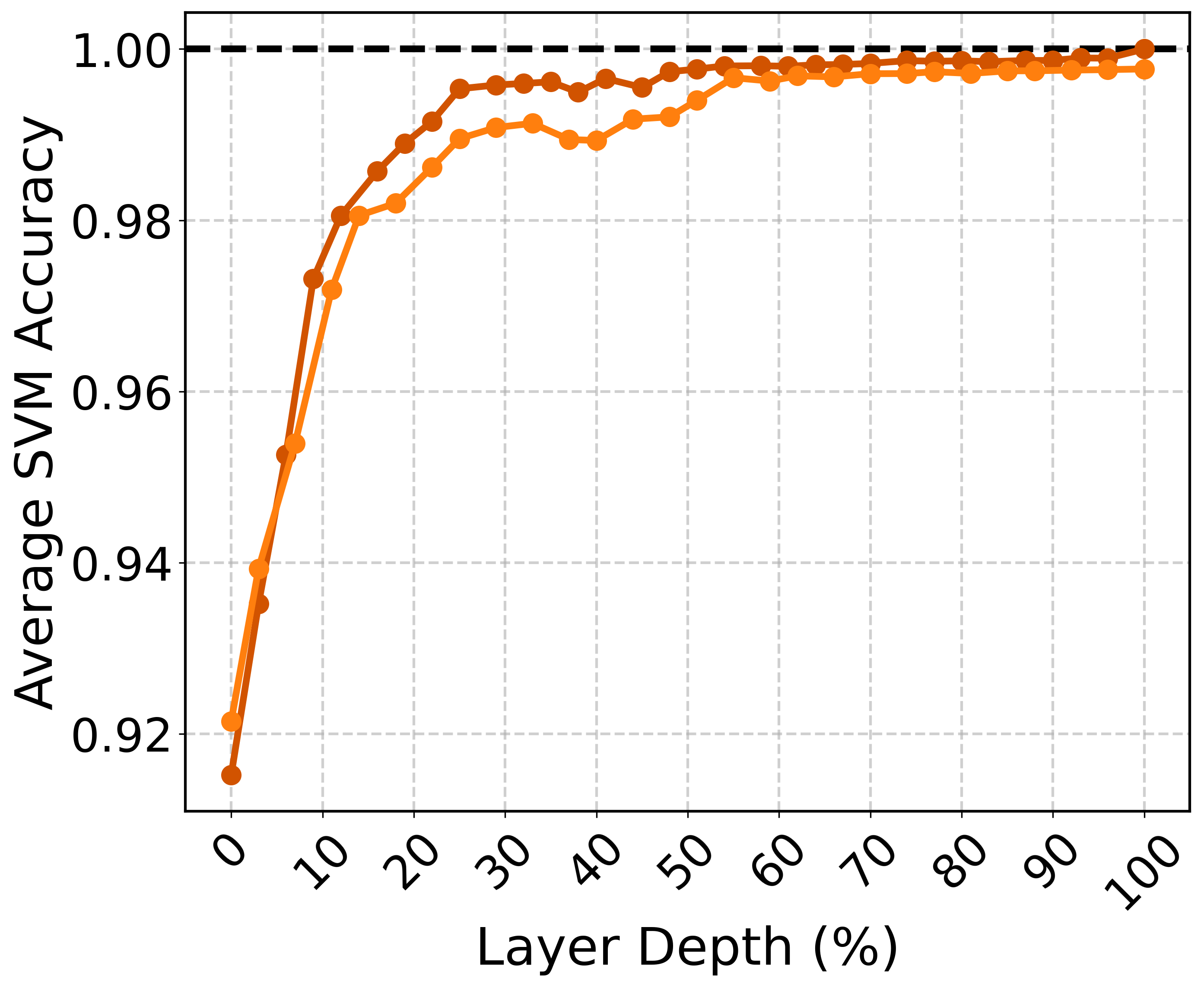
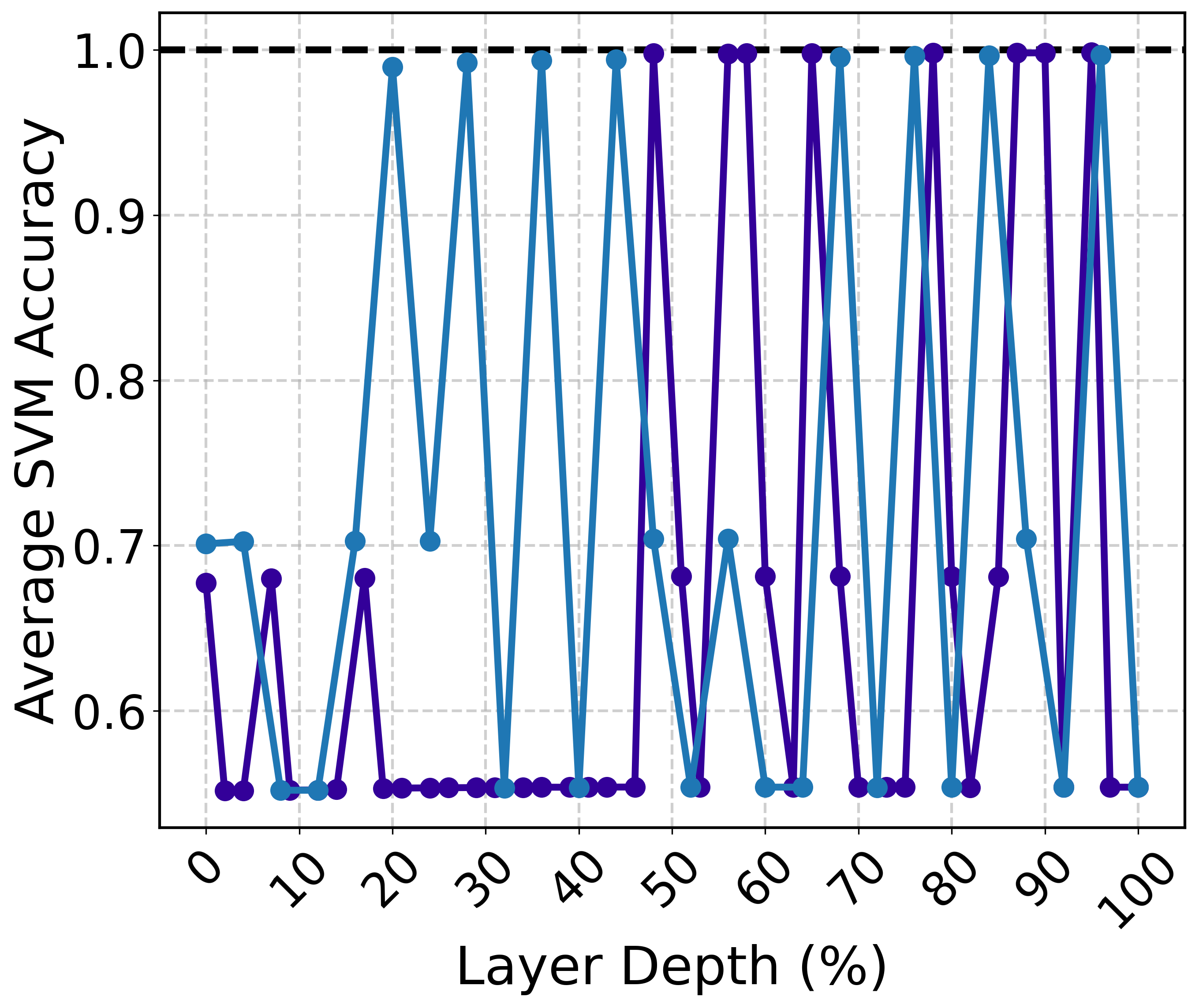
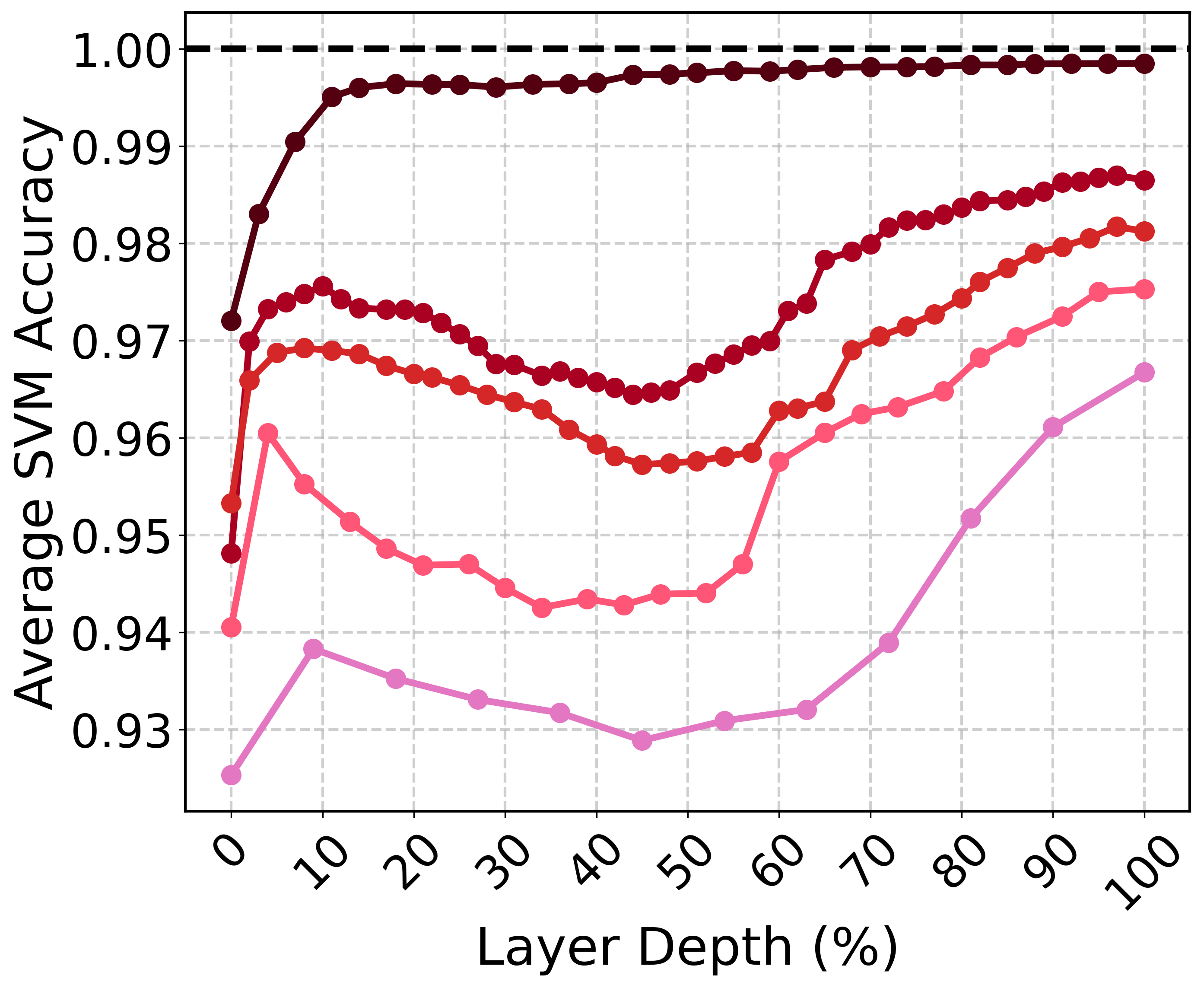
Figure 1: Percentage of principal components (relative to hidden dimensionality) required to explain at least 90% of the total variance in physics abstracts, plotted across layer depth. Darker colors indicate the larger models within each model family.
These findings suggest that while hidden representations span the entire space Rd, the effective dimensionality, which captures semantic understanding, is much lower. Interestingly, the compression does not concentrate at a particular layer depth, highlighting variations among models concerning where semantic compression occurs.
Linear Separability in Latent Spaces
The paper evaluates whether semantic representations across different topics can be linearly separated within the latent space. Using a support vector machine (SVM) to test separability, the results indicate that semantic representations of different topics form distinct clusters, especially in the final layers, achieving high classification accuracy.
Figure 2: SVM classification accuracy on representations of scientific abstracts as a function of layer depth. Results are averaged over 15 pairwise accuracies. Darker colors represent the larger model within each model family.
The research demonstrates that larger models with higher-dimensional spaces are better at linearly separating complex semantic structures. This separability increases with model depth, emphasizing the importance of the final layers in distinguishing semantic domains.
Influence of Contextual Instructions and Prompts
The paper investigates how instructions that elicit structured reasoning, such as chain-of-thought (CoT) prompts, affect the geometry of latent spaces. The study finds that CoT instructions lead to distinct, linearly separable representations, suggesting that instructions play a pivotal role in organizing and disentangling semantic content within the model's latent space.
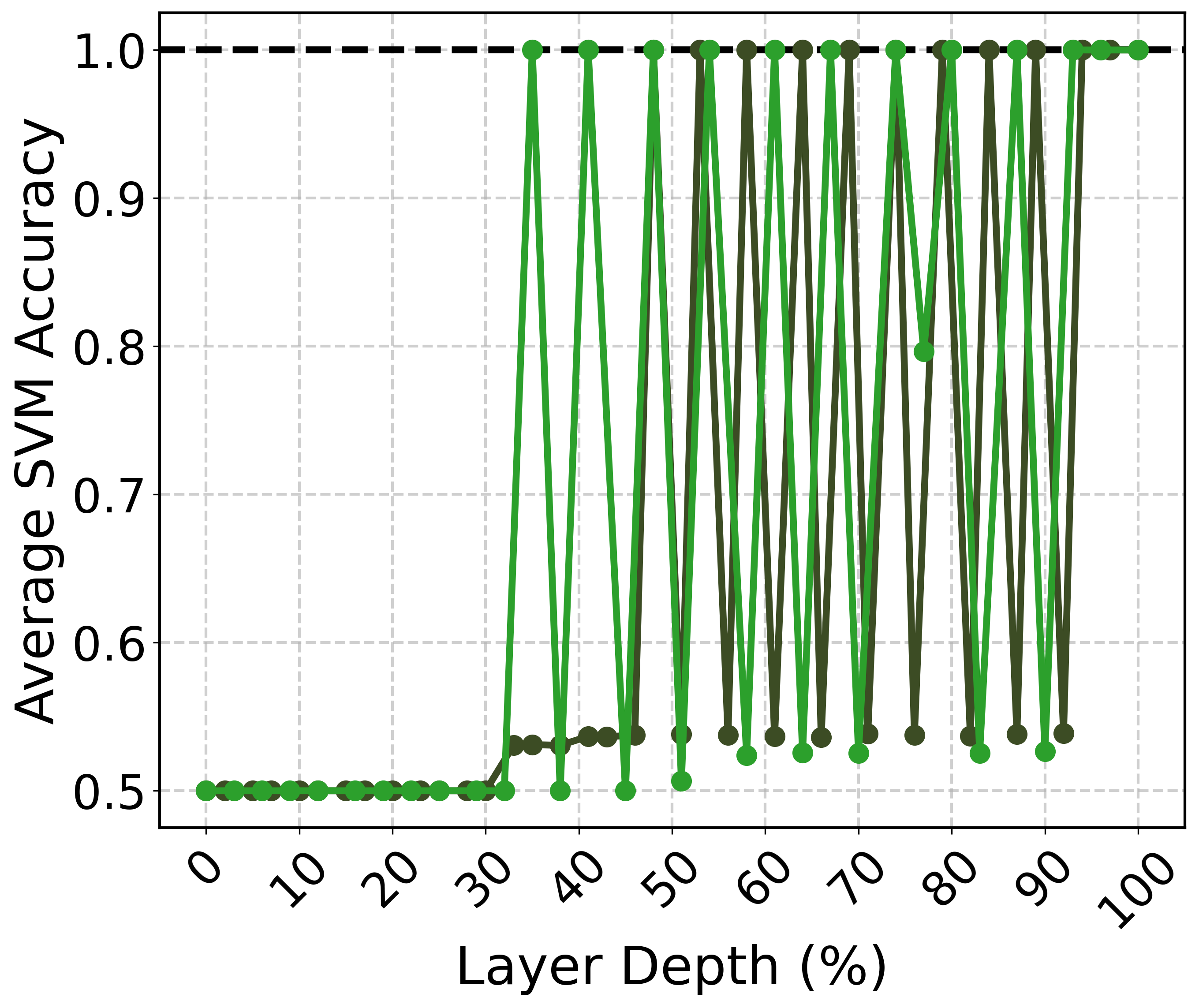
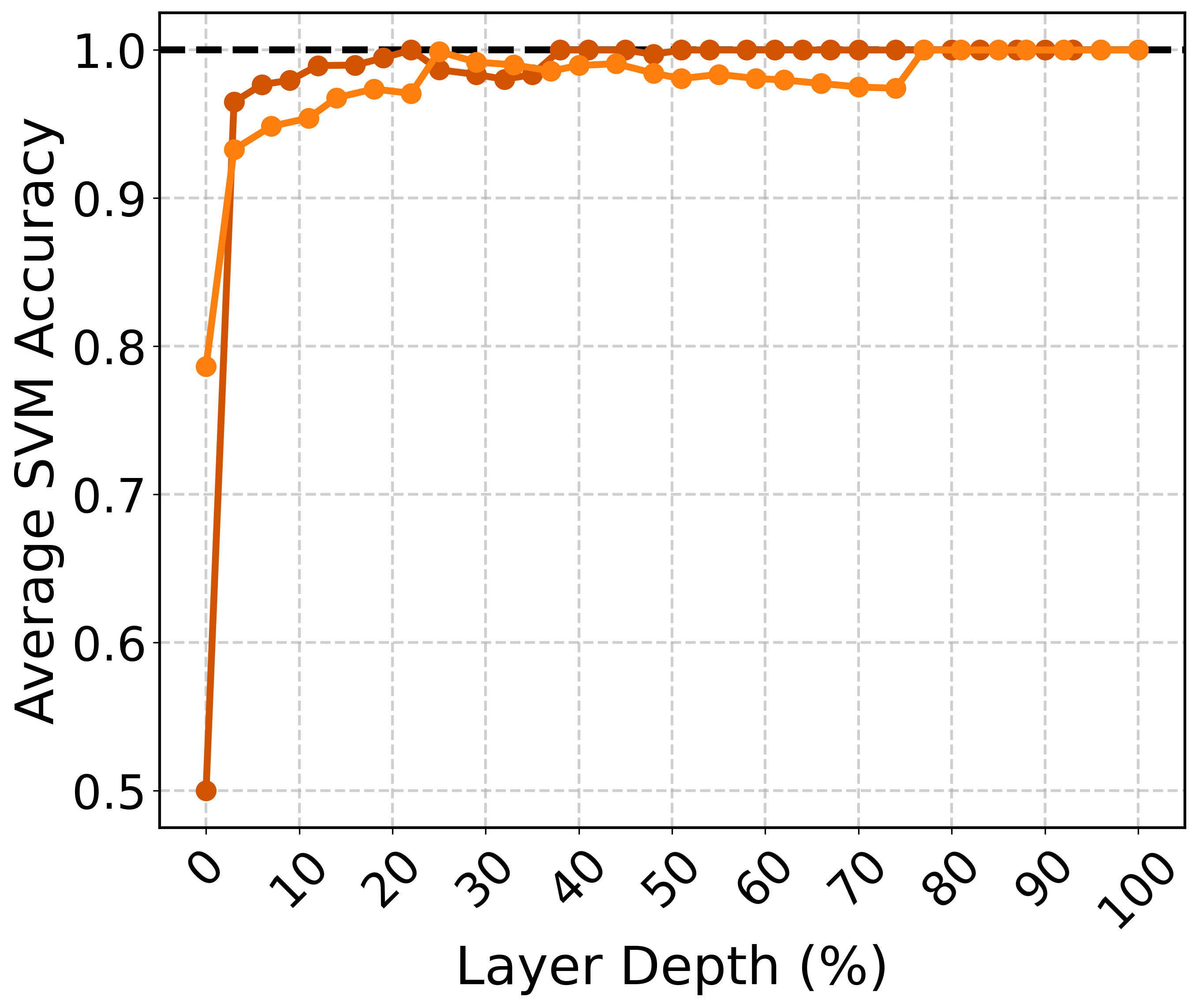
Figure 3: SVM classification accuracy on the representations of the same prompt with and without a one-sentence chain-of-thought instruction.
This behavior illustrates that even when the surface content remains unchanged, the underlying instruction can significantly impact the model's internal representation, offering insights into how semantic reasoning is encoded and influenced by external prompts.
Implications for Model Safety and Alignment
The geometric structure of latent spaces also has practical implications for model safety and alignment. By exploiting linear separability, the study proposes a latent-space guardrail using an MLP probe trained to detect malicious queries directly from hidden states. This approach demonstrates improved refusal rates for harmful prompts, showcasing the potential of geometry-aware interventions for enhancing model safety.
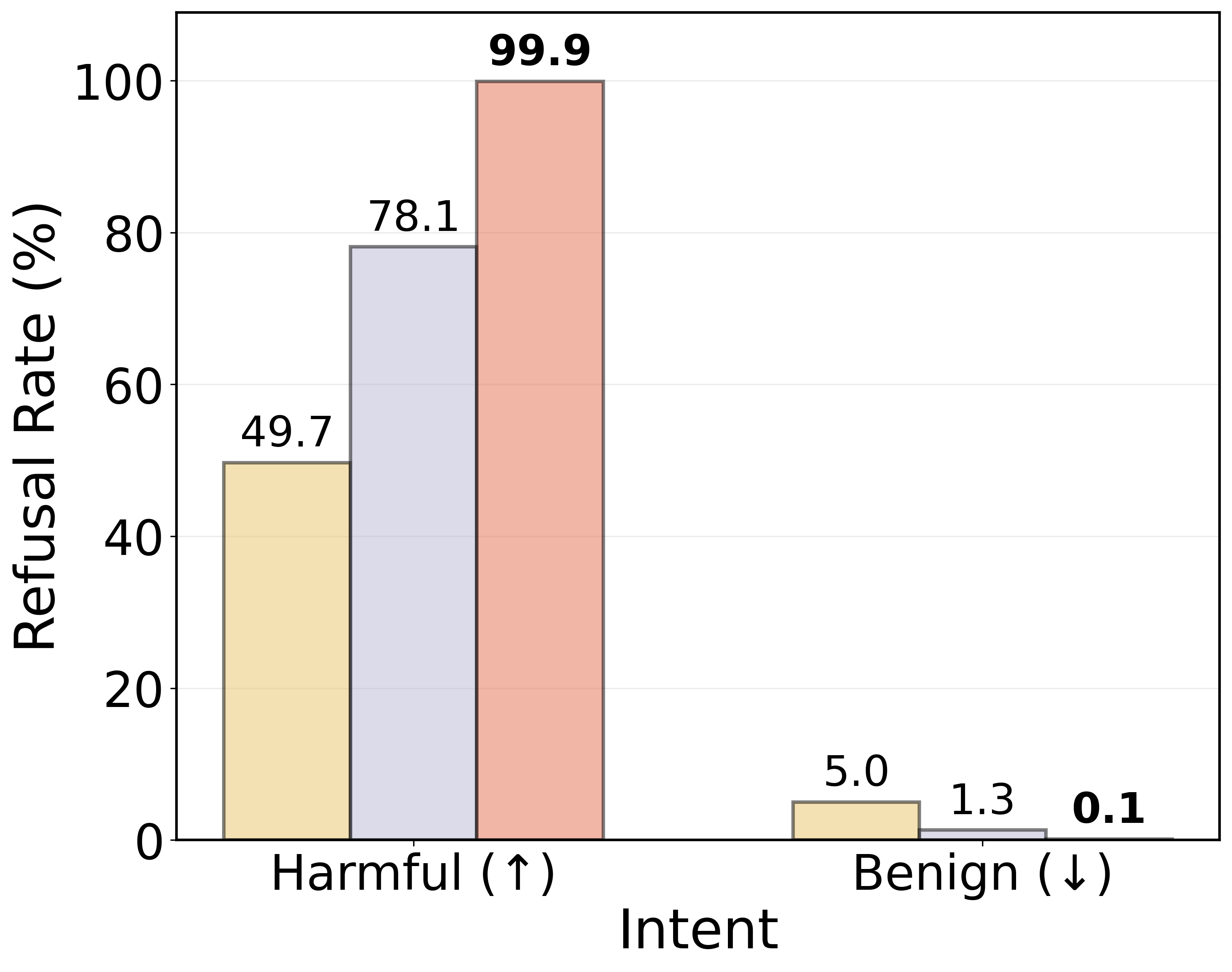
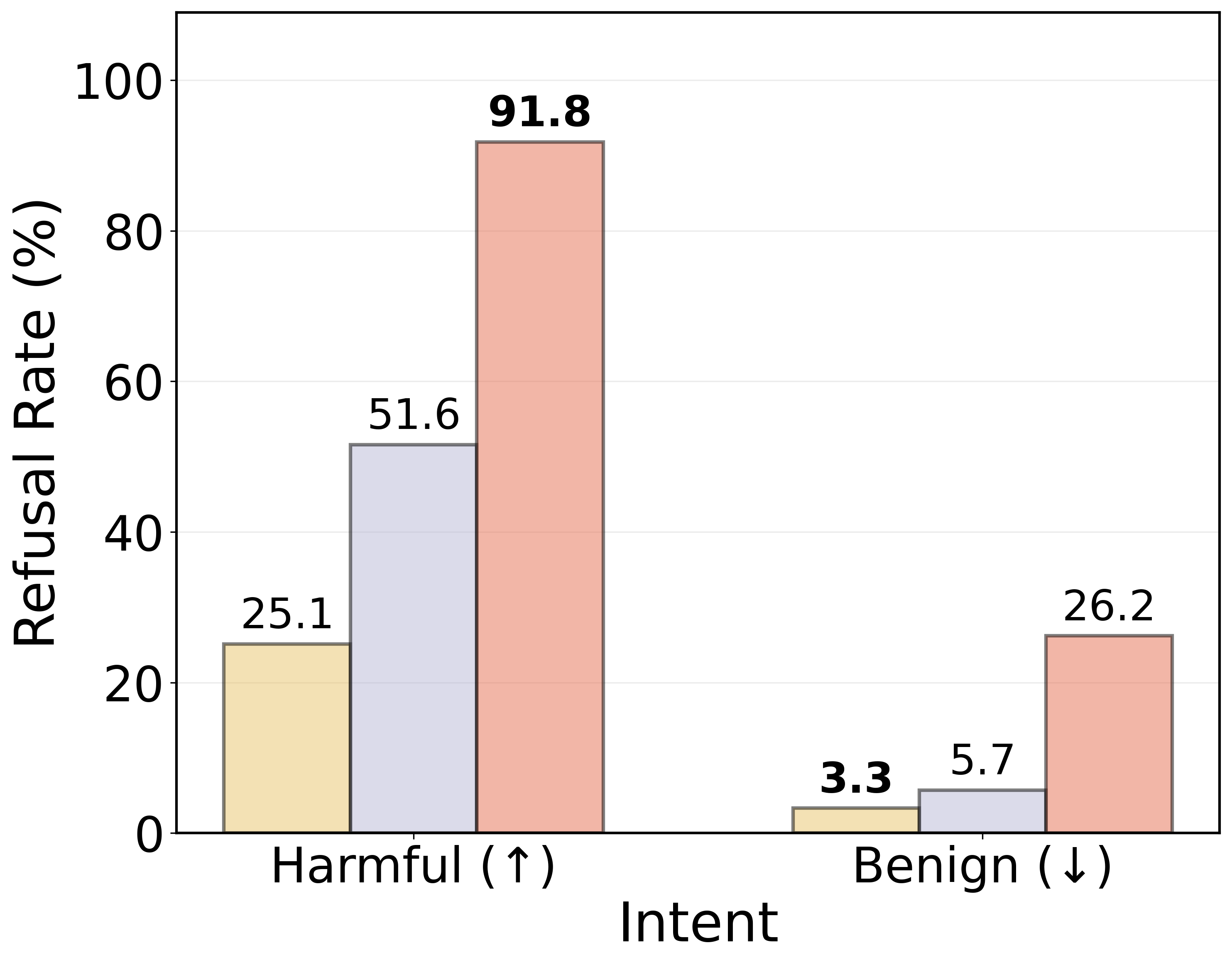
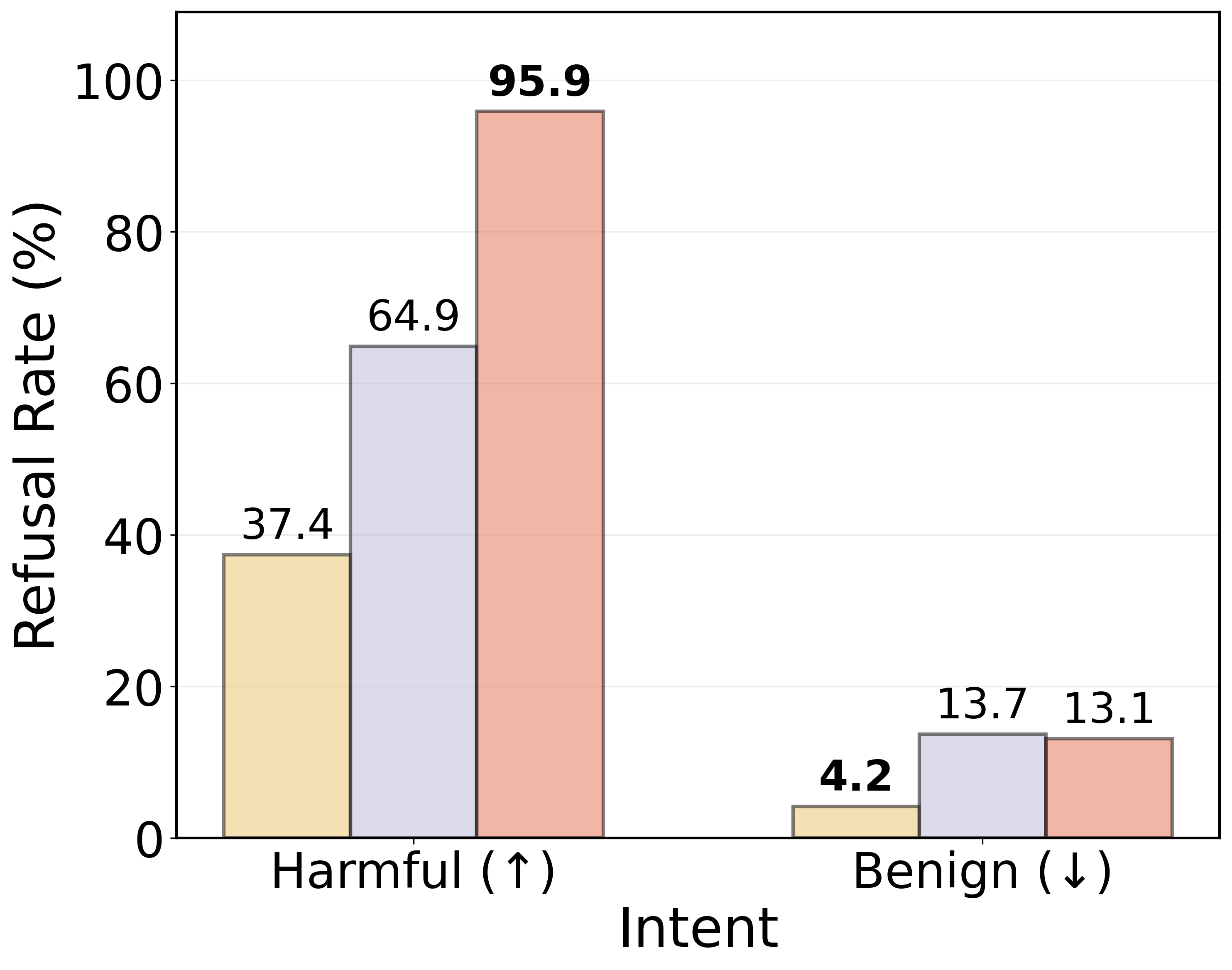
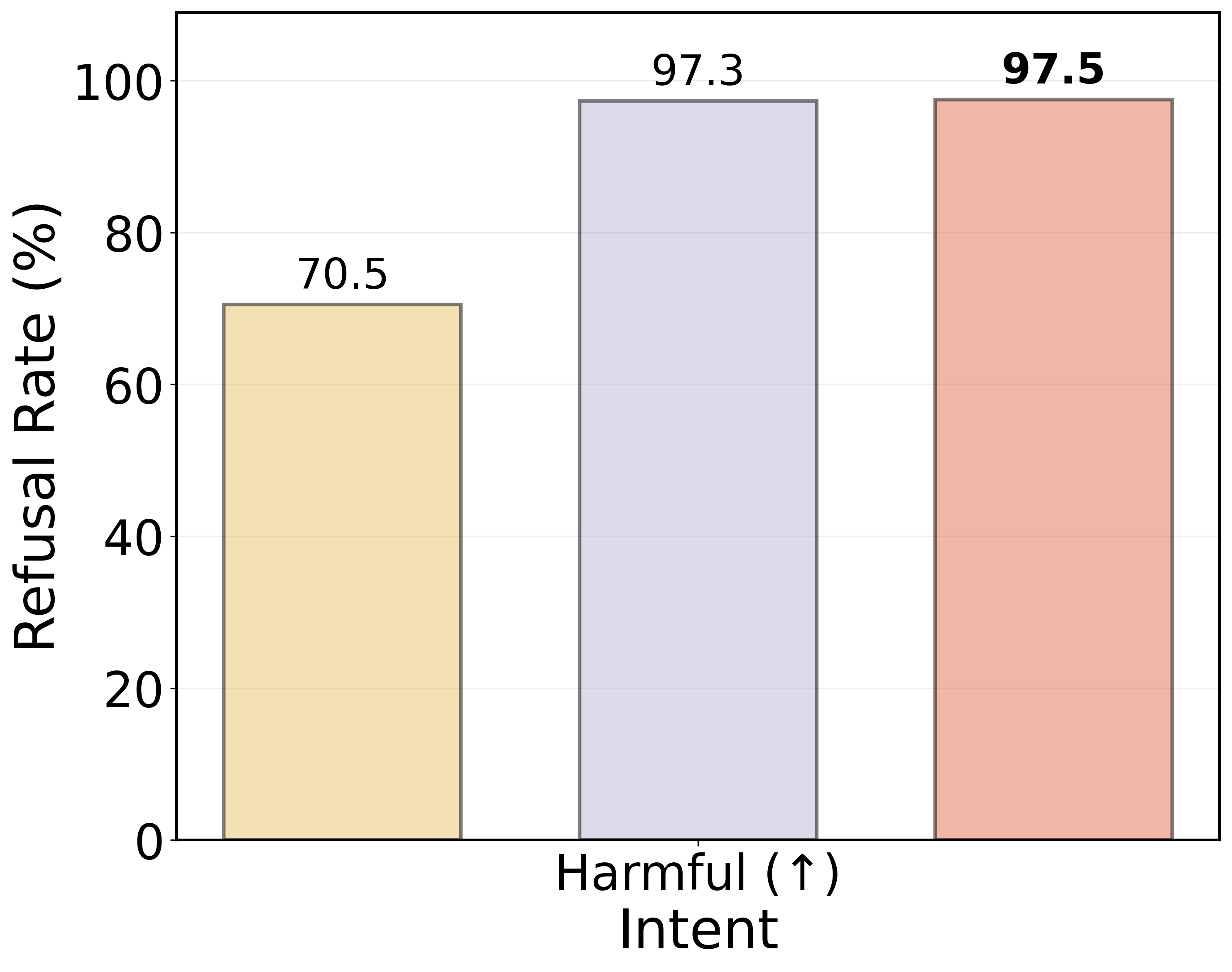
Figure 4: Refusal rates across evaluation datasets. A paired McNemar test (p<0.05) confirms that the guardrail significantly alters prompt handling—achieving higher refusal rates on harmful inputs and prompt injections compared to the baselines.
Conclusion
The paper underscores the importance of latent space geometry in LLMs, revealing that high-level semantics are organized into low-dimensional, linearly separable subspaces. This representational structure not only aids in understanding semantic encoding but also enables practical applications, such as building model safeguards within the latent space. By shedding light on the internal geometric properties, this work opens new avenues for improving model interpretability, control, and safety.