- The paper introduces the SIP framework which infers full parameter distributions under both measurement noise and intrinsic variability.
- It leverages sparsity-promoting priors, kernel density estimation, and matched block bootstrap to ensure simulated data matches empirical distributions.
- Empirical results on systems like Lotka–Volterra, Lorenz, and infiltration physics show significant RMSE improvements over traditional SINDy and UQ-SINDy methods.
Stochastic Inverse Discovery of Governing Equations under Parameter and Data Uncertainty
Introduction
The paper "Discovering Governing Equations in the Presence of Uncertainty" (2507.09740) proposes a data-driven framework for inferring governing equations of dynamical systems where system parameters and observations are corrupted by both intrinsic variability and measurement noise. In contrast to deterministic and classical Bayesian approaches, this work frames the identification problem in terms of inferring the entire distribution of governing parameters, not merely point estimates or uncertainty due to observation noise. Through the introduction of the Stochastic Inverse Physics-discovery (SIP) framework, the methodology simultaneously accounts for coefficient variability, measurement noise, and limited/noisy datasets, and uses a rigorous push-forward measure inference approach for model discovery.
Background: Shortcomings of Existing Paradigms
Traditional frameworks such as SINDy and its Bayesian extensions (e.g., UQ-SINDy) address identification from corrupted and limited data via sparse regression and uncertainty quantification, but crucially assume fixed-coefficient models. Their Bayesian generalizations quantify uncertainty solely due to observational noise, under the assumption that increasing data eliminates parameter uncertainty. This leads to consistent underestimation of model uncertainty in real-world systems with genuine, non-vanishing input or parametric variability, misidentification of relevant terms, failure to generalize, and poor model consistency across trajectories.
The SIP framework differentiates itself by explicitly modeling unknown coefficients as random variables with unknown distributions and optimizing the posterior over these distributions such that simulated observable data matches empirical distributions under both system and measurement noise.
Methodology
The core equation for a system with state x(t) and governing law f(x,ξ) is
x˙=f(x,ξ)
where coefficients ξ are treated as random variables with an unknown measure. The discovery task is to find the posterior distribution over ξ such that the push-forward of this distribution through the candidate system matches the observed data distribution as closely as possible.
This is formalized by minimizing the KL divergence between the push-forward (simulation-driven) and empirical (data-driven) distributions. The resulting inference framework employs:
- Sparsity-promoting priors: Spike-and-slab and regularized horseshoe for automatic variable selection in high-dimensional candidate libraries.
- Push-forward consistency: The inferred posterior, when pushed through the inferred equations, statistically reproduces the empirical distribution of the data.
- Matched block bootstrap (MBB): To address scenarios with limited realizations (e.g., only one trajectory per system), MBB creates statistically consistent synthetic sample paths while preserving the system's temporal dependence structure.
Inference and Computation
- Kernel Density Estimation: Likelihoods and push-forward densities over sample paths are approximated using multivariate KDEs for accurate distribution matching.
- Rejection Sampling: Posterior samples of coefficients are selected based on a normalized likelihood-pushforward ratio, ensuring efficient and consistent posterior inference.
- Theoretical Guarantees: The MBB-based data distribution and the post-inference push-forward both enjoy statistical consistency in the Kolmogorov sense, as sample sizes increase.
Empirical Results
The SIP framework's performance is evaluated on simulated and real-world data for the Lotka-Volterra (LV) predator-prey dynamics, the historical Hudson Bay data, the chaotic Lorenz system, and infiltration physics under varying fluid viscosities.
SIP precisely identifies parameter distributions under both input parameter variability and measurement noise. It achieves recovery of posterior distributions that are statistically indistinguishable from the ground truth, outperforming SINDy and UQ-SINDy, which either introduce spurious terms or exhibit inflated uncertainties and systematic biases.
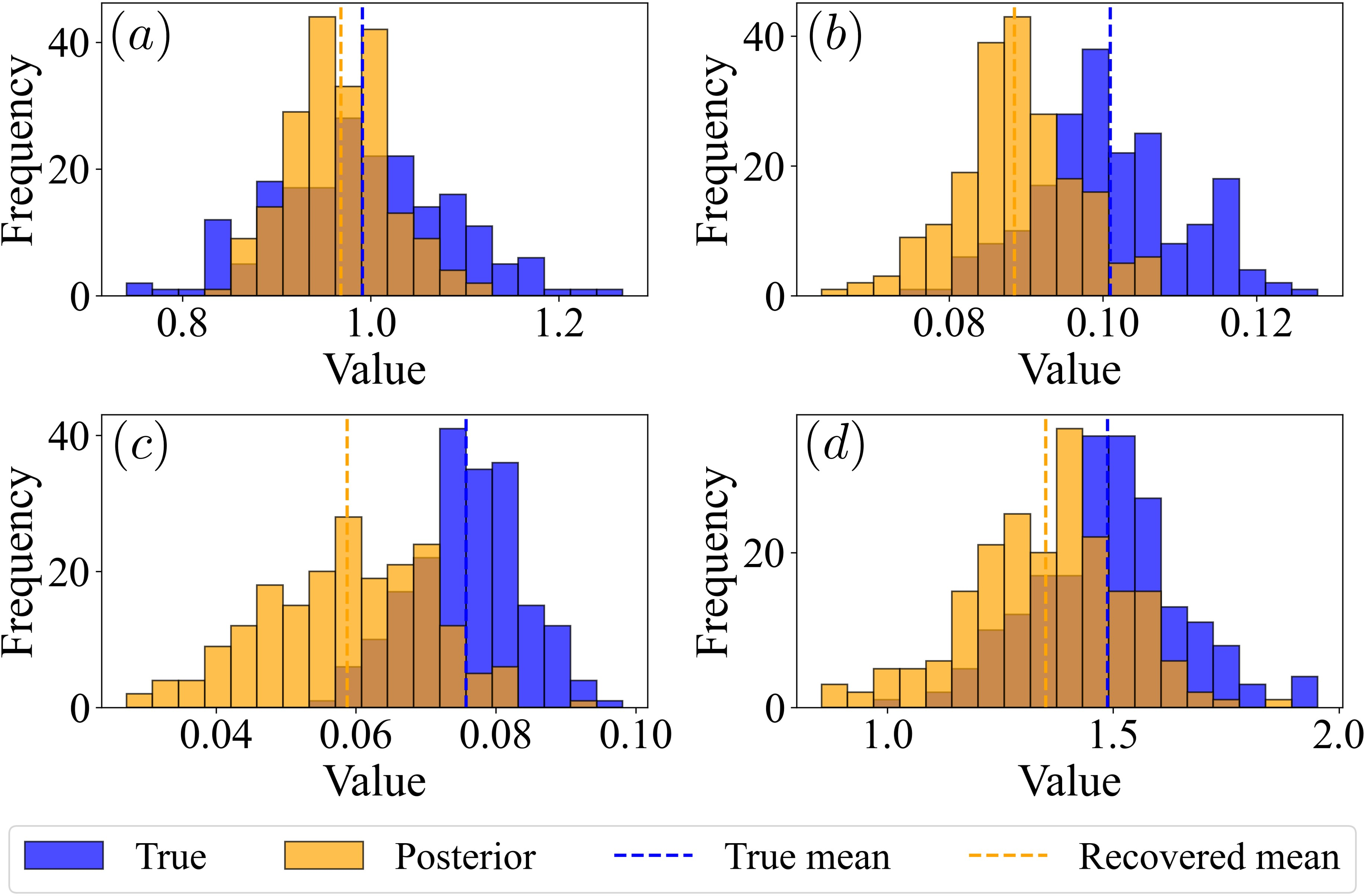
Figure 1: Comparison of the true and recovered distributions of (a) α (b) β (c) δ and (d) γ coefficients for the Lotka–Volterra system under parameter variability.
With multi-path inputs, SIP achieves nearly perfect recovery (average KL divergence ∼0.075), and RMSE reductions of 99% relative to SINDy and up to 70% versus UQ-SINDy on parameters.
Hudson Bay Predator-Prey Data: Real-World Application
Application to the Hudson Bay lynx-hare data reveals that SIP not only prunes irrelevant terms but also yields posterior marginal distributions significantly more aligned with biological expectations, compared to the broad, biased, and often multimodal posteriors produced by UQ-SINDy.
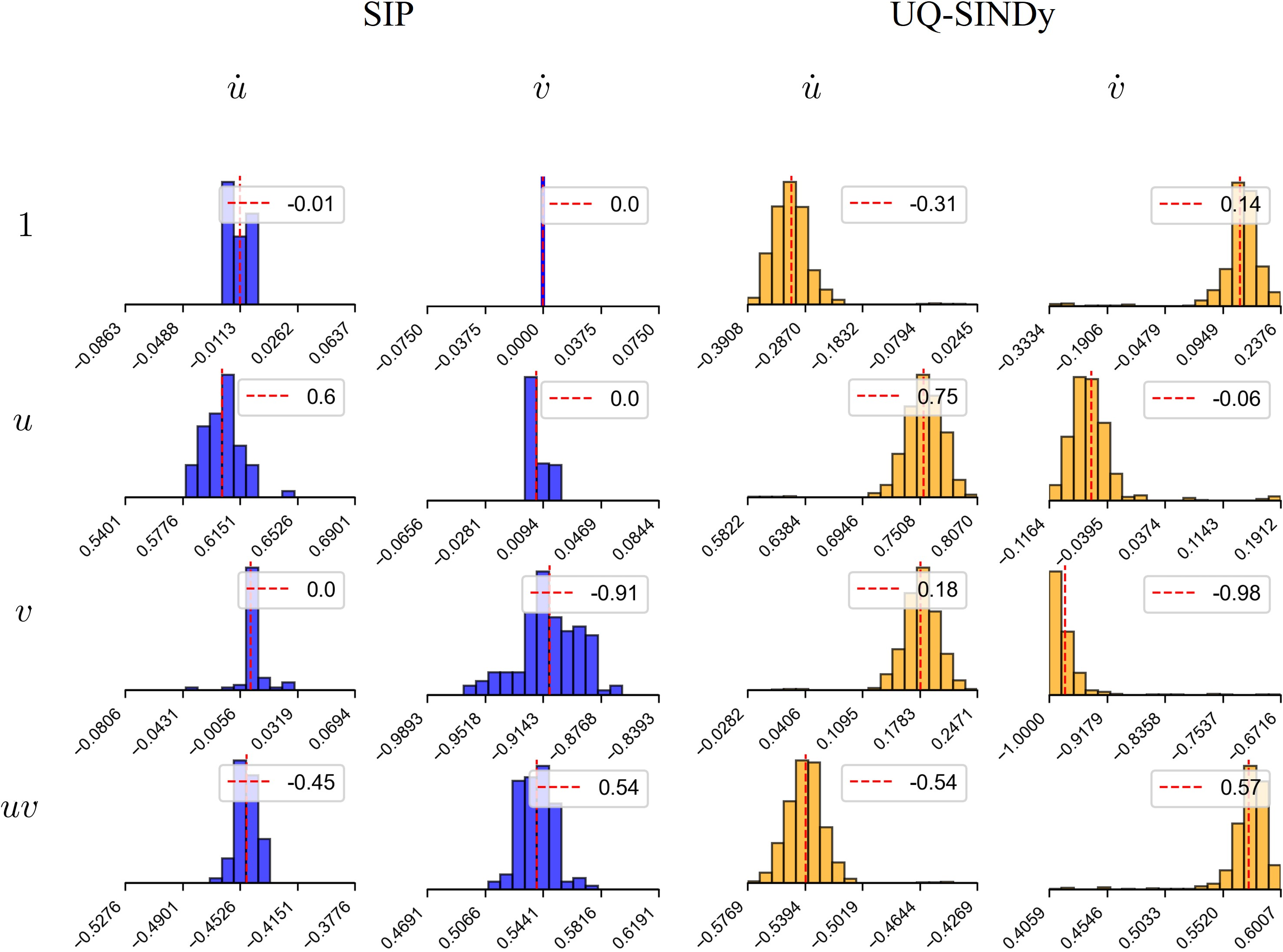
Figure 2: Posterior marginal distributions for LV coefficients inferred from Hudson Bay data; SIP (blue histograms) matches structure and magnitude, while UQ–SINDy (orange) shows bias and elevated variance.
A posterior predictive check demonstrates that 95% credible intervals from SIP contain nearly all observed data points, providing insight into the range of plausible population cycles directly induced by coefficient uncertainty, rather than merely observation noise.
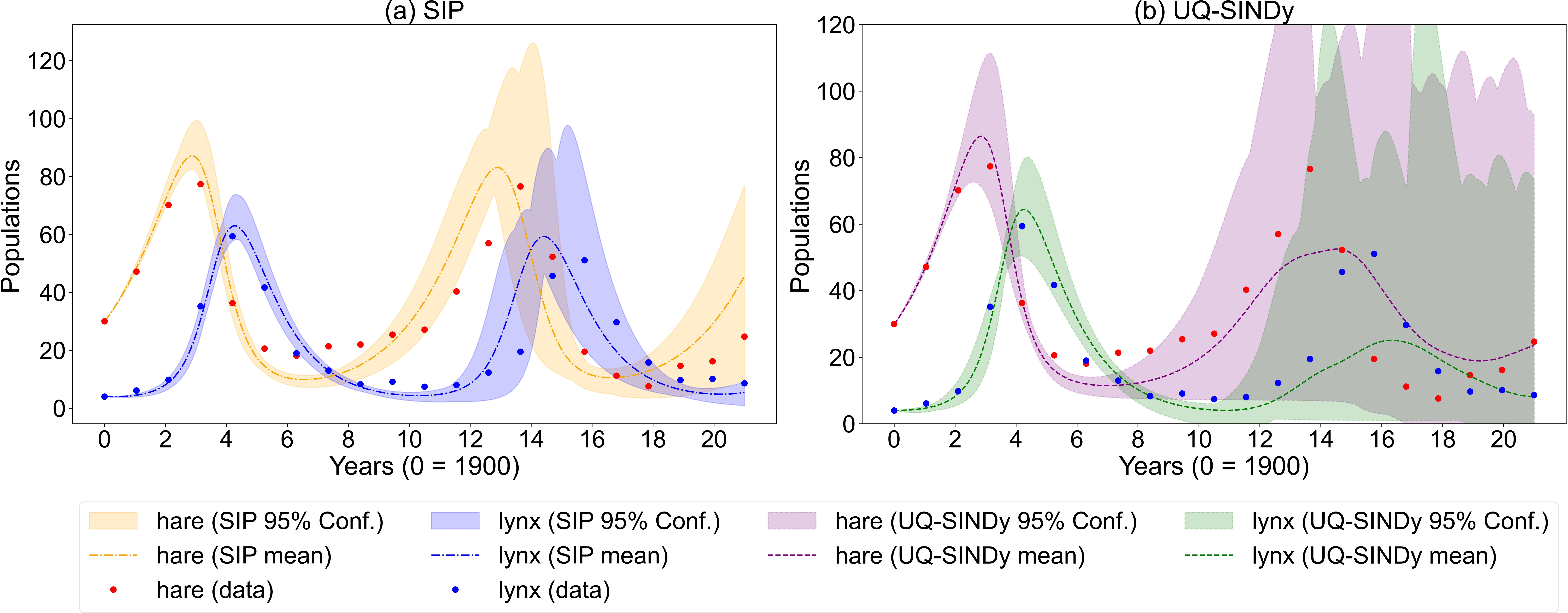
Figure 3: Posterior predictive hare–lynx trajectories for the Hudson Bay data; SIP's credible intervals (a) are narrower and better calibrated than UQ–SINDy (b).
Numerically, SIP yields RMSE reductions in coefficient recovery exceeding 80% over SINDy and 58% over UQ-SINDy.
Lorenz System: Chaotic Dynamics
For the Lorenz system, SIP robustly recovers the correct structure and tightly estimates the parameter distributions even under 10% additive noise. Competing methods miss critical terms and exhibit much higher RMSEs (95–98% improvement over SINDy and 90–96% over UQ-SINDy), demonstrating SIP's advantage in chaotic, noise-amplifying dynamics.
Infiltration Physics: Inertial and Viscous Regimes
SIP correctly identifies physically relevant terms and accurately estimates parameter distributions for infiltration in porous media, both for low-viscosity (ether, inertia-driven) and high-viscosity (silicone oil, viscous-dominated) fluids. SINDy omits essential terms and UQ-SINDy’s parameter estimates diverge from reference values; SIP achieves RMSE improvements >90% in both cases.
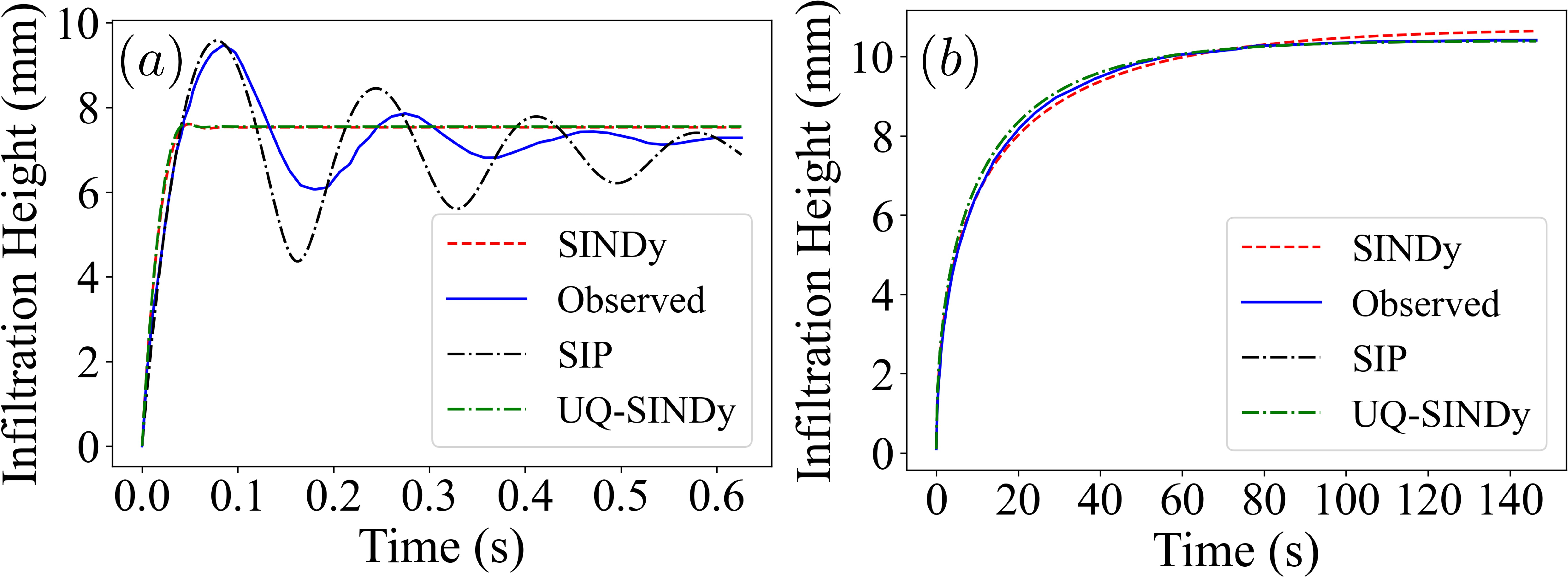
Figure 4: Predicted versus observed dynamics for (a) low viscous and (b) high viscous infiltration systems; the SIP-derived model trajectories closely match measured data in both regimes.
Implications and Future Directions
SIP constitutes a paradigm shift for physics discovery in complex systems: it provides consistent uncertainty quantification for governing equations that persists even in the infinite-data limit, reflecting irreducible system variability and real experiment noise. Posterior distributions are interpretable, highlighting both the identifiability of physical terms and the region of physical parameter space supported by the data.
Practical implications include:
- Improved generalization to unseen system conditions and trajectories, due to explicit parameter distribution modeling.
- Enhanced reliability in model-based decision-making, design, and intervention by propagating system-level uncertainties.
- True joint inference of model structure and parameter distribution, robust to sparse/limited data and stochasticity.
Future research could target:
- Separation of system and measurement noise, potentially by joint modeling of both processes.
- Advanced posterior sampling (e.g., MCMC, variational inference) to scale the approach to higher-dimensional systems.
- Application to PDE-governed systems and mixed deterministic-stochastic phenomena in biology and materials science.
Conclusion
The SIP framework described in "Discovering Governing Equations in the Presence of Uncertainty" (2507.09740) establishes a rigorous, statistically consistent methodology for discovering governing equations of dynamical systems with realistic model uncertainty. It demonstrates clear empirical advantages over fixed-coefficient and standard Bayesian model discovery approaches, providing a foundation for robust equation inference in complex, heterogeneous, and data-limited contexts.