Langevin Flows for Modeling Neural Latent Dynamics
Abstract: Neural populations exhibit latent dynamical structures that drive time-evolving spiking activities, motivating the search for models that capture both intrinsic network dynamics and external unobserved influences. In this work, we introduce LangevinFlow, a sequential Variational Auto-Encoder where the time evolution of latent variables is governed by the underdamped Langevin equation. Our approach incorporates physical priors -- such as inertia, damping, a learned potential function, and stochastic forces -- to represent both autonomous and non-autonomous processes in neural systems. Crucially, the potential function is parameterized as a network of locally coupled oscillators, biasing the model toward oscillatory and flow-like behaviors observed in biological neural populations. Our model features a recurrent encoder, a one-layer Transformer decoder, and Langevin dynamics in the latent space. Empirically, our method outperforms state-of-the-art baselines on synthetic neural populations generated by a Lorenz attractor, closely matching ground-truth firing rates. On the Neural Latents Benchmark (NLB), the model achieves superior held-out neuron likelihoods (bits per spike) and forward prediction accuracy across four challenging datasets. It also matches or surpasses alternative methods in decoding behavioral metrics such as hand velocity. Overall, this work introduces a flexible, physics-inspired, high-performing framework for modeling complex neural population dynamics and their unobserved influences.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to model how groups of neurons in the brain change their activity over time. The key idea is to use a physics-inspired equation (called the Langevin equation) to describe hidden “latent” factors that drive the overall pattern of spikes across many neurons. These hidden factors evolve with a mix of predictable rules, natural rhythms, and randomness—much like a ball rolling through a bumpy landscape with some friction and occasional gusts of wind.
What questions does the paper ask?
In simple terms, the authors want to know:
- Can we model the hidden, underlying patterns that explain how large groups of neurons fire over time?
- Can we do this in a way that captures both steady internal brain dynamics and unpredictable influences (like noise or unmeasured inputs)?
- Will this help us better predict neural activity and even behavior (like how the hand moves)?
How does the method work?
Think of the brain like an orchestra: many instruments (neurons) play together, but a smaller set of hidden “themes” (latent factors) guide the overall music. This model tries to discover those hidden themes.
Here are the main parts, explained with everyday analogies:
- Latent factors: These are the hidden drivers of the neural population. You don’t see them directly, but they explain why many neurons move together in certain patterns.
- Langevin dynamics: Imagine a marble rolling across a landscape of hills and valleys.
- Inertia: If the marble is moving, it tends to keep moving.
- Damping (friction): Movement slowly fades unless something keeps pushing it.
- Potential landscape: The shape of the hills and valleys that guides where the marble goes. Here, it’s designed to encourage smooth, wave-like rhythms (like brain rhythms).
- Random pushes (noise): Little nudges that make the path less predictable, like gusts of wind.
“Underdamped” means the marble doesn’t stop immediately; it can oscillate (wiggle) before settling—similar to the brain’s natural rhythms.
- Oscillatory potential from coupled oscillators: The “landscape” is built using a network of simple, locally connected oscillators (like a row of springs connected to each other). This naturally creates smooth, traveling waves—patterns that are often seen in real brain activity.
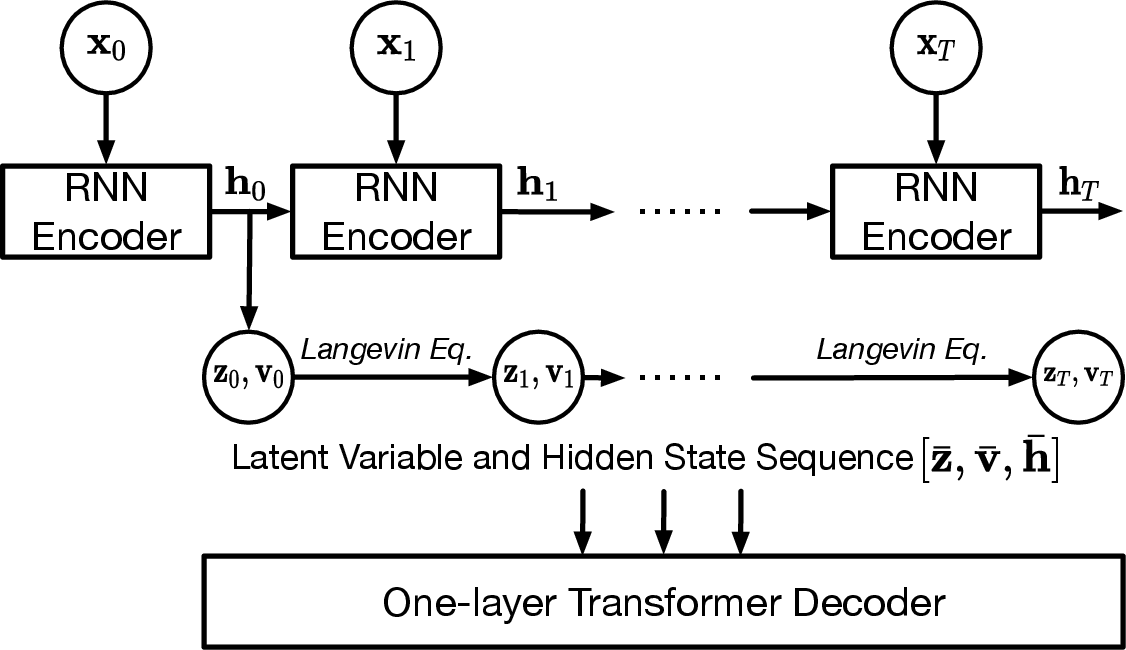
- Variational Autoencoder (VAE): This is a learnable two-part system:
- An encoder (a GRU, a type of recurrent neural network) reads the spike trains and produces initial hidden factors.
- The hidden factors then evolve over time using the Langevin rules (inertia + damping + noise + the wave-shaped landscape).
- A decoder (a small Transformer that “looks” at the whole sequence at once) turns the hidden factors back into predicted firing rates for each neuron. The spikes are modeled as random events whose average rate is what the decoder predicts.
- Why a GRU and a Transformer?
- GRU: Good at capturing local, moment-to-moment changes in time.
- Transformer: Good at using information from the whole sequence to make better predictions, even when events are far apart in time.
- Training the model: The system learns by trying to reconstruct the observed spikes while keeping the hidden factors simple and realistic. It balances accuracy with not overfitting, and it learns the shape of the “landscape” that encourages wave-like dynamics.
What did they find?
The authors tested their method on both synthetic and real neural data.
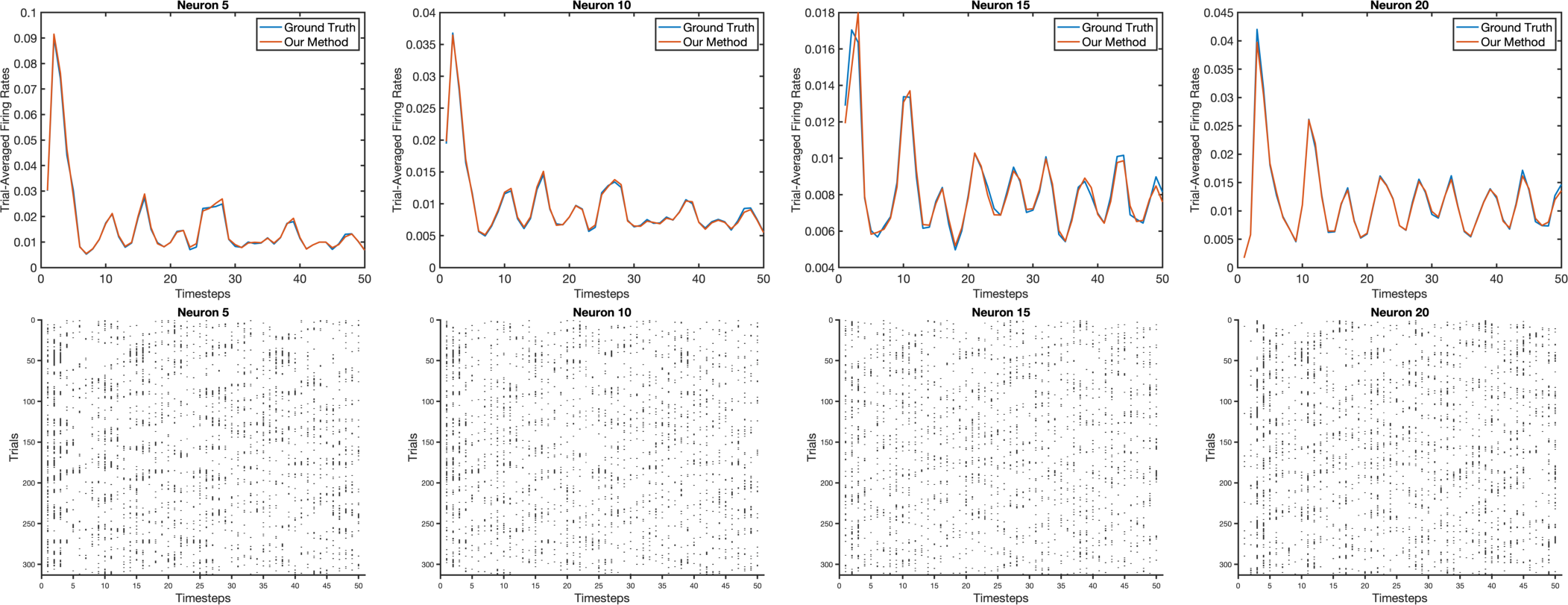
- Synthetic test (Lorenz attractor):
- They created fake neural data from a well-known chaotic system (the Lorenz attractor—often used as a stand-in for complex dynamics like weather).
- The new method predicted the true firing rates more accurately than strong baselines (like AutoLFADS and NDT).
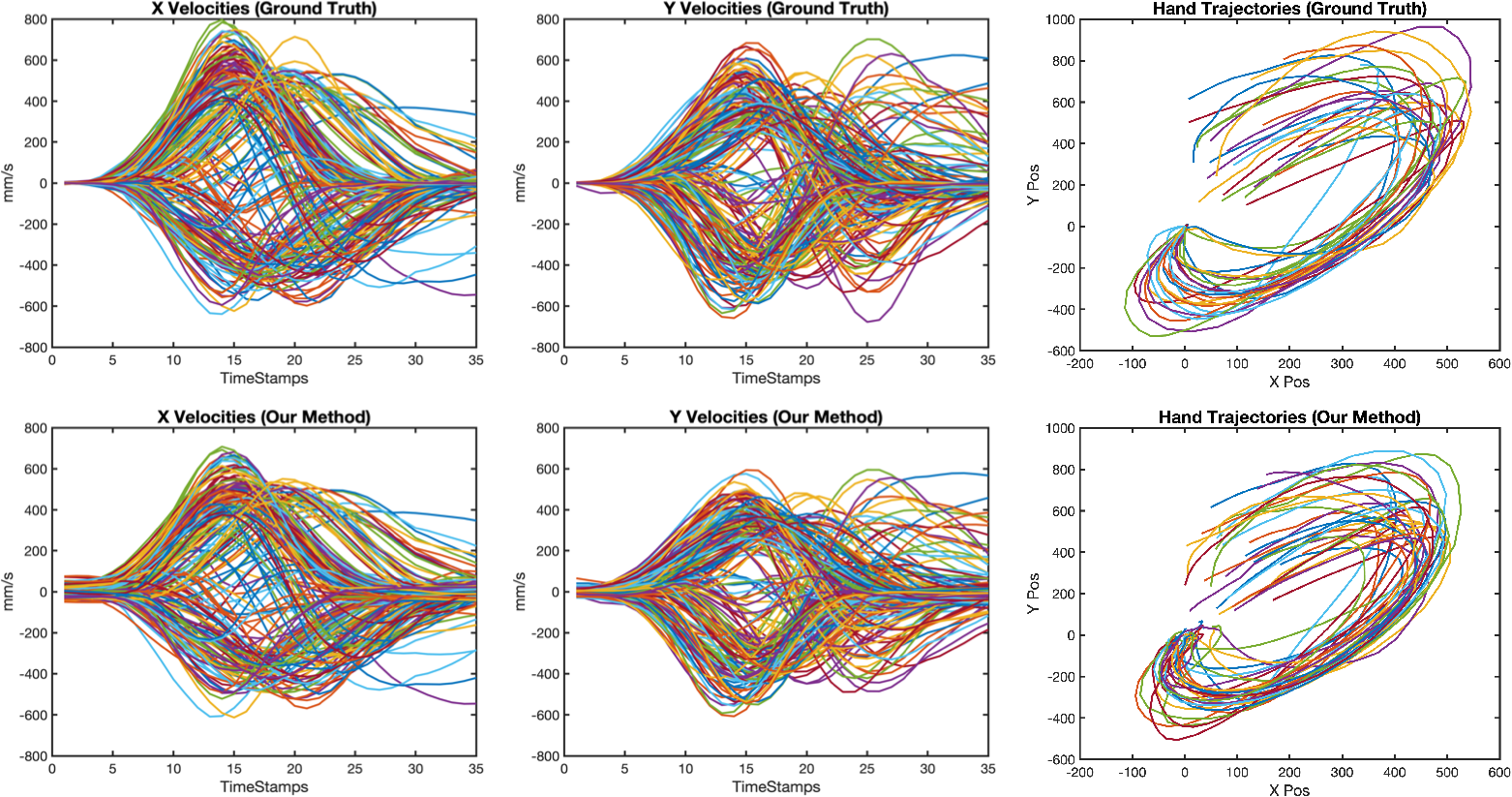
- Real data (Neural Latents Benchmark with four datasets: MC_Maze, MC_RTT, Area2_Bump, DMFC_RSG; sampled at both 5 ms and 20 ms):
- It achieved state-of-the-art performance at predicting held-out neurons’ activity (co-smoothing, bits per spike) and future spikes (forward prediction).
- It also performed comparably or better at decoding behavior, like hand velocity.
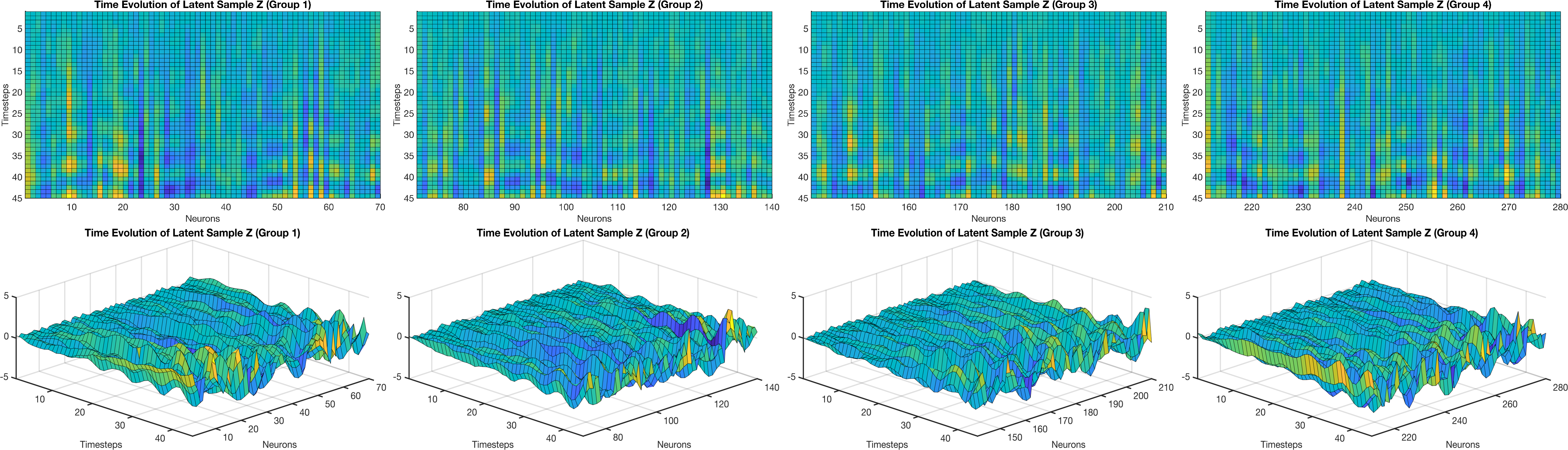
- The learned hidden factors showed smooth, traveling wave patterns—similar to those reported in real brain recordings—suggesting the model is capturing meaningful neural dynamics, not just fitting noise.
Why is this important? Better prediction of neural activity and behavior means we’re doing a good job capturing how the brain coordinates many neurons. Seeing realistic wave-like patterns in the hidden space also makes the model more interpretable and biologically plausible.
What does it mean for the future?
This work shows that mixing physics-based ideas (like inertia, friction, and potential landscapes) with modern machine learning (GRUs and Transformers) can make powerful, interpretable models of brain activity. Potential impacts include:
- Better tools for understanding how groups of neurons coordinate over time.
- Improved methods for brain-computer interfaces that rely on predicting neural activity and behavior.
- A flexible framework to explore different “landscapes,” which could reveal new principles of how the brain organizes rhythms and information flow.
In short, using a “marble-in-a-landscape” view for hidden brain dynamics—combined with today’s best sequence models—helps us both predict neural data more accurately and understand it more deeply.
Collections
Sign up for free to add this paper to one or more collections.