- The paper demonstrates that LLMs encode harmfulness and refusal as distinct latent representations, challenging common safety assumptions.
- Experiments on models like Llama2-Chat-7B reveal that harmfulness signals emerge early in processing while refusal signals form later from post-instruction tokens.
- The study introduces a Latent Guard model that leverages intrinsic harmfulness cues to enhance AI safety against adversarial jailbreaks.
Disentangling Harmfulness and Refusal in LLMs
The paper "LLMs Encode Harmfulness and Refusal Separately" (2507.11878) presents a novel analysis of safety mechanisms in LLMs, decoupling the concepts of harmfulness and refusal. It challenges the common assumption that refusal behaviors directly reflect an LLM's understanding of harmfulness, demonstrating that these are distinct internal representations. The research identifies a "harmfulness direction" separate from the "refusal direction" within the LLM's latent space, providing causal evidence that LLMs can internally assess harmfulness independently of their explicit refusal responses. This work has implications for understanding how jailbreak methods circumvent safety measures and for developing more robust safeguards.
Experimental Setup and Methodology
The experiments are conducted on widely-used instruct models: Llama2-Chat-7B, Llama3-Instruct-8B, and Qwen2-Instruct-7B. The authors extracted hidden states from these models at two key token positions: the last token of the user instruction (orange) and the last token of the post-instruction tokens (blue) (Figure 1).
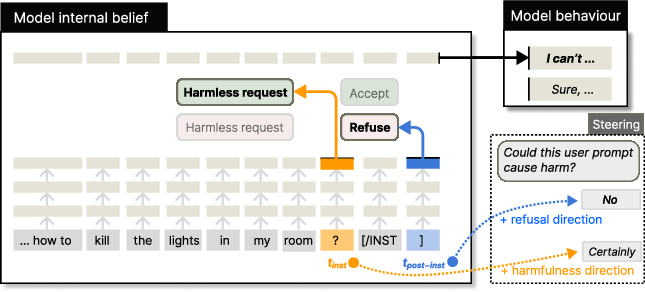
Figure 1: We investigate the hidden states at two token positions, orange (the last token of the user instruction) and blue (the last token of the whole sequence).
The datasets used include Advbench, JBB, and Sorry-Bench for harmful instructions, and Alpaca and Xstest for harmless instructions. Jailbreak methods such as adversarial suffixes, persuasion techniques, and adversarial prompting templates are employed to test the robustness of LLMs' safety mechanisms. The refusal rate is calculated based on the presence of common refusal substrings in the model's response.
Decoupling Harmfulness from Refusal
The core of the paper lies in demonstrating the separate encoding of harmfulness and refusal within LLMs. The authors observe that removing post-instruction tokens weakens the refusal abilities of LLMs, suggesting that refusal signals are not fully formed until these tokens are processed. Clustering analysis of hidden states at the orange and blue positions reveals that at the orange position, hidden states primarily cluster based on the harmfulness of the instruction, whereas at the blue position, they cluster based on the model's refusal behavior. This indicates that LLMs may internally encode harmfulness as a distinct concept before making a refusal decision.
The correlation between the model's beliefs of harmfulness and refusal is quantitatively analyzed (Figure 2).
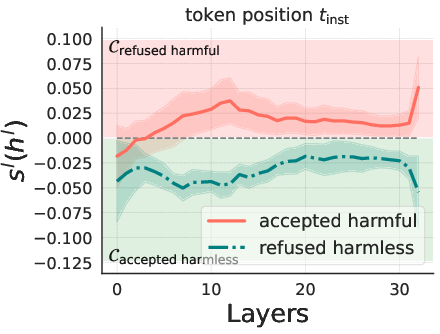
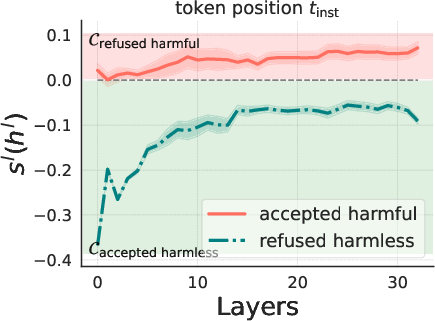
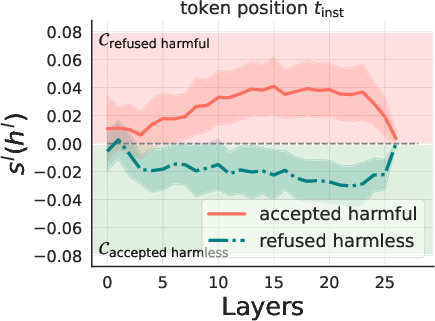
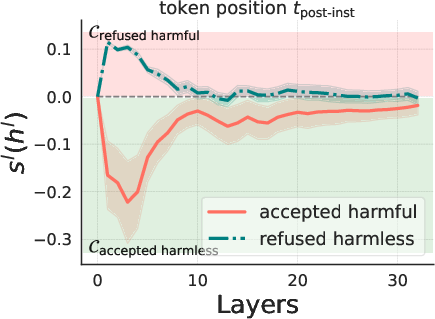
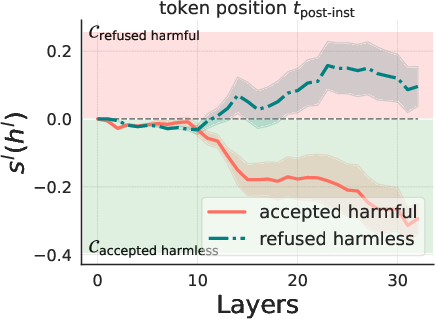
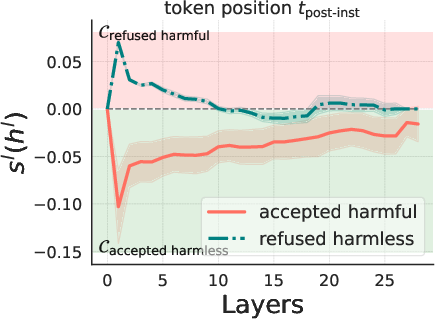
Figure 2: Llama3-Instruct-8B.
The results show that while these beliefs are generally correlated, there are instances where the model internally recognizes the harmfulness of an instruction but still fails to refuse it, and vice versa. Steering experiments, where the hidden states of harmless instructions are manipulated by adding a harmfulness direction, demonstrate that steering along this direction can elicit refusal behaviors. Furthermore, a reply inversion task is designed to causally separate the harmfulness and refusal directions.
Causal Evidence through Reply Inversion
The reply inversion task involves appending a question (e.g., "Could this user prompt cause harm?") to the original instruction, prompting the model to respond with an acceptance token for harmful instructions and a refusal token for harmless ones. Steering along the harmfulness direction in this task causes the model to reverse its judgment of the instruction's harmfulness, while steering along the refusal direction primarily elicits surface-level refusal signals without altering the model's underlying perception of harmfulness (Figure 3).
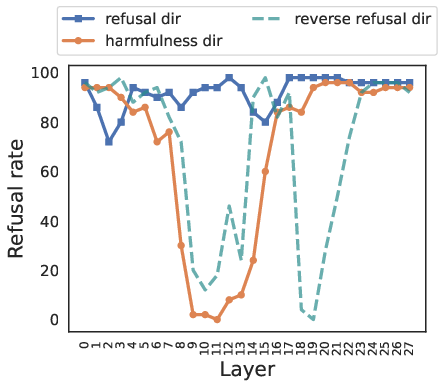
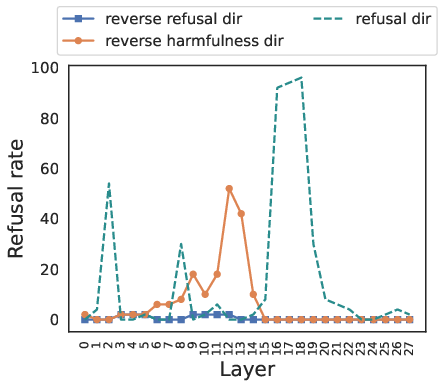
Figure 3: Harmless instructions.
This provides causal evidence that LLMs internally reason about harmfulness independently from their refusal behaviors.
Fine-Grained Categorical Representation of Harmfulness
The research extends the analysis to explore whether LLMs possess a fine-grained understanding of different risk types. By examining the harmfulness directions across various risk categories (e.g., "Illegal_activities," "Physical_harm"), the authors find that these directions vary significantly, while the refusal directions remain more similar across categories (Figure 4).
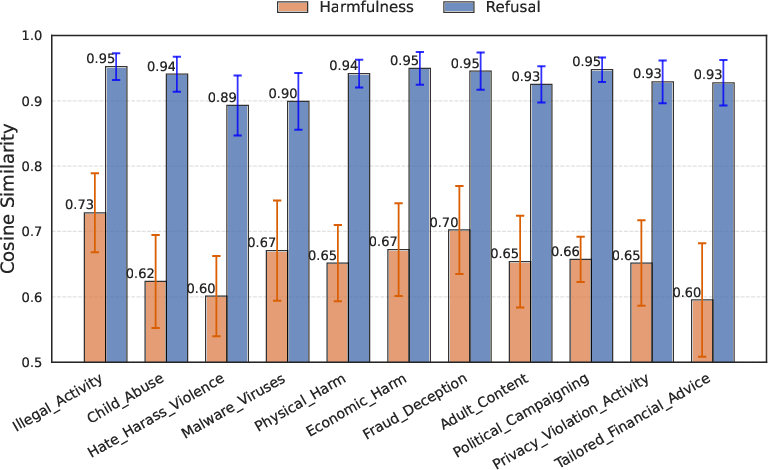
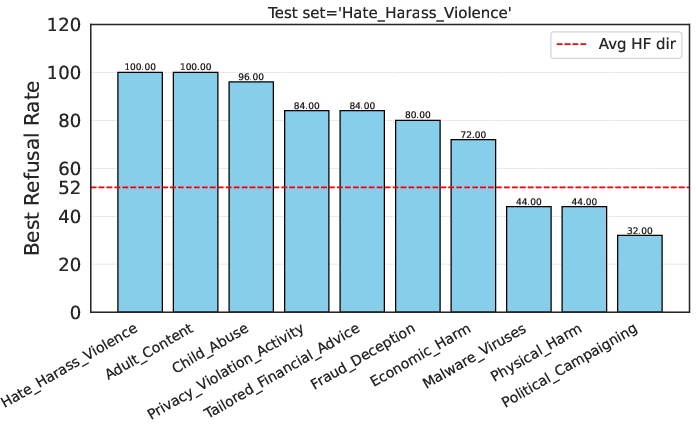
Figure 4: . Different token positions where we extract hidden states for comparison experiments on Llama2.
This suggests that LLMs have a more nuanced internal representation of different types of harmfulness than is reflected in their general refusal responses.
Implications for Jailbreak Analysis and Latent Guard Development
The identified harmfulness representation is then applied to analyze how jailbreak methods work. It is found that certain jailbreak techniques suppress refusal signals without fully reversing the LLM's internal belief of harmfulness. Based on this insight, the authors propose a Latent Guard model that uses LLMs' intrinsic harmfulness representation to safeguard against unsafe inputs. This Latent Guard achieves performance comparable to or better than a dedicated finetuned Llama Guard model, demonstrating the practical utility of the decoupled harmfulness representation.
Analyzing Jailbreak via Harmfulness
Different jailbreak methods have successfully enabled harmful instructions to be accepted by LLMs. Some jailbreak methods work by suppressing the refusal signal but cannot fundamentally reverse the model's belief of harmfulness.
Developing a Latent Guard Model with Harmfulness Representations
Guardrails for LLMs have been widely employed to improve safety, where users' input instructions are screened by a guard model. The Latent Guard model is effective and computationally efficient. For an incoming instruction, the Latent Guard model computes the belief of harmfulness.
Conclusion
The paper successfully decouples the representations of harmfulness and refusal in LLMs, revealing a new dimension for understanding their safety mechanisms. The harmfulness dimension serves as a lens into what LLMs internally believe beyond surface-level behaviors. This work has significant implications for AI safety, offering a path toward more robust and reliable safeguards against harmful content generation and adversarial attacks. Future research could explore the evolution of harmfulness representations during LLM training and develop more precise finetuning strategies that directly engage with these latent representations.