An Embarrassingly Simple Defense Against LLM Abliteration Attacks
Published 25 May 2025 in cs.CL, cs.AI, and cs.LG | (2505.19056v2)
Abstract: LLMs are typically aligned to refuse harmful instructions through safety fine-tuning. A recent attack, termed abliteration, identifies and suppresses the single latent direction most responsible for refusal behavior, thereby enabling models to generate harmful content. We propose a defense that fundamentally alters how models express refusal. We construct an extended-refusal dataset in which responses to harmful prompts provide detailed justifications before refusing, distributing the refusal signal across multiple token positions. Fine-tuning Llama-2-7B-Chat and Qwen2.5-Instruct (1.5B and 3B parameters) on this dataset yields models that maintain high refusal rates under abliteration: refusal rates drop by at most 10%, compared to 70-80% drops in baseline models. Comprehensive evaluations of safety and utility demonstrate that extended-refusal fine-tuning effectively neutralizes abliteration attacks while preserving general model performance and enhancing robustness across multiple alignment scenarios.
The paper introduces an extended-refusal dataset that disperses refusal signals to mitigate LLM safety vulnerabilities.
Experiments reveal that extended-refusal fine-tuning reduces refusal rate drops to only 10% compared to 70-80% in baseline models.
Feature space analyses demonstrate that distributed refusal representations maintain robust safety alignment even after abliteration attacks.
An Embarrassingly Simple Defense Against LLM Abliteration Attacks
Introduction
The paper "An Embarrassingly Simple Defense Against LLM Abliteration Attacks" (2505.19056) addresses the vulnerabilities inherent in LLMs, particularly concerning their alignment to refuse harmful instructions. LLMs often undergo supervised fine-tuning (SFT) or reinforcement learning from human feedback (RLHF) to establish these safety measures. However, recent developments have exposed an attack known as refusal direction abliteration, which efficiently neutralizes these safety protocols by suppressing specific neural pathways responsible for refusal behavior. This attack significantly compromises the safety of LLMs without affecting their general utility.
The paper hypothesizes that the vulnerability arises due to the concise, formulaic nature of refusal responses, which results in a concentrated activation signature easily targeted and neutralized by abliteration. To address this, the authors propose a novel defense mechanism involving the construction of an extended-refusal dataset. This dataset pairs harmful prompts with comprehensive responses that include neutral topic overviews, explicit refusals, and ethical justifications, thereby distributing the refusal signal across multiple dimensions in the representation space.
Figure 1: Base vs. Extended Refusal. Standard LLMs issue an immediate refusal without providing context or explanation. In contrast, the extended refusal first explains the nature of the request before refusing to assist with it.
Methodology
The proposed methodology involves fine-tuning several LLMs on the extended-refusal dataset. The models chosen for this study are Llama-2-7B-Chat and two versions of Qwen2.5-Instruct, comprising 1.5B and 3B parameters. This fine-tuning aims to disperse the refusal signal across multiple token positions, thus enhancing the robustness of these models against direction-based safety attacks.
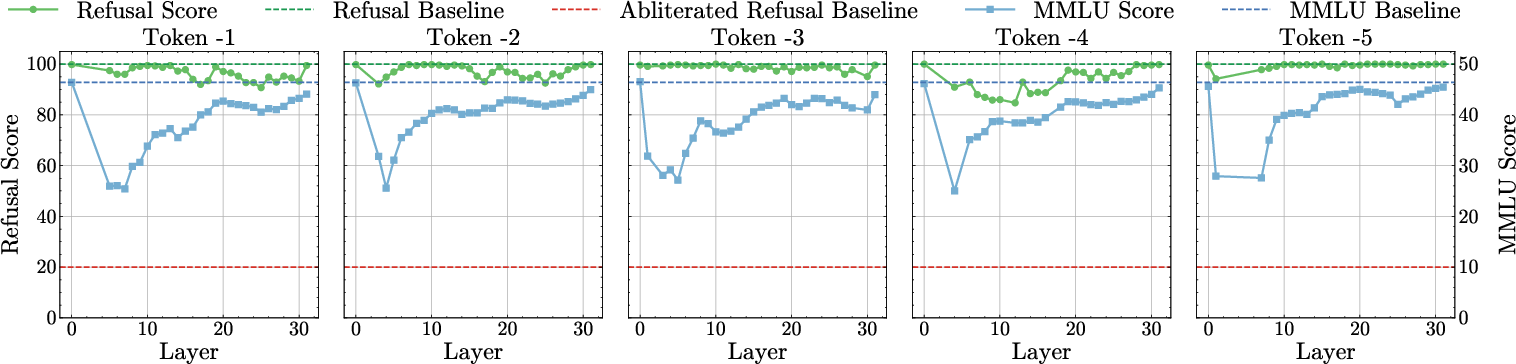
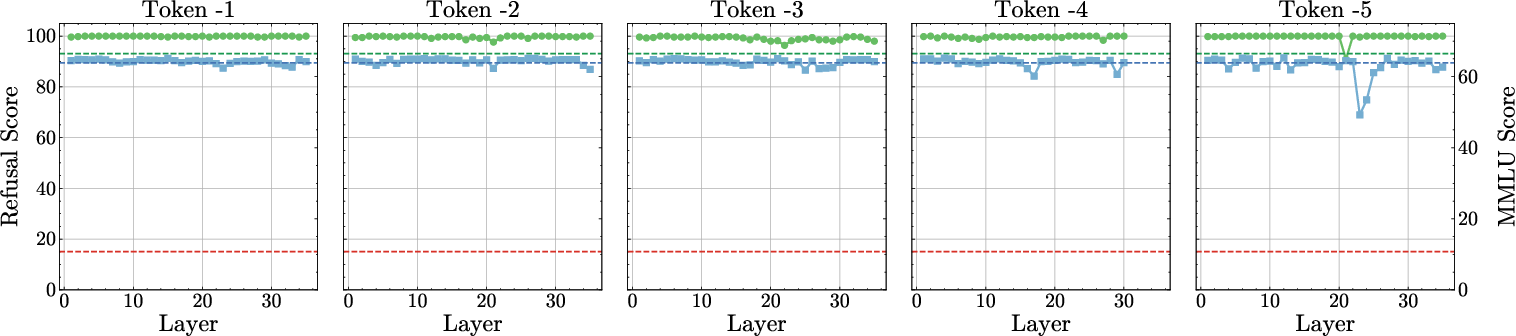
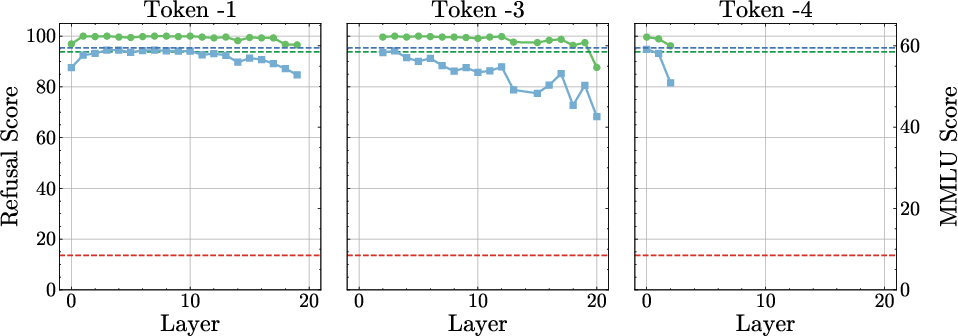
The approach is validated by subjecting the fine-tuned models to abliteration attacks. Unlike baseline models, which show refusal rate drops of 70-80%, the extended-refusal models exhibit a maximum refusal rate drop of only 10%. This indicates a significant enhancement in alignment robustness across multiple model architectures and sizes.
Experimental Results
Comprehensive evaluations were conducted to assess both safety and utility of the extended-refusal models. The experiments demonstrated that these models effectively neutralize abliteration attacks while preserving general model performance and enhancing robustness across various alignment scenarios. In terms of empirical data, extended-refusal variants maintained refusal rates above 90% post-abliteration, compared to dramatic drops in baseline models.
The extended-refusal approach led to minimal impact on general model performance, suggesting that modifying refusal expression does not severely alter the model's utility in benign tasks.
Figure 2: Refusal–Utility Trade-off. Refusal and MMLU scores for each model M after abliteration, indicating enhanced alignment robustness.
Feature Space Analysis
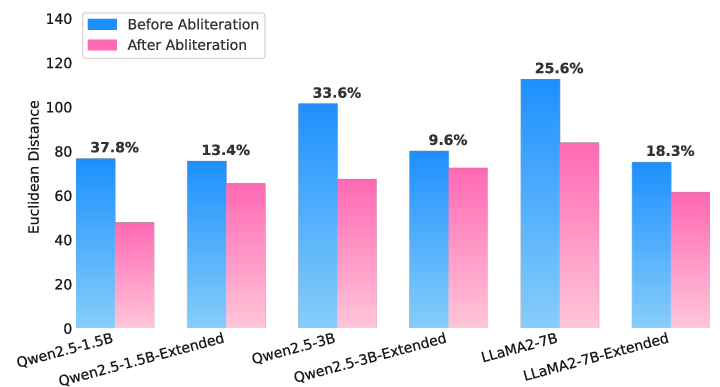
Feature space analysis revealed that extended-refusal models maintain distinct representations of harmful versus benign prompts even after abliteration. This preservation of separation in the representation space explains the sustained refusal capabilities, preventing the collapse of distinctions between content categories. The more distributed refusal representations hinder effective alignment breach by attacks, thereby maintaining safety integrity.
Figure 3: Latent-Space Separation. Euclidean distance between hidden representations of safe and unsafe prompts, before and after abliteration.
Additional Alignment Concerns
Extended-refusal models showed consistent reductions in vulnerability to various jailbreak attacks and alignment challenges, such as role-playing and prompt-injection attacks. Improvements extended to both simplistic safety concerns and more sophisticated adversarial settings, indicating the applicability of this defense mechanism beyond initial expectations.
Figure 4: Prompt-Injection Recovery: An Example From TrustLLM. Demonstrates recovery from a prompt-injection attack, showing superior alignment resilience.
Conclusion
The paper provides compelling evidence that extended-refusal fine-tuning constitutes a practical defense against direction-based safety attacks on LLMs. By distributing refusal signals across multiple latent dimensions, these models demonstrate improved robustness and integrity concerning safety alignment. The approach offers insights into integrating safety expressions within neural network representations, emphasizing the critical role of refusal behavior in safeguarding LLMs.
While showing promise, further research may explore generalized applicability to larger models and investigate the balance between verbosity and user experience in refusal responses. The findings underscore that the form of safety expression is a crucial mechanism of alignment, offering a path forward for developing more resilient AI systems.