- The paper demonstrates that probabilistic ablation of refusal directions can reduce jailbreak attack success rates from 92% to nearly zero.
- It leverages layer-wise and token-wise activation ablation to simulate compromised states, surpassing traditional surface-level safety alignment.
- Experimental results across various LLMs show robust defense improvements with minimal performance degradation.
"Beyond Surface Alignment: Rebuilding LLMs Safety Mechanism via Probabilistically Ablating Refusal Direction"
Introduction
The paper "Beyond Surface Alignment: Rebuilding LLMs Safety Mechanism via Probabilistically Ablating Refusal Direction" addresses the vulnerabilities faced by LLMs against jailbreak attacks, which pose substantial risks to model safety. Traditional safety alignment methods have been identified as insufficient in depth and robustness, primarily focusing on surface-level defenses that fail against refined adversarial inputs such as prefilling or manipulation at the refusal direction level. This paper introduces DeepRefusal, an innovative framework leveraging representation space manipulation to enhance LLM robustness against such attacks. DeepRefusal employs probabilistic ablation of the refusal direction across layers and token sequences during fine-tuning, compelling the model to reconstruct its refusal mechanisms from compromised states.
LLMs are susceptible to adversarial jailbreak attacks, which exploit weaknesses in their safety mechanisms to elicit inappropriate responses. To combat this, several safety alignment strategies have been proposed, notably CircuitBreaker, which suppresses harmful activations but faces limitations against the sophistication of token depth or refusal manipulation attacks (Figure 1).
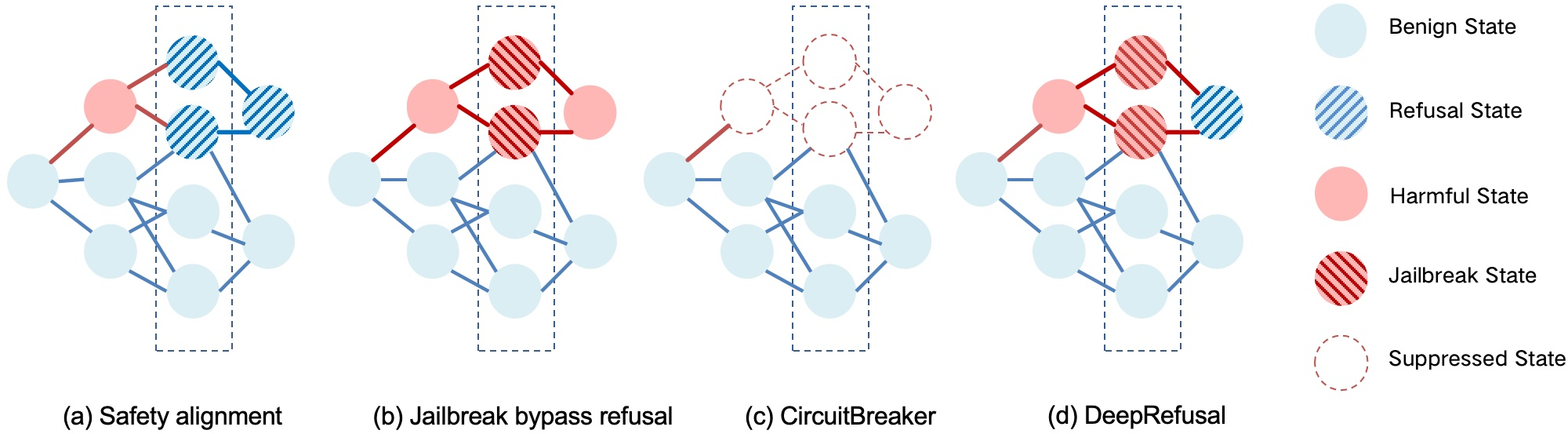
Figure 1: Conceptual diagram of jailbreak and safety mechanisms at the representation level: (a) Safety alignment prevents the model from answering harmful requests by activating the concept of refusal. (b) Jailbreak attacks bypass the refusal behavior of the model through carefully designed prompts. (c) CircuitBreaker suppresses harmfulness within the hidden states (still vulnerable to attacks targeting token depth or internal refusal mechanisms). (d) DeepRefusal simulates jailbreak scenarios, forcing the model to reactivate refusal behaviors, enhancing robustness.
Technical Methodology
The DeepRefusal framework proposes a methodology where adversarial pressure is introduced within the model's representation space—a more sophisticated layer than traditional surface-level fine-tuning. This is accomplished through layer-wise and token-wise Probabilistic Activation Ablation (PAA). The refusal direction is defined as an internal vector strongly correlated with refusal response production. By selectively removing activation patterns associated with this direction across the model's layers and token depths, DeepRefusal simulates extreme jailbreak conditions internally (Figure 2).
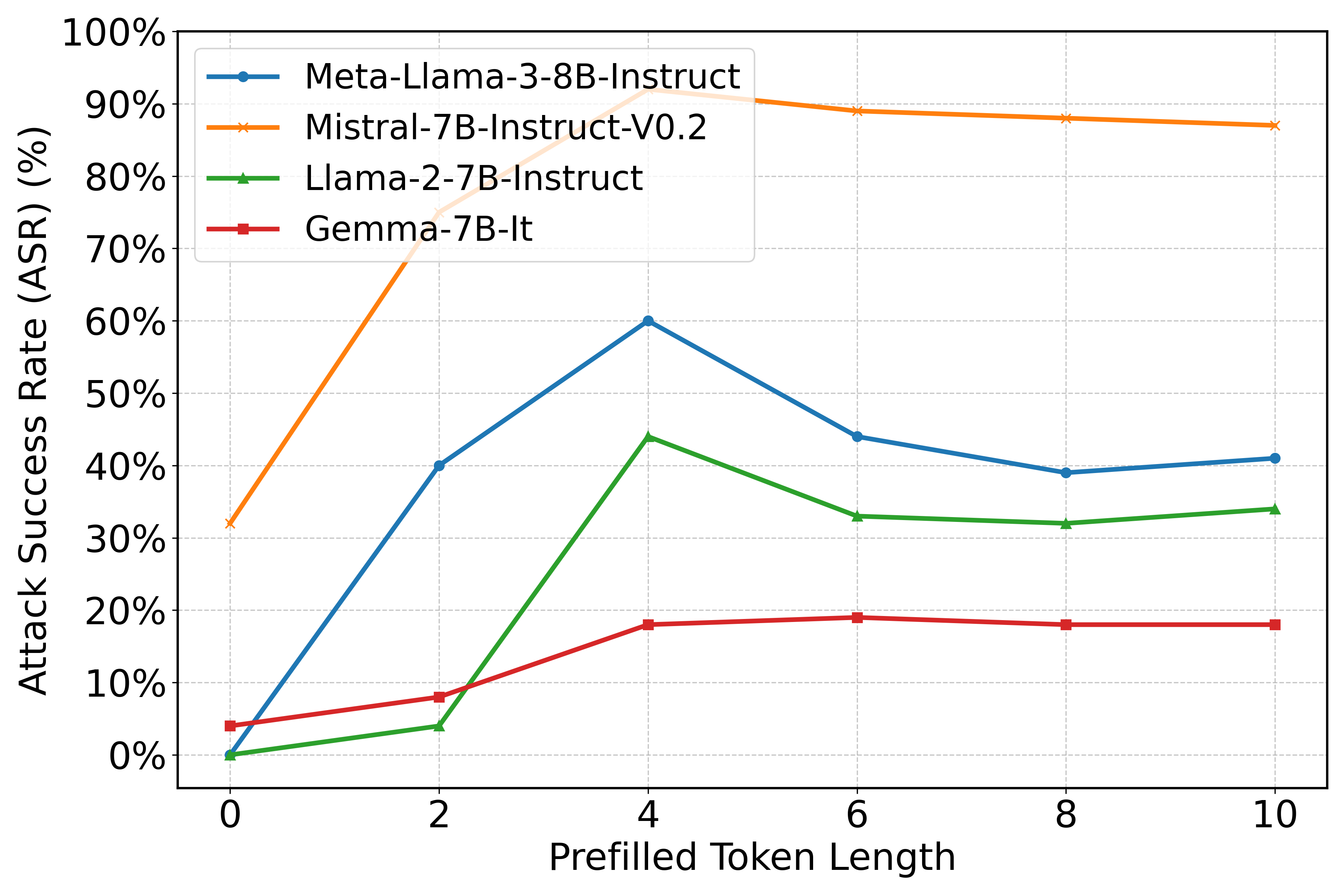
Figure 2: Attack success rate with different lengths of harmful tokens prefilled.
The refusal direction manipulation aims to address significant gaps observed in traditional safety alignment methods. Existing strategies often align only the initial tokens in a response, overlooking subsequent harmful content, which is exploited by attacks such as prefilling. Statistical analysis in the paper shows how this vulnerability increases attack success rates with the increasing length of prefilled harmful tokens.
Additionally, DeepRefusal leverages insights from Representation Engineering, particularly focusing on manipulating the internal representations within LLMs to simulate worst-case jailbreak scenarios and rebuild the safety mechanisms effectively. This internal intervention strategy enhances alignment robustness substantially, reducing the attack success rate by approximately 95% across various models and attack types (Figure 3).
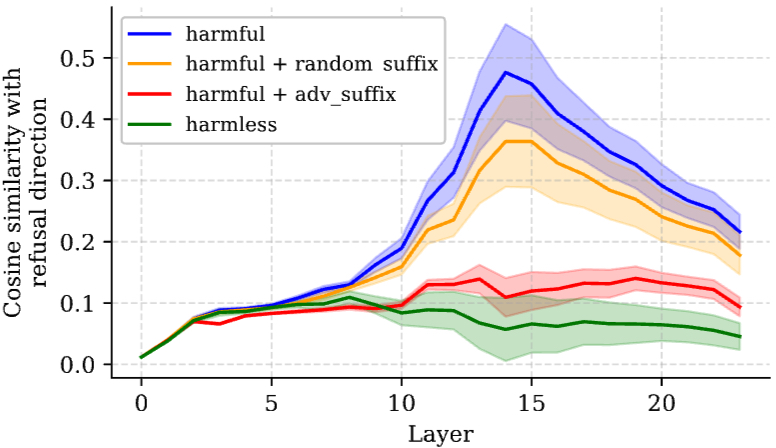
Figure 3: Cosine similarity between the residual stream activation of the last token and refusal direction.
Experimental Results
The paper’s extensive experimentation across multiple LLM families and attack types demonstrates DeepRefusal's efficacy. Evaluations reveal significant improvement in robustness, with attack success rates dropping dramatically while maintaining model capabilities with minimal performance degradation. For instance, DeepRefusal reduces the attack success rate from nearly 92% to almost zero, positioning it as a superior safety alignment method. The model’s ability to withstand attacks targeting refusal directions and prefilling indicates its enhanced depth of defense compared to previous frameworks.
Implications and Future Directions
Theoretical implications of this research are profound, emphasizing the shift from surface-level techniques to representation-level interventions for LLM safety. Practically, the framework offers a robust approach to safeguarding LLMs against sophisticated adversarial attacks without compromising their performance on benign queries. Future research could explore extending the DeepRefusal method beyond language domains to multimodal models, where alignment challenges are even more intricate.
The paper suggests further potential in refining representation engineering techniques to enhance AI system transparency and resilience against unforeseen attack vectors. Particularly, expanding the database of adversarial patterns and refining the refusal direction heuristics could lead to even more resilient architectural designs in LLMs and other AI systems.
Conclusion
"Beyond Surface Alignment: Rebuilding LLMs Safety Mechanism via Probabilistically Ablating Refusal Direction" marks a significant advancement in the field of AI safety. By focusing on deep alignment mechanisms through probabilistic refusal direction ablation, this innovative approach offers a transformative solution to address vulnerabilities in LLMs, ensuring more rigorous safety standards across AI applications. Future explorations in this field could pave the way for universally applicable safety alignment practices, extending beyond the confines of natural language processing to encompass broader AI contexts.

