- The paper introduces a two-stage framework where a Transformer-based static network predicts draped hair shapes and a dynamic network simulates motion.
- It leverages cross-attention mechanisms and GRU enhancements to minimize hair-body penetrations and preserve strand length under varied poses.
- The method enables real-time, robust dynamic hair simulation, setting a new benchmark for digital character and animation realism.
Introduction to Hair Dynamics Simulation
Modeling and simulating realistic 3D hair dynamics remains a significant challenge in creating digital humans for applications such as visual effects and virtual reality. Traditional methods often struggle with the complexities of simulating arbitrary hairstyles under varied poses and shapes, leading to a lack of realism and limited expressiveness. Addressing these challenges, the paper introduces HairFormer, a Transformer-based approach for simulating dynamic neural hair across diverse head and body configurations.
The HairFormer model innovates through a two-stage simulation technique. It leverages a static network to predict the draped form of hair and a dynamic network to simulate expressive motion. This approach permits the simulation of complex secondary motions and facilitates real-time inference while resolving common issues such as hair-body penetrations.
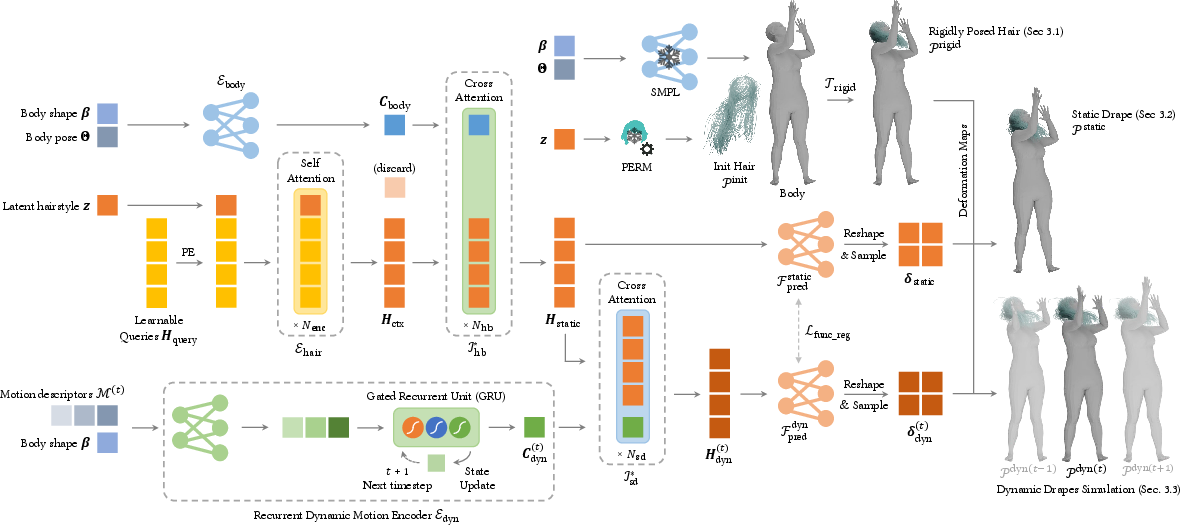
Figure 1: Method Overview. Our network architecture features distinct static and dynamic modules. (Top right) Initially, hair strands are generated from hairstyle latent code using a StyleGAN-based model.
Methodology
Static Hair Simulation
The first stage employs a Transformer-based static network to establish a stable and physically plausible hair configuration. By processing hair latent codes in tandem with body shape and pose parameters, the system correctly predicts static draped shapes. It resolves common simulation problems such as hair-body penetrations via an extended barrier function derived from codimensional incremental potential contact (IPC).
The model's architecture includes a hair encoder and a body encoder, which fuse informations of hair latent codes and body parameters through cross-attention mechanisms. This architecture ensures robust handling of arbitrary hairstyles, providing a foundation for subsequent dynamic hair simulation.
Dynamic Hair Network
The second stage enhances realism by predicting dynamic responses to body movements. The dynamic network uses a sequence of body poses and integrates them with the static prediction through another Transformer-based cross-attention block. This design captures intricate hair dynamics, including "flying" hair and the follow-through in abrupt head motions, facilitated by a GRU-enhanced dynamic feature.
A notable feature is the introduction of an inertia loss function, which maintains physically plausible motions across the sequence, preserving coherence with real-world phenomena.
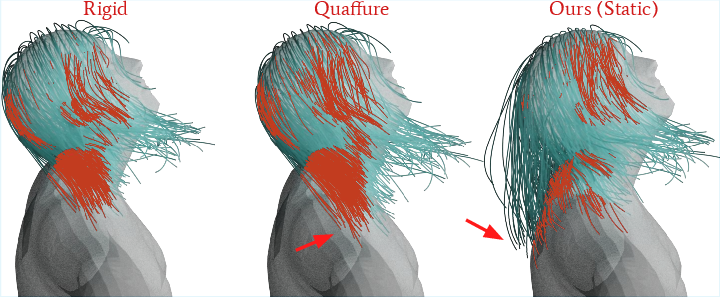
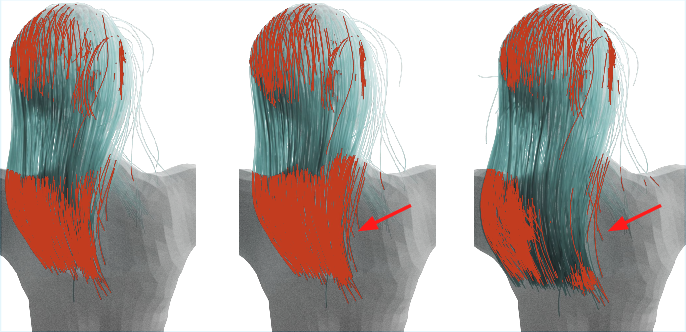

Figure 3: Extrapolated barrier function of various orders.
Results and Evaluation
Extensive experiments confirm the efficacy of HairFormer in comparison to both adapted existing models like Quaffure and optimization-based approaches. The model consistently exhibits lower penetration rates and better length preservation of hair strands, showcasing its advantage in producing realistic and expressive results for unseen hairstyles.
An ablation study further highlights the significance of the network's functional components, such as the effective feature fusion via cross-attention mechanisms, in maintaining detailed hair dynamics.

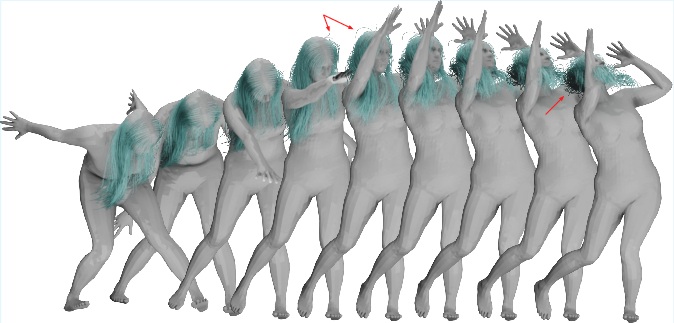
Figure 5: Top: Static per-frame inference. Bottom: Dynamic inference for entire sequence. Red arrows indicate regions with significant differences.
Implications and Future Work
HairFormer sets a new standard for realistic hair simulation, integrating advanced network architectures to capture rich hair dynamics and broader animation possibilities. This has significant implications for character design in interactive and animated contexts, where realism and expressiveness are valued.
Future development may focus on expanding user-defined physical parameters to enhance the flexibility of the simulation. Additionally, improvements in handling complex penetrations and precise modeling of high-frequency dynamic components like hair twist are anticipated. Enhanced data diversity for training could also ensure even more robust results across varied animations and user scenarios.
Conclusion
The HairFormer model represents a noteworthy advance in dynamic hair simulation, addressing critical challenges with a novel application of Transformer-based neural networks. Its effectiveness across a range of unseen configurations and its potential for real-time application mark it as a valuable tool in digital media production. Further enhancement and integration will continue to widen its applicability and impact in the field.