- The paper establishes inverse reinforcement learning as a framework for LLM post-training and alignment using neural reward models derived from human preferences.
- It details various IRL methods including behavior cloning, adversarial imitation, and reward-guided decoding, emphasizing their trade-offs and practical implications.
- The paper also highlights risks like reward overoptimization and data bottlenecks, offering insights for mitigating these challenges in future research.
Inverse Reinforcement Learning for LLM Post-Training: Foundations, Algorithms, and Alignment Opportunities
Introduction
This paper presents a comprehensive synthesis of inverse reinforcement learning (IRL) as a paradigm for post-training and alignment of LLMs. It formalizes the connection between RL, IRL, and LLM optimization, emphasizing the necessity of neural reward models for scalable, generalizable, and controllable LLM behavior. The work systematically reviews foundational RL concepts, characterizes LLM generation as an MDP, and surveys practical IRL algorithms, with a focus on reward modeling from human feedback, mathematical reasoning, and demonstration datasets. The paper also addresses critical challenges such as reward overoptimization and data-centric bottlenecks, and speculates on future research directions in LLM alignment.
RL and IRL Foundations in the Context of LLMs
The paper begins by revisiting the classical RL framework, formalizing LLM token generation as a Markov Decision Process (MDP) with a deterministic transition function and a data-driven reward function. Unlike conventional RL tasks, LLMs lack explicit, rule-based reward signals, necessitating the construction of neural reward models from human data. The authors highlight that there is no universally optimal RL algorithm; the choice of method must be tailored to the properties of the environment, including state/action space, reward sparsity, and resource constraints.
Imitation learning (IL) and IRL are presented as two principal approaches for learning from behavioral datasets in MDPs without explicit rewards. IL, exemplified by behavior cloning (BC), suffers from compounding errors due to distributional shift, which can be mitigated by access to environment dynamics (e.g., via DAgger). Adversarial imitation learning (AIL) methods, such as GAIL and AIRL, are unified under f-divergence minimization, with different choices of divergence yielding distinct practical algorithms. The distinction between IL and IRL is made explicit: IL directly matches expert behavior, while IRL infers a reward model whose maximization induces the expert policy.
Why Neural Reward Models Are Essential for LLM Alignment
The authors argue that pre-training and supervised fine-tuning (SFT) of LLMs are fundamentally forms of behavior cloning, limited by the quality and diversity of demonstration data. They identify three key motivations for explicit reward modeling in LLM alignment:
- Scalable Learning from Human Preferences: Preference data is more practical and scalable than demonstration data, as annotators are better at discriminative tasks (e.g., pairwise ranking) than generative ones. RLHF pipelines leverage preference-based reward models for efficient supervision.
- Generalization in Mathematical Reasoning: SFT on demonstration datasets fails to induce generalizable reasoning patterns. Reward models enable LLMs to discover high-reward reasoning trajectories, supporting behaviors such as deep thinking and self-correction.
- Inference-Time Optimization: Reward models uniquely enable test-time optimization, allowing for adaptive selection and filtering of high-quality responses during deployment, analogous to planning in classical RL tasks.
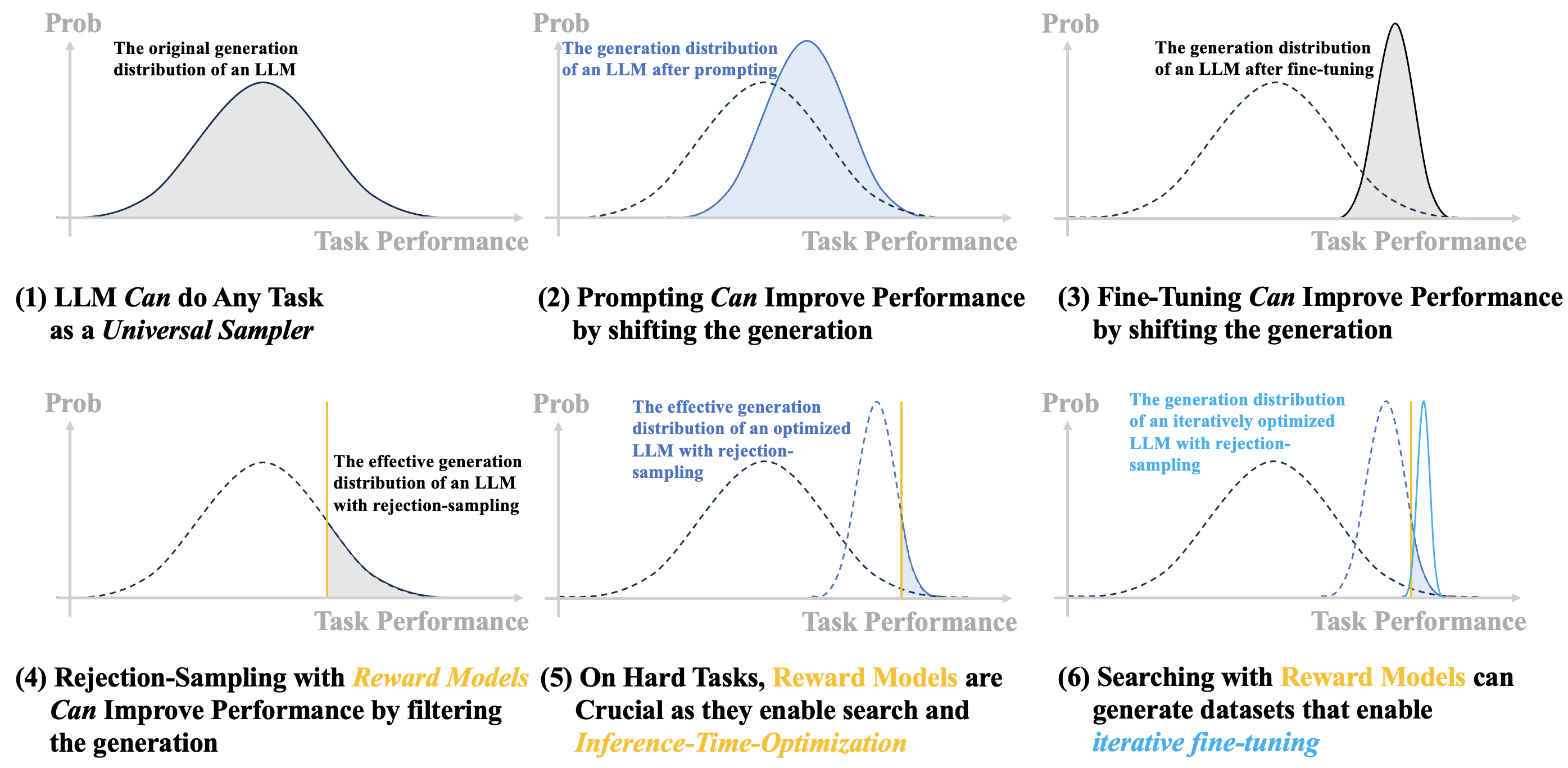
Figure 1: A comparison of LLM generation optimization approaches, highlighting the unique role of reward models in enabling inference-time optimization.
Practical IRL via Reward Modeling: Algorithms and Data Modalities
Preference-Based Reward Modeling
RLHF is formalized as IRL, with reward models trained via Bradley-Terry (BT) regression on pairwise preference data. Direct Preference Optimization (DPO) is presented as a robust alternative, directly optimizing policy log-probabilities to match observed preferences, avoiding explicit reward modeling. Theoretical analysis justifies BT regression over classical BT estimation, and order consistency is identified as a critical property for preference-based objectives. Classification-based objectives can outperform BT models under annotation noise.
Active learning is discussed as a principled approach for efficient preference annotation, with Fisher information and optimal experimental design guiding query selection. The exploration–exploitation trade-off is formalized in the embedding space, aligning with the structure of modern reward models.
Modeling Preference Diversity
The paper reviews methods for personalized and distributional reward modeling, including user-specific latent variables, reward distributions, and MaxMin objectives. Decomposed Reward Models (DRMs) leverage PCA in the embedding space to capture diverse human preferences as orthogonal basis vectors, yielding interpretable and attribute-specialized reward heads.
Mathematical Reasoning and Prompt Optimization
The evolution of LLM-based mathematical reasoning is traced from prompt optimization (e.g., CoT, ToT) to RL with verifiable rewards (RLVR). The authors note that RLVR often induces structured, template-based responses rather than fundamentally new reasoning strategies. Prompt-OIRL is introduced as an IRL-based method for offline prompt optimization, reusing historical trial-and-error data to train reward models for adaptive prompt selection.
Demonstration-Based Reward Modeling
Alignment from Demonstration (AfD) is formalized via occupancy matching and divergence minimization. SFT corresponds to forward KL minimization, while adversarial imitation aligns with reverse KL. Both are special cases of a general IRL framework, enabling richer supervision beyond preference data.
Policy Optimization with Reward Models
The paper surveys methods for optimizing LLM outputs using reward models:
- Best-of-N Sampling: Simple, effective, but computationally expensive; serves as a reliable evaluation metric for reward models.
- Iterative Fine-Tuning: Parameterizes BoN via supervised fine-tuning on reward-selected outputs, achieving strong performance without RL instability.
- PPO and Monte-Carlo Methods: PPO is widely used but sensitive to hyperparameters and reward sparsity. Monte-Carlo methods (REINFORCE, GRPO, DAPO) directly optimize expected returns using trajectory-level feedback, offering stability and efficiency.
- Reward-Guided Decoding: Enables inference-time optimization by reweighting token probabilities based on reward feedback, supporting personalized and controllable generation.
Risks, Challenges, and Opportunities
Reward Overoptimization
Reward models are susceptible to overfitting and reward hacking, as per Goodhart’s Law. Overoptimization is quantified by the gap between optimized and reference reward model scores.
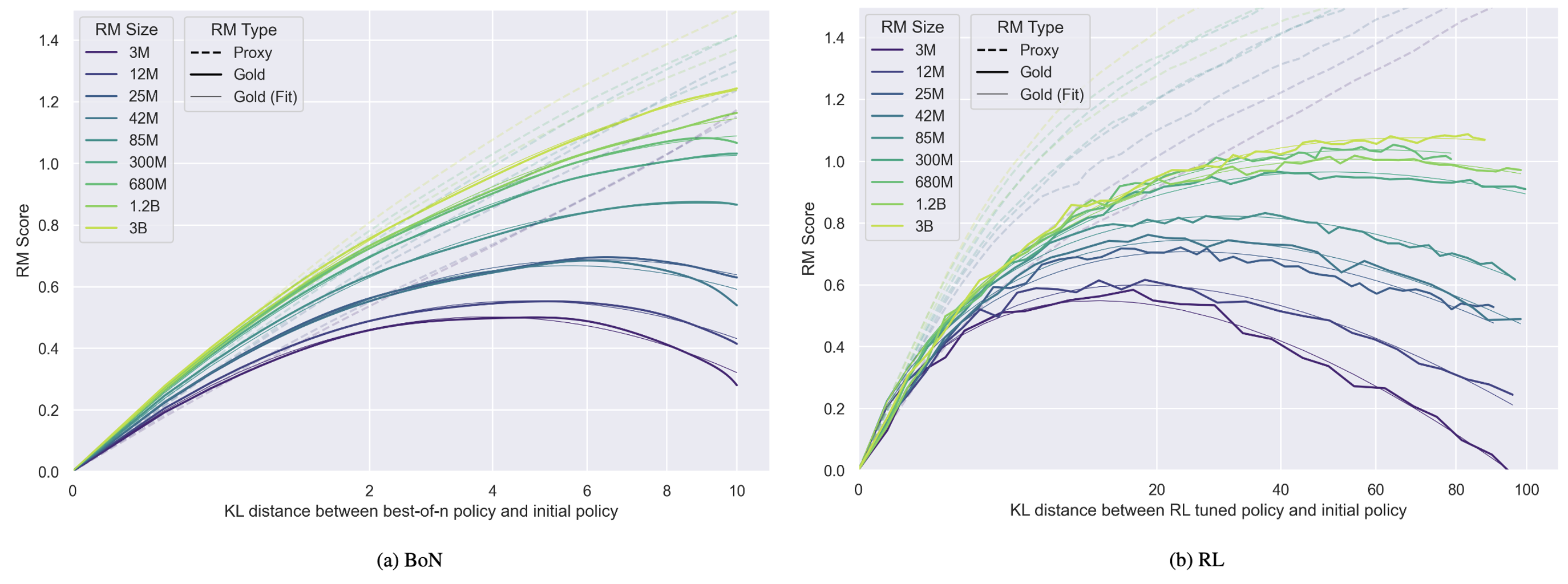
Figure 2: Reward model overoptimization, illustrating the divergence between optimized and held-out reward model scores as a function of policy optimization.
Mitigation strategies include uncertainty estimation (ensembles), regularization via generative objectives, and causal analysis of model behavior. Length bias and contextual artifacts are identified as sources of misalignment.
Data-Centric Bottlenecks
Off-policy data introduces distribution mismatch, degrading reward model and policy performance. Data quality is prioritized over quantity, and online/active learning is advocated for efficient annotation. Bridging offline supervision and on-policy learning remains a central challenge.
Conclusion
This paper establishes IRL as a principled and practical framework for LLM post-training and alignment, unifying RLHF, demonstration learning, and prompt optimization under reward modeling. The necessity of neural reward models is justified by their scalability, generalization, and support for inference-time optimization. The work highlights algorithmic advances, data-centric challenges, and the risks of reward overoptimization, providing a roadmap for future research in LLM alignment. Theoretical insights into divergence minimization, order consistency, and preference diversity inform the design of robust, interpretable, and personalized reward models. Future developments are likely to focus on bridging offline and online data modalities, mitigating overoptimization, and leveraging LLMs’ reasoning capabilities for more reliable and controllable AI systems.