- The paper presents the novel Mean Absolute Directional Loss (MADL) function that aligns model training with directional accuracy in financial forecasting.
- It employs a rigorous walk-forward methodology to compare transformer and LSTM models using daily data across multiple financial asset classes.
- Results reveal that transformer models optimized with MADL achieve higher risk-adjusted returns in both equity and cryptocurrency markets.
Introduction
The paper "Alternative Loss Function in Evaluation of Transformer Models" (2507.16548) introduces the Mean Absolute Directional Loss (MADL) function for evaluating the performance of machine learning models, particularly in the context of quantitative finance. The research evaluates and compares the efficacy of Transformer and LSTM models in generating trading signals for both equity and cryptocurrency markets. The study adopts a rigorous walk-forward methodology over extended out-of-sample periods, contributing valuable insights into algorithmic investment strategies.
Theoretical Foundations
The Transformer model, characterized by its self-attention mechanism and parallelizable architecture, offers advantages in handling sequential data efficiently, which makes it a suitable candidate for time-series forecasting tasks. In contrast, LSTM models utilize a recursive structure with memory cells and gating mechanisms but suffer from limitations in scalability due to their sequential processing nature.
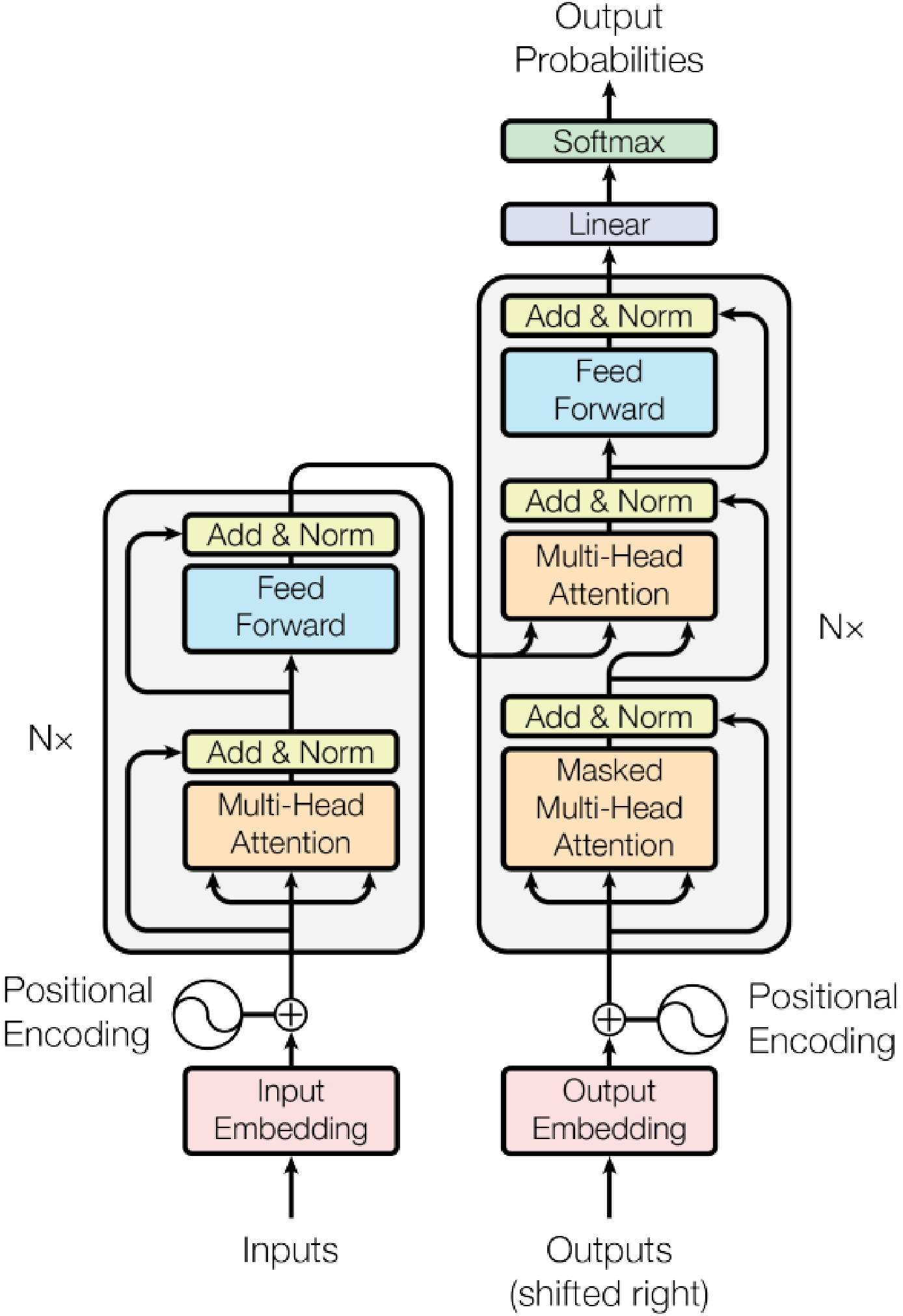
Figure 1: The structure of the Transformer model with special attention to input and output layers.
The MADL function specifically addresses challenges in selecting loss functions that align better with investment strategy objectives. By focusing on the directional accuracy of forecasts and accounting for the magnitude of errors, MADL optimizes model outputs for trading applications.
Methodology
The methodology centers on empirical testing of Transformer and LSTM models applied to six assets—JP Morgan, S&P 500, Exxon Mobil, Bitcoin, Ethereum, and Litecoin. Daily data spanning several years form the basis for training and evaluation. The study applies the MADL function in model optimization to identify long/short signals, employing a rolling walk-forward procedure to mitigate overfitting and ensure robustness.
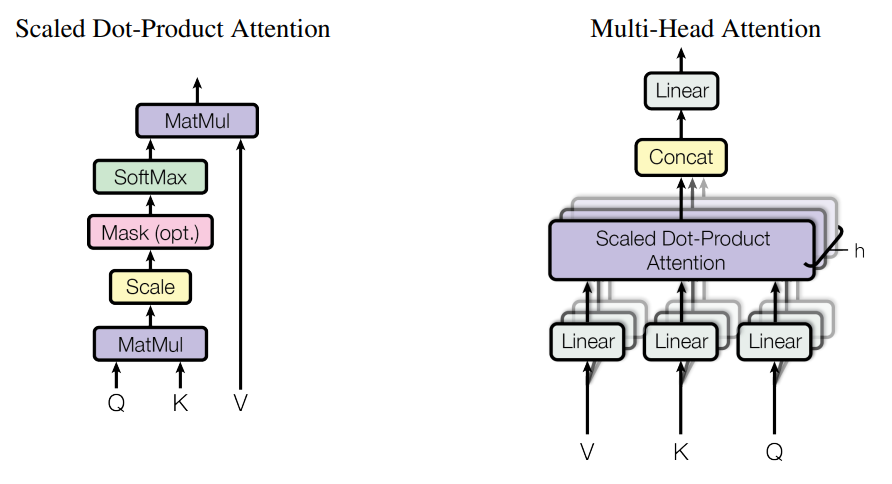
Figure 2: Transformer model with two different attention mechanisms: Scaled Dot-Product Attention and Multi-Head Attention.
Hyperparameters were carefully selected to ensure the models could effectively capture patterns in the time-series data. The Transformer model configuration consists of multi-head attention layers, crucial for capturing dependencies across input sequences and enhancing prediction accuracy.
Implementation and Experimentation
Training involved the use of the Adam optimizer with specified hyperparameters to facilitate convergence. The walk-forward validation strategy allows continuous adaptation of model parameters as new data becomes available, ensuring the models remain relevant over extended periods.
For LSTM models, the architecture integrated multiple layers with tanh activation functions, combined with dropout and L2 regularization to prevent overfitting. The training process included checkpoints to retain the most performant model parameters.
Results and Discussion
The evaluation results demonstrate a clear superiority of the Transformer models over LSTM models and standard Buy-and-Hold strategies. Transformer models achieved higher risk-adjusted returns, demonstrating robust signal generation for both equities and cryptocurrencies.
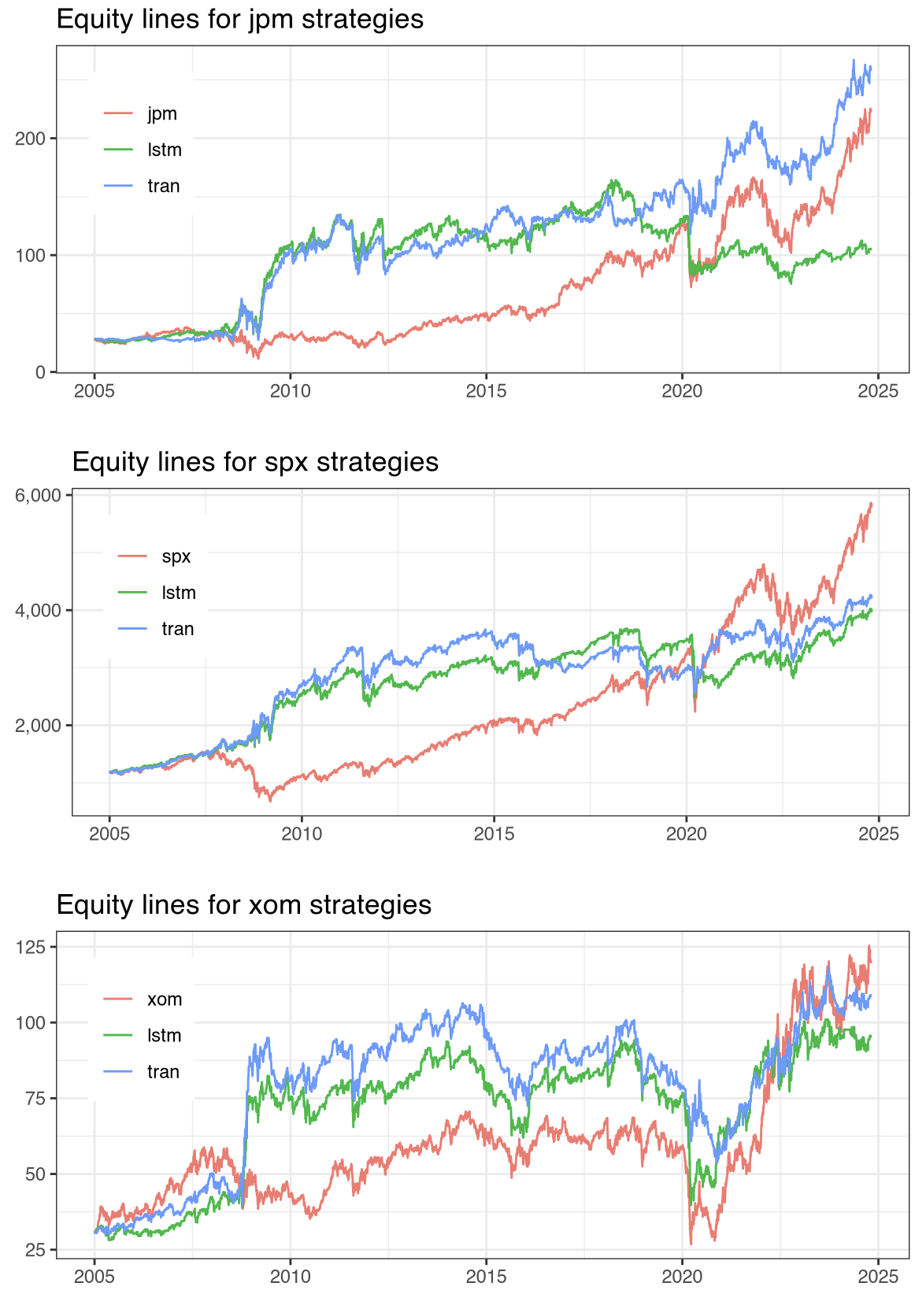
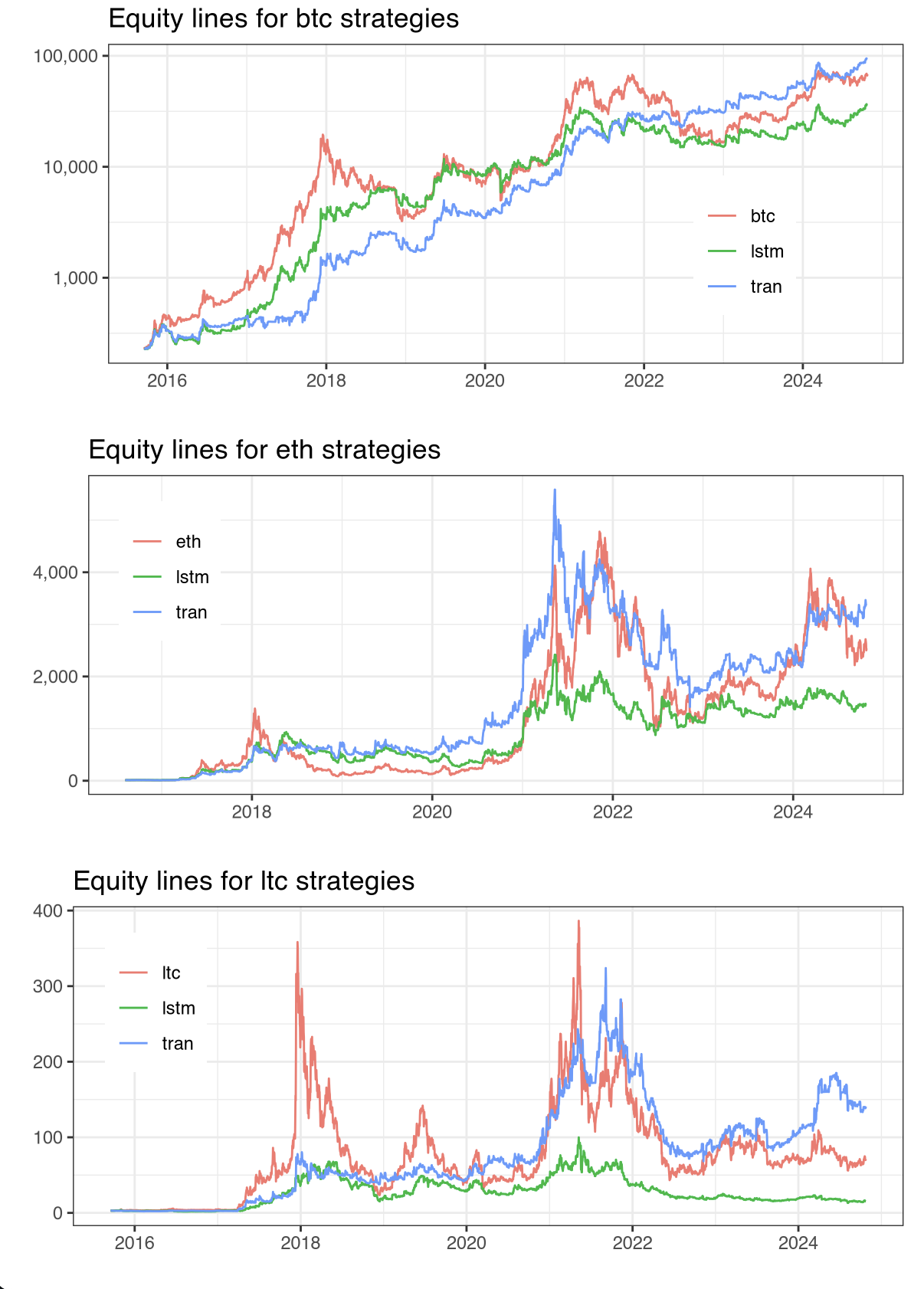
Figure 3: Equity lines for JPM, SPX, XOM, BTC, ETH, and LTC.
The risk-adjusted performance metrics, including Information Ratios (IR*, IR*, IR**), confirmed the expanded utility of the MADL function. Results indicate that Transformer models not only improve predictive accuracy but also enhance economic returns relative to LSTM counterparts.
Conclusions
The study contributes significantly to financial AI applications by demonstrating the methodological advantages of the MADL function and the practical efficacy of Transformer models. The findings underscore the importance of aligning machine learning objectives with financial outcomes, supporting more informed algorithmic trading decisions.
Future research should explore the generalizability of the MADL function across different machine learning models and finer asset classes. Enhancements to the differentiability of MADL, along with richer sensitivity analyses across broader datasets, could further refine model applicability.
The implications of these findings suggest potential for refined regulation and risk management standards in algorithmic trading domains, promoting transparency and robustness in model-based trading systems.