- The paper introduces DriftMoE, an online Mixture of Experts that uses a lightweight neural routing network combined with incremental Hoeffding tree experts for continuous adaptation to concept drift.
- It demonstrates state-of-the-art prequential accuracy on nine benchmarks, surpassing traditional ensembles with fewer experts and reduced computational overhead.
- Practical implications include efficient deployment on resource-constrained devices, although both expert variants face challenges under severe class imbalance.
DriftMoE: A Mixture of Experts for Online Concept Drift Adaptation
Introduction and Motivation
The DriftMoE architecture addresses the persistent challenge of learning in highly dynamic, non-stationary data streams characterized by concept drift—distributional changes in the underlying generative process over time. Existing ensemble approaches in data stream mining, such as Adaptive Random Forest (ARF), OzaBag, and Leveraging Bagging, rely heavily on explicit drift detection procedures, large pools of base learners, or coarse voting/weighting mechanisms. These approaches introduce latency, high resource consumption, or suboptimal expert specialization. DriftMoE re-frames adaptation within the Mixture of Experts (MoE) paradigm, implementing an online co-training regime between a neural router (gater) and a compact pool of incremental Hoeffding tree experts.
Architectural Design
DriftMoE consists of two principal components:
- Experts: Each expert is an incremental Hoeffding tree. Two modes are offered:
- MoE-Data: Each expert operates as a multi-class classifier, suitable for discovering latent regimes in the data stream.
- MoE-Task: Each expert specializes in a single class (one-vs-rest fashion), facilitating explicit class-wise specialization.
- Router (Neural Gating Network): A lightweight 3-layer MLP is trained to assign input samples to experts, either for soft weighted prediction or Top-k expert selection, using a symbiotic loss computed from the correctness of each expert's prediction.
The co-training mechanism operates as follows:
- On arrival of instance (xt,yt), the router computes gating weights across experts.
- For MoE-Data, only the Top-k experts (by gating probability) are updated; for MoE-Task, all task-specific experts are updated.
- The router is trained in small mini-batches via binary cross-entropy against a multi-hot correctness mask, providing positive reinforcement to all accurate experts. This mask is modified to avoid degenerate gradients (i.e., guarantees at least one positive per instance).
This tight feedback loop accelerates the mutual specialization: as the router better identifies expert strengths, experts receive more focused updates, enhancing specialization and adaptation.
Hyperparameter Sensitivity
Grid sweeps on the LED stream validate robustness to the number of experts (K) and top-k gating parameter:
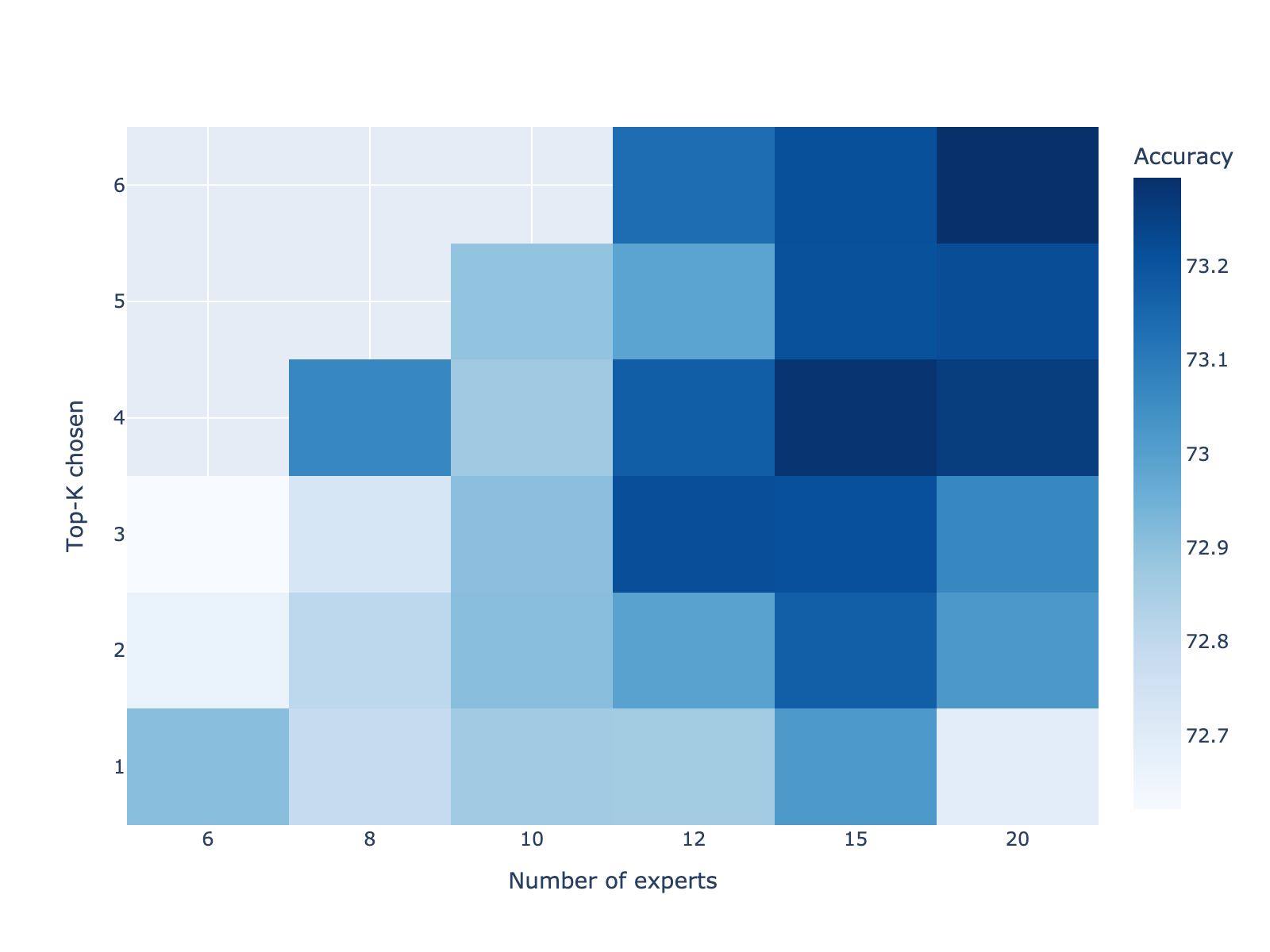
Figure 1: Prequential accuracy for the LED stream as a function of number of experts N and gating parameter Top-K; a broad plateau is observed at (N=12,Top−K=3), justifying the default configuration.
This configuration is shown to retain above 97% of peak accuracy while reducing computational requirements by approximately 30% relative to larger ensembles.
Empirical Evaluation
Evaluation is conducted on nine benchmarks: six standard synthetic streams (LED, SEA, RBF), covering abrupt and gradual drift scenarios, and three real-world datasets (Airlines, Electricity, CoverType). A stringent prequential (interleaved-test-then-train) protocol is applied, alongside metrics such as accuracy, Kappa-m, and Kappa-temporal.
The performance profile reveals:
- MoE-Data variant offers the best overall stability, particularly in AIRL, LED, and SEA streams.
- MoE-Task variant excels in highly nonstationary streams with frequent drift events (e.g., RBF), but is susceptible to performance collapse under heavy class imbalance (e.g., Electricity, CoverType).
Prequential accuracy over all nine datasets with baseline ensembles and both DriftMoE variants is depicted below:
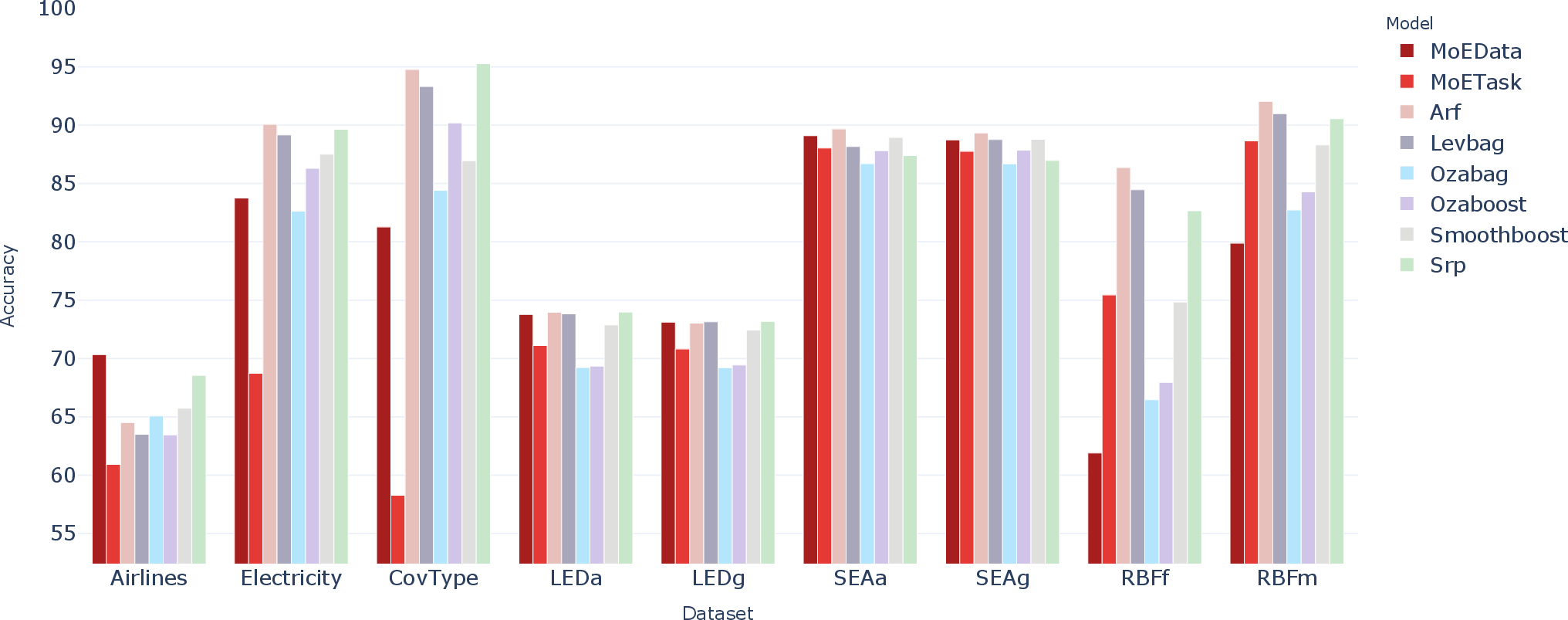
Figure 2: Prequential accuracy across nine data streams for baseline ensembles and DriftMoE variants. DriftMoE matches or surpasses heavyweight ensembles using an order of magnitude fewer base learners.
DriftMoE's tracking of abrupt/gradual drift is further illustrated by the accuracy trajectory over time for the LEDg dataset:
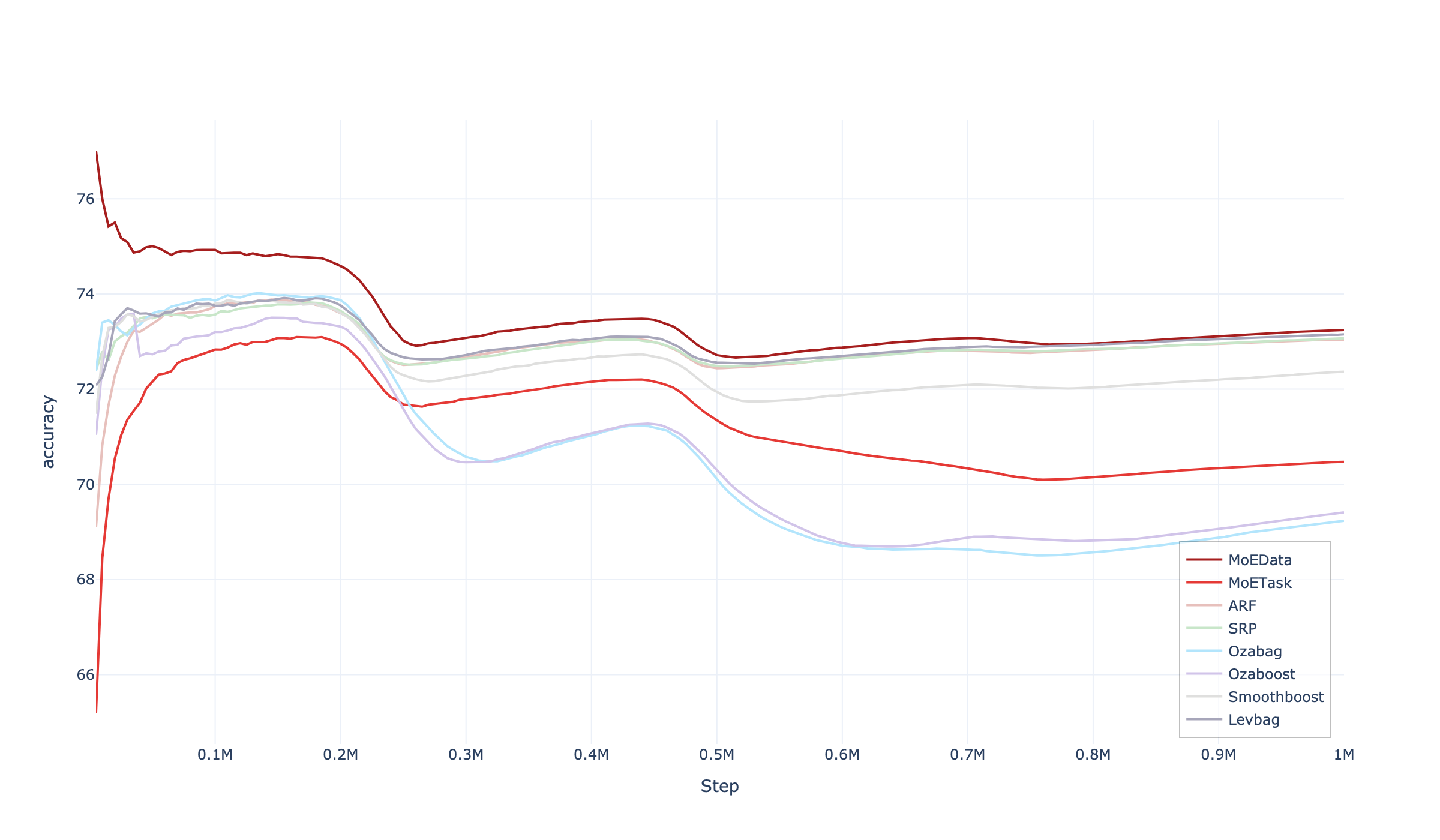
Figure 3: Prequential accuracy vs. time for the LEDg stream, showing DriftMoE's prompt recovery post-drift with minimal lag compared to ADWIN-based ensembles.
DriftMoE frequently matches or slightly surpasses heavyweight baselines (e.g., ARF with 100 trees, SRP, Leveraging Bagging) while using only 12 experts, providing higher efficiency with less overhead and lower latency.
Analysis and Implications
Key empirical findings:
- DriftMoE achieves state-of-the-art accuracy and recovery speed from distributional drift using a fraction of the resources compared to existing ensembles.
- The multi-hot router-expert feedback loop accelerates expert specialization and enables nuanced handling of both abrupt and gradual shifts.
- Unlike classic ensemble methods (e.g., those relying on explicit drift detectors and hard resets), DriftMoE achieves fine-grained, continuous adaptation without relying on brittle detection signals.
Limitations:
- Both MoE variants are susceptible to performance degradation under severe class imbalance, prompting a need for cost-sensitive gating or class-aware expert assignment.
- The task-based variant risks overspecialization and loss of coverage in minority/underrepresented classes.
Practical implications:
- DriftMoE's lightweight architecture is particularly well-suited for deployment on resource-constrained environments, such as edge devices and IoT gateways, where model compactness and efficiency are critical.
- By eschewing monolithic ensembles, DriftMoE opens the door for scalable online learning architectures adaptable to streaming regimes in diverse applied domains.
Theoretical implications:
- This work evidences the utility of gating networks and conditional computation—a design pattern extensively studied in large-scale batch learning—in an online, fine-grained adaptation context. The demonstrated synergy between router and incremental experts offers a new perspective on managing the stability-plasticity trade-off in continual learning.
Future Directions
Several extension avenues are identified:
- Development of adaptive cost-sensitive or class-imbalance-aware gating strategies.
- Incorporation of meta-learning signals or regime change detectors to dynamically adjust expert pool configuration.
- Exploration of advanced expert models (e.g., streaming-compatible NN architectures) within the DriftMoE framework.
- Application and scaling to high-dimensional, multi-task streaming settings, and integration with production-grade edge intelligence systems.
Conclusion
DriftMoE presents a compact, fully online Mixture of Experts architecture that leverages a symbiotic router-expert feedback loop for robust adaptation to concept drift. Extensive benchmarking on synthetic and real-world streams demonstrates competitive or superior performance to established ensembles with a substantially lower computational footprint, particularly excelling in dynamic drift and regime shift scenarios. With its principled design and efficiency profile, DriftMoE constitutes a strong candidate for future streaming machine learning systems targeting resource-aware, drift-adaptive AI deployments.