- The paper introduces DC-AE 1.5, which accelerates convergence by employing a structured latent space that organizes latent channels effectively.
- It presents augmented diffusion training that prioritizes object structure learning, achieving a 6-fold speed improvement over traditional methods.
- Experimental results on ImageNet 512×512 show enhanced image quality and efficient scaling, overcoming limitations of conventional diffusion models.
Accelerating Diffusion Model Convergence
The paper "DC-AE 1.5: Accelerating Diffusion Model Convergence with Structured Latent Space" (2508.00413) presents a novel approach to enhance the convergence speed and scaling efficiency of Latent Diffusion Models (LDM) using an improved autoencoder architecture. The primary innovation, DC-AE 1.5, leverages structured latent space and advanced diffusion training techniques to overcome challenges associated with increased latent channel numbers that traditionally slow down convergence. This research offers promising advancements in the field of high-resolution image synthesis, addressing inherent limitations in diffusion models and opening pathways to more efficient and effective image generation.
Structured Latent Space
The authors introduce the concept of a structured latent space within the DC-AE 1.5 framework, a strategy aimed at optimizing the spatial allocation of information in the autoencoder's latent channels. Traditionally, increasing the latent channel number to improve reconstruction quality results in sparsity, where most channels capture high-frequency image details, leaving object structure representation sparse. This sparsity thwarts the diffusion model's ability to learn structural representations efficiently, thereby slowing convergence.
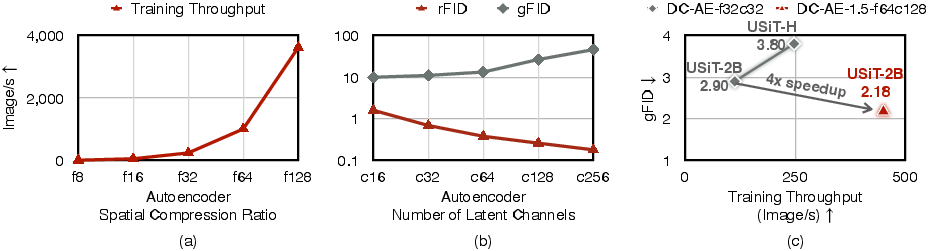
Figure 1: (a) Training Throughput Comparison under Different Autoencoder Spatial Compression Ratios. (b) rFID and gFID Results under Different Latent Channel Numbers.
The structured latent space approach imposes a channel-wise organization where initial channels focus on object structures while latter channels refine image details. This method not only resolves the sparsity issue but also enhances the model's capability to distinguish between essential structural representations and ancillary details.
Augmented Diffusion Training
Building upon the structured latent space, the paper introduces Augmented Diffusion Training. This innovative method accelerates learning by integrating additional training objectives focused on object latent channels. Through channel-wise mask augmentation during training, the diffusion model is encouraged to prioritize learning object structures more efficiently.
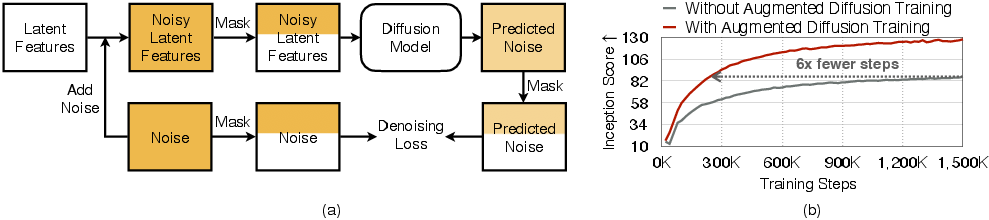
Figure 2: (a) Illustration of Augmented Diffusion Training. (b) Training Curve Comparison showing accelerated convergence.
As depicted in the training curve comparison, the augmented training methodology enables significantly faster convergence rates, achieving a 6-fold improvement in learning speed over traditional models on the UViT-H architecture. This enhancement is critical for deploying larger models often hindered by protracted training phases.
Experimental Results
Experimentation across various high-resolution datasets, particularly ImageNet 512×512, demonstrates that DC-AE 1.5 delivers superior generation capabilities compared to its predecessors. It’s noteworthy that instead of deteriorating gFID scores with expanding channel numbers, as observed in previous models, DC-AE 1.5 fosters both rapid convergence and improved image quality.
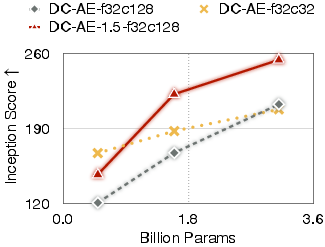
Figure 3: Diffusion Model Scaling Results on ImageNet 256×256 with USiT.
These results underscore DC-AE 1.5’s potential in real-world applications where balancing performance and resource efficiency is pivotal. By refining autoencoder architecture and diffusion training paradigms, this research significantly elevates the upper bounds of diffusion model efficacy.
Conclusion
DC-AE 1.5 marks a crucial step forward in optimizing diffusion models for high-resolution image synthesis. Through its structured latent space and augmented diffusion training methodologies, it not only accelerates model convergence but also enhances quantitative and qualitative image generation outcomes. This work provides a robust framework for developing more advanced diffusion models capable of surpassing existing limitations, thus paving the way for exciting future developments in AI-driven image generation. Future research should explore extensions of this framework to other domains, furthering the reach of diffusion models in computational efficiency and synthesis quality.

