- The paper introduces the SAM framework that generates high-fidelity synthetic CS assignments with robust privacy protection through iterative refinement and an LLM-powered privacy gate.
- It demonstrates that synthetic submissions closely resemble real data, achieving high semantic and structural fidelity as shown by strong BERTScore and Pearson correlation metrics.
- Empirical evaluations confirm that LLM-generated feedback on synthetic assignments is nearly indistinguishable from that on real submissions, validating the dataset for benchmark research.
SCALEFeedback: Synthetic Computer Science Assignments for Research on LLM-generated Educational Feedback
Introduction
The SCALEFeedback dataset addresses a critical bottleneck in the study and development of LLM-based systems for automated educational feedback: the scarcity of large, open, and privacy-preserving datasets of student assignments with detailed descriptions, rubrics, and authentic student submissions. Previous research in automated feedback generation has been hindered by limited-scale, context-specific datasets or privacy concerns that restrict sharing real assignment data. SCALEFeedback introduces a novel solution via the Sophisticated Assignment Mimicry (SAM) framework, enabling the one-to-one generation of high-fidelity synthetic assignments and student submissions that retain the semantic and structural properties of real data while ensuring perfect privacy protection. The dataset comprises 10,000 synthetic submissions across 155 assignments from 59 university-level computer science courses.
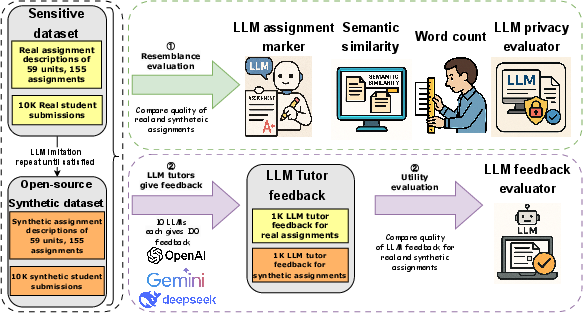
Figure 1: Overview of the SCALEFeedback dataset creation and evaluation pipeline, detailing the conversion of real data to synthetic using the SAM framework.
Methodology: The SAM Framework for Data Synthesis
The SAM framework implements a meticulous four-step in-prompt process, combined with an external LLM-powered privacy gate, to generate synthetic analogues of real assignments and submissions. The core steps involve LLM assessment of the original (theme, objectives, style, length, rubric detail), generation by imitation, evaluation of the synthetic product, and iterative refinement until the synthetic instance aligns closely with the real instance in the designated dimensions. The privacy gate, implemented using high-reasoning LLMs, guarantees that real student identifiers or sensitive data are not transferred into the synthetic outputs.
A baseline, “naïve mimicry”, boils down to simple instruction following—lacking the iterative, evaluative, and privacy-preserving aspects of SAM. Both approaches leverage state-of-the-art LLMs (including OpenAI GPT-4.1 and o4-mini-high), but only SAM integrates multi-step evaluation and privacy mechanisms.
Empirical Comparisons: Resemblance to Real-World Data
SCALEFeedback’s synthetic assignments exhibit high semantic similarity to their real counterparts, as measured by BERTScore F1 (0.859 for descriptions, 0.840 for submissions). For length, the Pearson correlation coefficients (PCC) reached 0.931 for assignment descriptions and 0.852 for student submissions, indicating strong fidelity in output magnitude. Critically, assignment marks, graded by ensembling several LLM scorers, displayed a moderate correlation (PCC = 0.624), but still highlighted a notable gap in capturing the long-tailed score distribution—submissions with exceptionally high or low marks were underrepresented, and mark averages skewed higher than the real data.
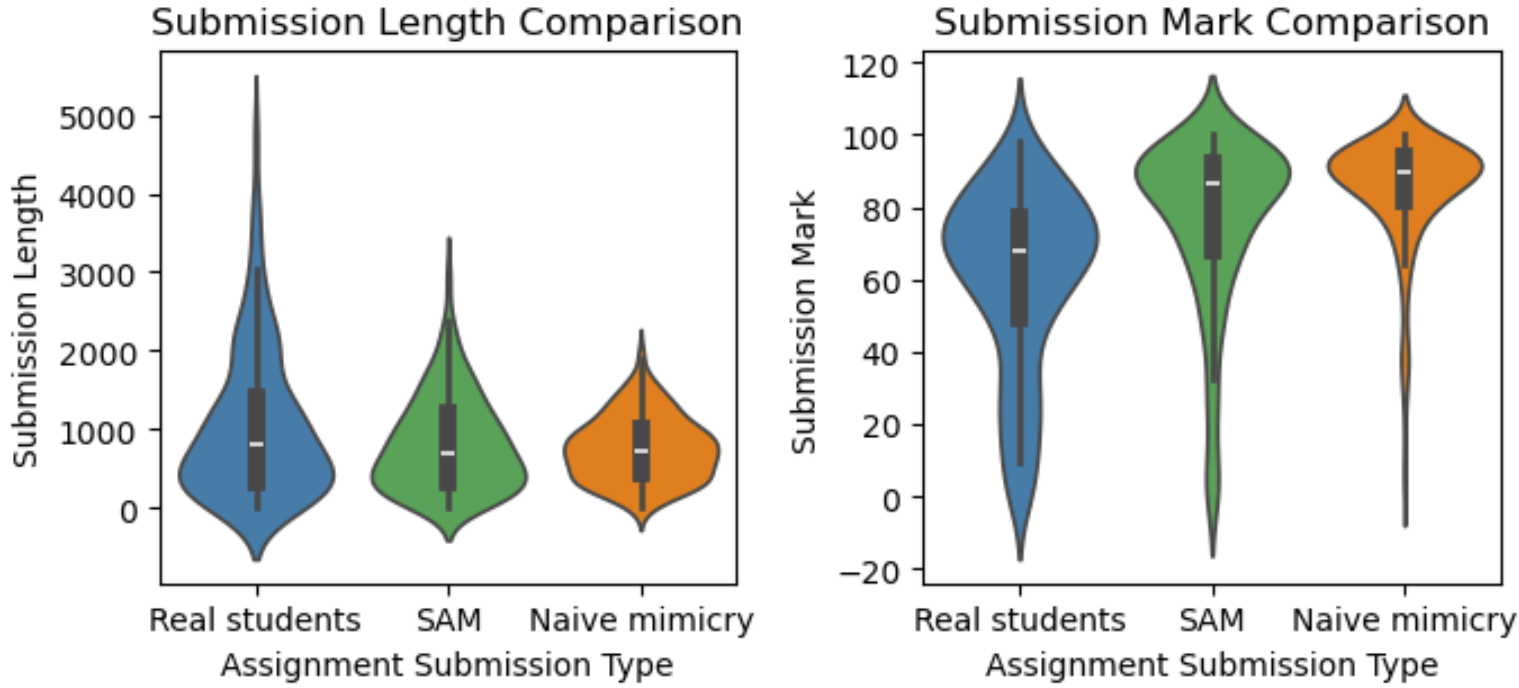
Figure 2: Distributions of submission length and marks across real, SAM-generated, and naïve mimicry submissions illustrate closer alignment for SAM.
The SAM framework significantly outperformed naïve mimicry both semantically and structurally across all metrics, and showcased substantially reduced mean absolute errors in lengths and marks. Notably, only the combination of in-prompt and external privacy protection mechanisms in SAM guaranteed 100% privacy protection, compared to 96.5% for naïve mimicry and slightly lower rates for partial ablations.
Utility Evaluation: Feedback Quality and Effectiveness
To test the practical utility of SCALEFeedback for LLM feedback research, 10 prominent commercial LLMs were tasked with generating educational feedback for both real-world and synthetic submissions. The comparison was conducted over 16 dimensions encompassing feedback content, effectiveness, and hallucination propensity, using an LLM-based evaluation rubric.
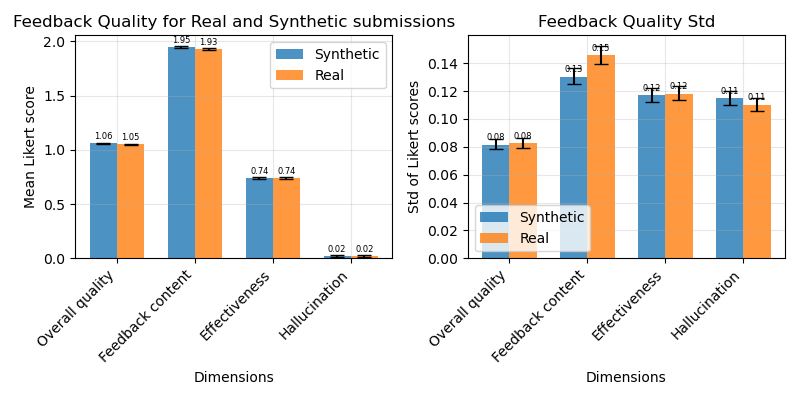
Figure 3: Feedback quality metrics for LLM-generated feedback on real student submissions versus synthetic submissions from SCALEFeedback; all mean performance differences are negligible.
Mean feedback quality, as aggregated across dimensions, was virtually indistinguishable between synthetic and real assignments. The largest deviation (0.02) was trivial in practical terms. Standard deviations were somewhat lower on synthetic data, reflecting the more centered distribution of generated assignments and feedback, though statistical significance was observed only in content dimensions. These results validate the compatibility of the synthetic dataset for rigorous benchmarking and experimentation with LLM-based feedback models.
Analysis of LLM Choice in Synthesis
A suite of OpenAI models (GPT-4.1, o4-mini-high, o3-high, etc.) was evaluated for performance in synthetic data generation via the SAM framework. There was no uniformly superior model; while some models were marginally better on specific dimensions (e.g., o3-pro-high for assignment description length PCC), overall resemblance metrics were high across all competitive LLM variants. Less capable models, such as GPT-4.1 nano and mini, displayed lower resemblance in certain aspects but maintained strong BERTScore F1, indicating capability in stylistic mimicry. Chain-of-thought-enabled models, while critical for mathematical or symbolic generation, did not show uniformly stronger results in assignment generation.
Practical and Theoretical Implications
SCALEFeedback provides a scalable, reproducible, and open methodology for academic institutions to unlock previously inaccessible educational data for the research community. Its synthetic record structure enables new research trajectories in robust, generalizable, and privacy-respecting automated feedback systems. A major practical implication is the removal of institutional, legal, and privacy-related barriers to open dataset construction.
However, behavioral diversity, especially in capturing long-tailed, extreme student performance cases, remains an open challenge. The tendency of LLMs to regress to the mean and produce distributions with dampened variance is consistent with known issues in data synthesis and highlights the need for persona-diversified prompting, such as Mixture-of-Personas frameworks (Bui et al., 7 Apr 2025).
Another crucial implication is the observed limitation of common evaluation metrics (e.g., BERTScore F1), which may mask nuanced semantic or pragmatic mismatches. Future research should adopt comparative, LLM-as-a-Judge methodologies for deeper insight into data fidelity (Huang et al., 2024, Balogh et al., 2023). The generality of the SAM framework further invites domain-wide expansion (e.g., to engineering, law, medicine) with customizable privacy and imitation schemas.
Conclusion
SCALEFeedback and the SAM framework represent a rigorous approach to synthesizing large-scale educational assignment datasets with strong semantic, structural, and pedagogical fidelity to real-world data. The resulting synthetic corpora support the development of advanced, scalable LLM-based feedback systems while overcoming privacy and copyright barriers endemic to educational data. Limitations in replicating behavioral extremes and the need for richer evaluation methodologies remain, providing fertile ground for ongoing research. Future work should prioritize greater behavioral diversity in synthetic data and adoption in a broader spectrum of academic disciplines, promoting open science and equitable access in educational AI research.
References:
- "SCALEFeedback: A Large-Scale Dataset of Synthetic Computer Science Assignments for LLM-generated Educational Feedback Research" (2508.05953)
- "Mixture-of-personas LLMs for population simulation" (Bui et al., 7 Apr 2025)
- "An Empirical Study of LLM-as-a-Judge for LLM Evaluation: Fine-tuned Judge Models are Task-specific Classifiers" (Huang et al., 2024)
- "Judging LLM-as-a-judge with mt-bench and chatbot arena" (Balogh et al., 2023)