- The paper introduces a layered synthetic data pipeline that cleanses user interaction biases to reveal robust scaling laws.
- It employs semantic grounding and unbiased user interaction histories, outperforming traditional real-data training in Recall@K metrics.
- Empirical results demonstrate that synthetic data enables predictable power-law scaling and improved generalization across LLM recommendation systems.
Synthetic Data as an Enabler of Scaling Laws for LLMs in Recommendation
Motivation and Problem Analysis
The application of LLMs to recommender systems is constrained by the lack of predictable scaling laws for continual pre-training (CPT), inhibiting systematic research and impeding effective resource allocation. Prior efforts suffered from the deep pathologies of user interaction logs—including noise, sparsity, position bias, popularity bias, and exposure bias—preventing the establishment of power-law scaling behavior. Attempts such as PLUM (He et al., 9 Oct 2025) and OneRec (Zhou et al., 16 Jun 2025) failed to exhibit robust scaling, with larger models unable to consistently outperform smaller counterparts, a symptom directly attributed to information-poor and structurally biased data.
The paper hypothesizes that scaling failure is fundamentally a data-centric problem. Instead of modifying model architectures or loss functions to be robust to flawed data, the approach is to engineer high-fidelity synthetic datasets—free of systemic biases—as a pedagogical curriculum for LLMs. This paradigm shift is theoretically motivated by recent scaling law analyses (Yang et al., 2024, Allen-Zhu et al., 2024), which demonstrate that data quality and diversity are prerequisites for predictable scaling.
Layered Synthetic Data Framework
A two-layer synthetic data generation pipeline is formulated:
Layer 1: Semantic and Collaborative Grounding
- Item-text alignment: Establishes item semantic representations using natural language descriptions mapped to discrete semantic tokens (<RECTOKEN>), transcending traditional co-occurrence pattern memorization.
- Collaborative Filtering (CF) data: Explicitly encodes statistical user-item affinity via mined association rules cast in language templates.
Layer 2: Unbiased User Interaction Histories (UIH)
- Employs Node2Vec-based second-order random walks over the CF-induced item graph, producing synthetic user interaction sequences devoid of position, popularity, and exposure biases. This process decouples behavioral signal from system-induced artifacts, yielding curriculum sequences untethered to privacy-sensitive real logs.
Direct evidence of the synthetic data's practical value is provided via "Train on Synthetic, Test on Real" (TSTR) experiments, comparing standard sequential recommendation models (GRU4Rec, NARM, SASRec, STAMP) against conventional "Train on Real, Test on Real" (TRTR) setups.
Models trained exclusively on synthetic data outperform real-data-trained models across all K cutoffs in Recall@K metrics for all architectures, illustrating the synthetic curriculum's superiority in teaching generalizable preference patterns over downstream real-item tests.
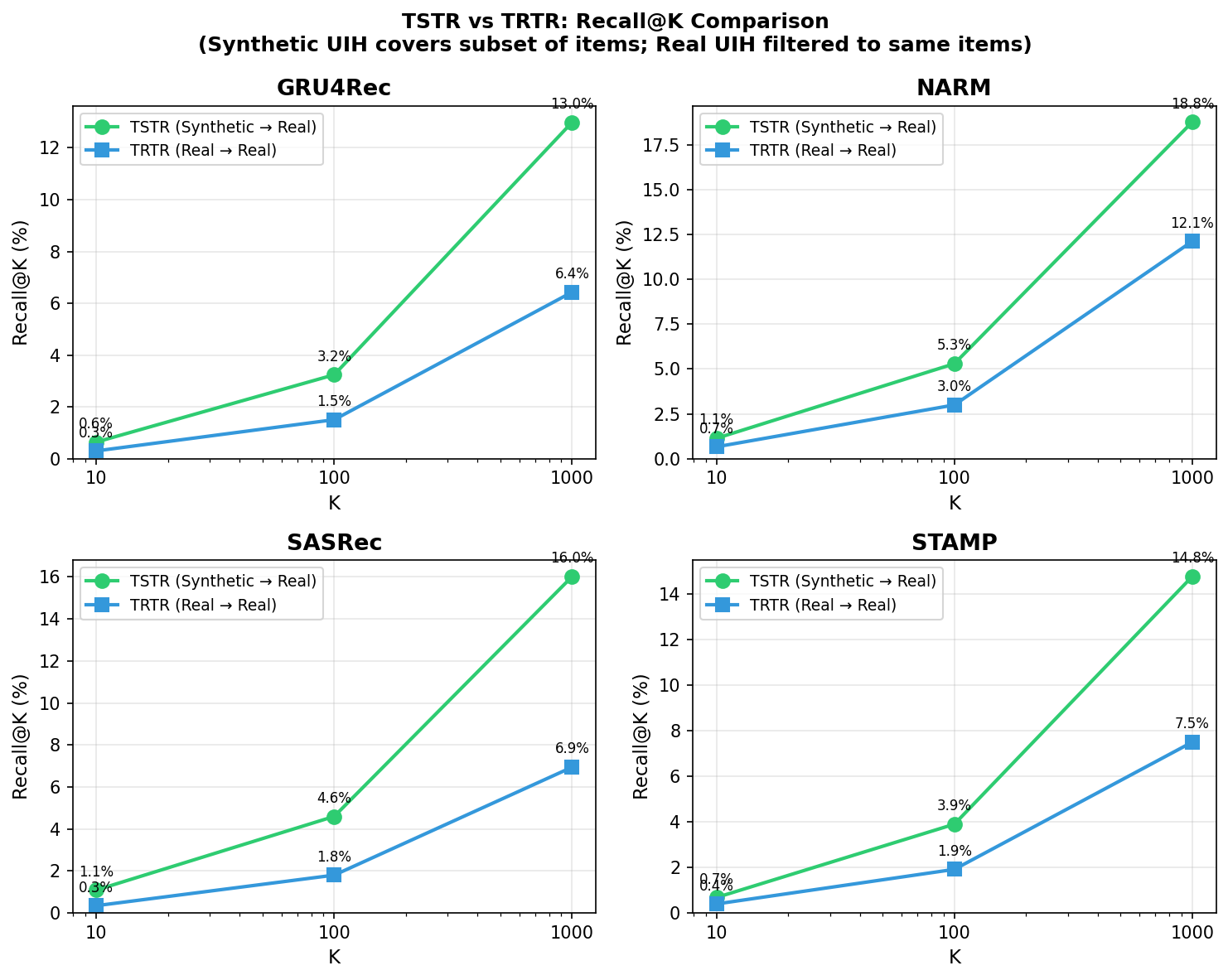
Figure 1: TSTR vs TRTR Recall@K shows synthetic-trained models consistently outperform real-data-trained models across GRU4Rec, NARM, SASRec, and STAMP.
These results decisively demonstrate that structured, bias-free synthetic data imparts more universal co-occurrence signals, unlocking better ranking generalization than information-poor logs.
Data Modality Scaling: Robust Power-Law Laws in Recommendation
With this synthetic paradigm, rigorous scaling law studies become tractable. Across model sizes (0.6B–8B parameters, Qwen3-based), robust power-law scaling (L(D)=L∞+A⋅D−α) is observed for multiple recommendation evaluation domains. UIH yields strong scaling exponents (α≈0.45–$0.59$), CF data performs well (α≈0.35), and item-text alignment exhibits moderate scaling (α≈0.15). General domain data is saturating (α<0.1) due to pre-trained checkpoint knowledge.
The quantitative hierarchy clearly ranks UIH as the most "pedagogically efficient" domain for continual pretraining.
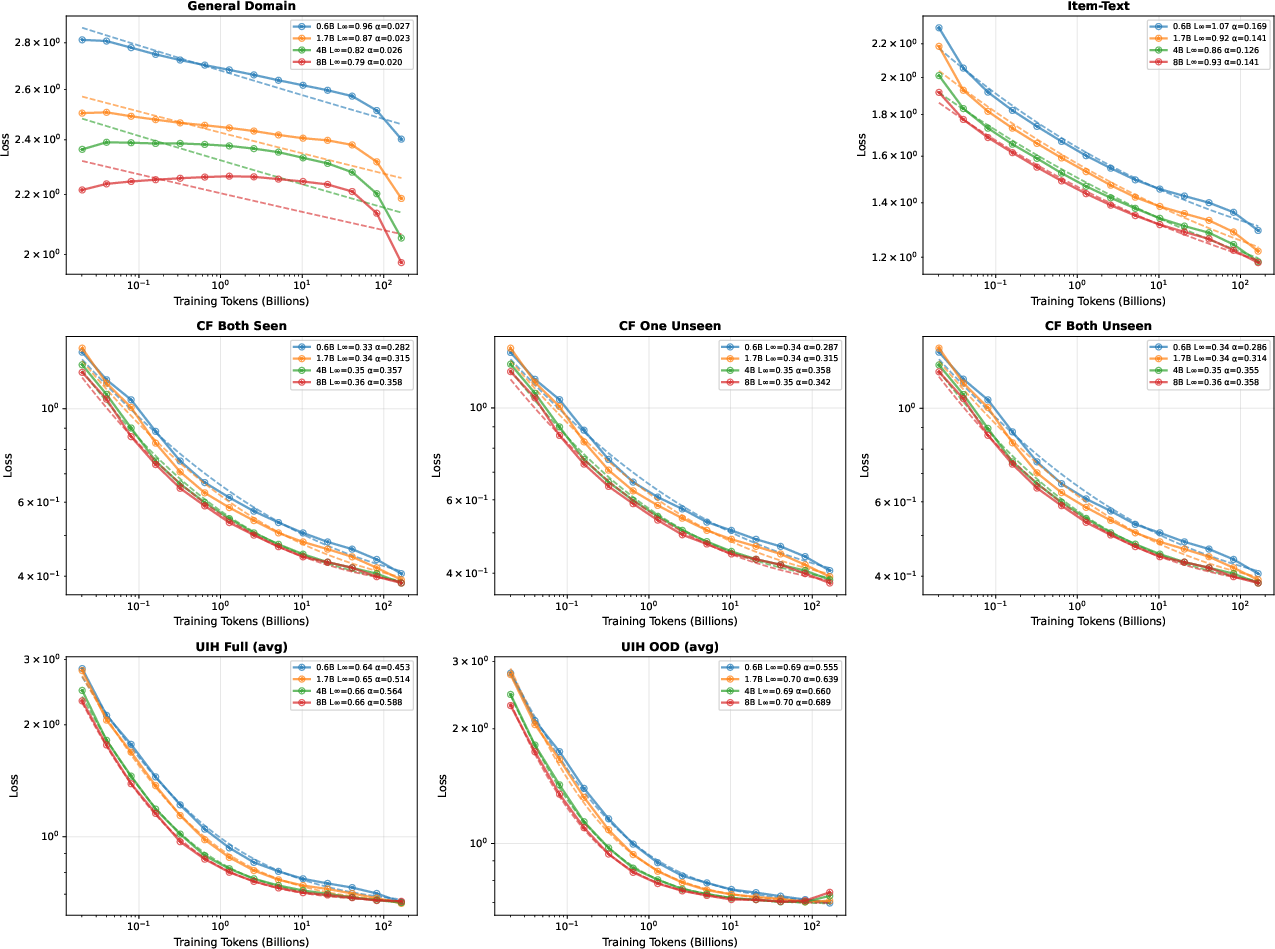
Figure 2: Scaling laws for different domains; UIH demonstrates the steepest scaling (αUIH≈0.45–$0.59$), CF moderate, item-text low.
Asymmetric Data Layer Synergy and Ablation Insights
Ablation studies reveal pronounced asymmetry between CF and UIH layers. Inclusion of CF data substantially improves UIH modeling (L∞=0.66 vs $0.95$), but UIH does not reciprocally benefit CF tasks. Exclusion of any domain leads to degradation in its corresponding evaluation metric, emphasizing the necessity of maintaining a balanced curriculum.
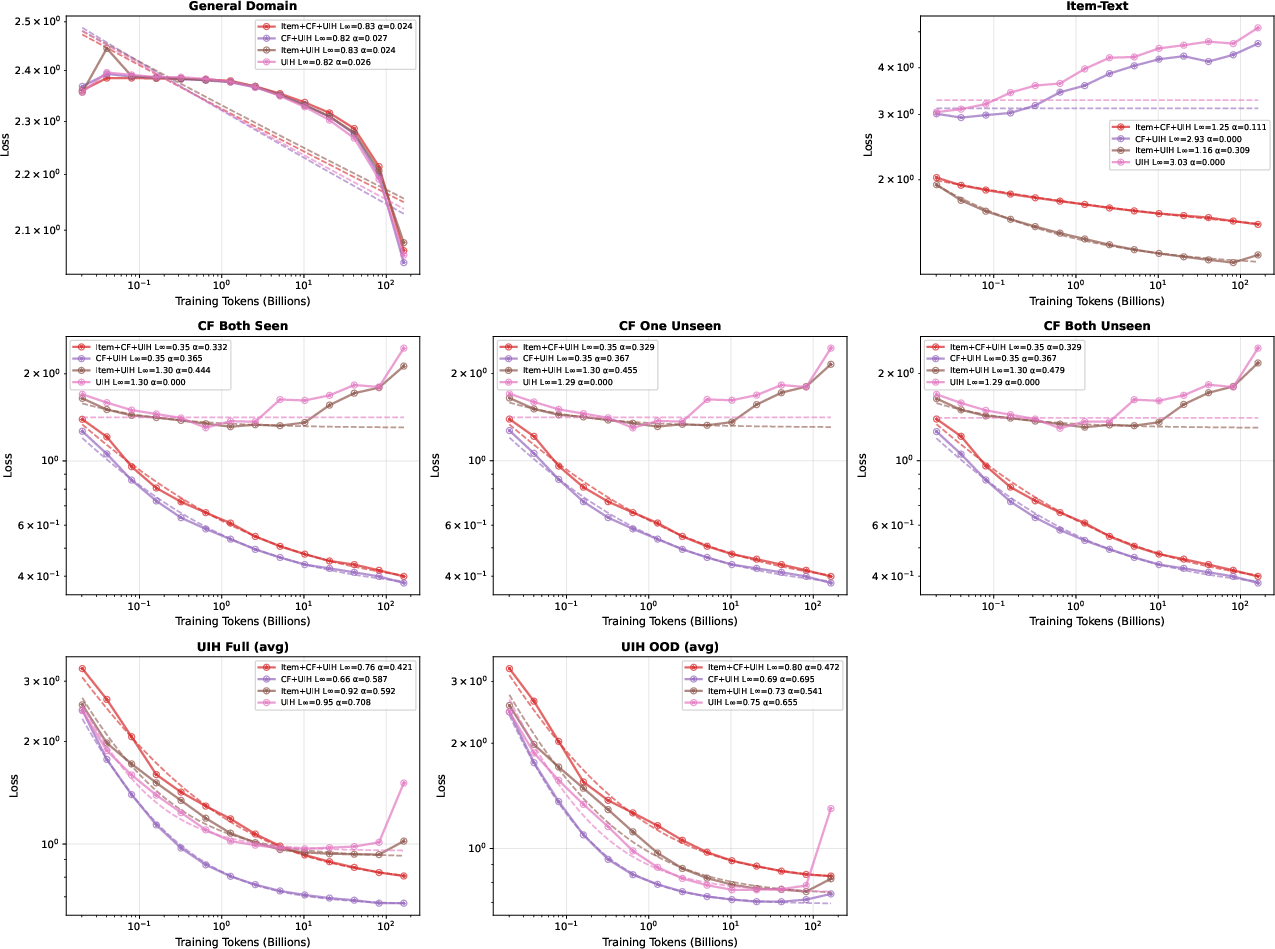
Figure 3: Ablation studies indicate omitting CF or item-text sharply degrades performance in their respective domains.
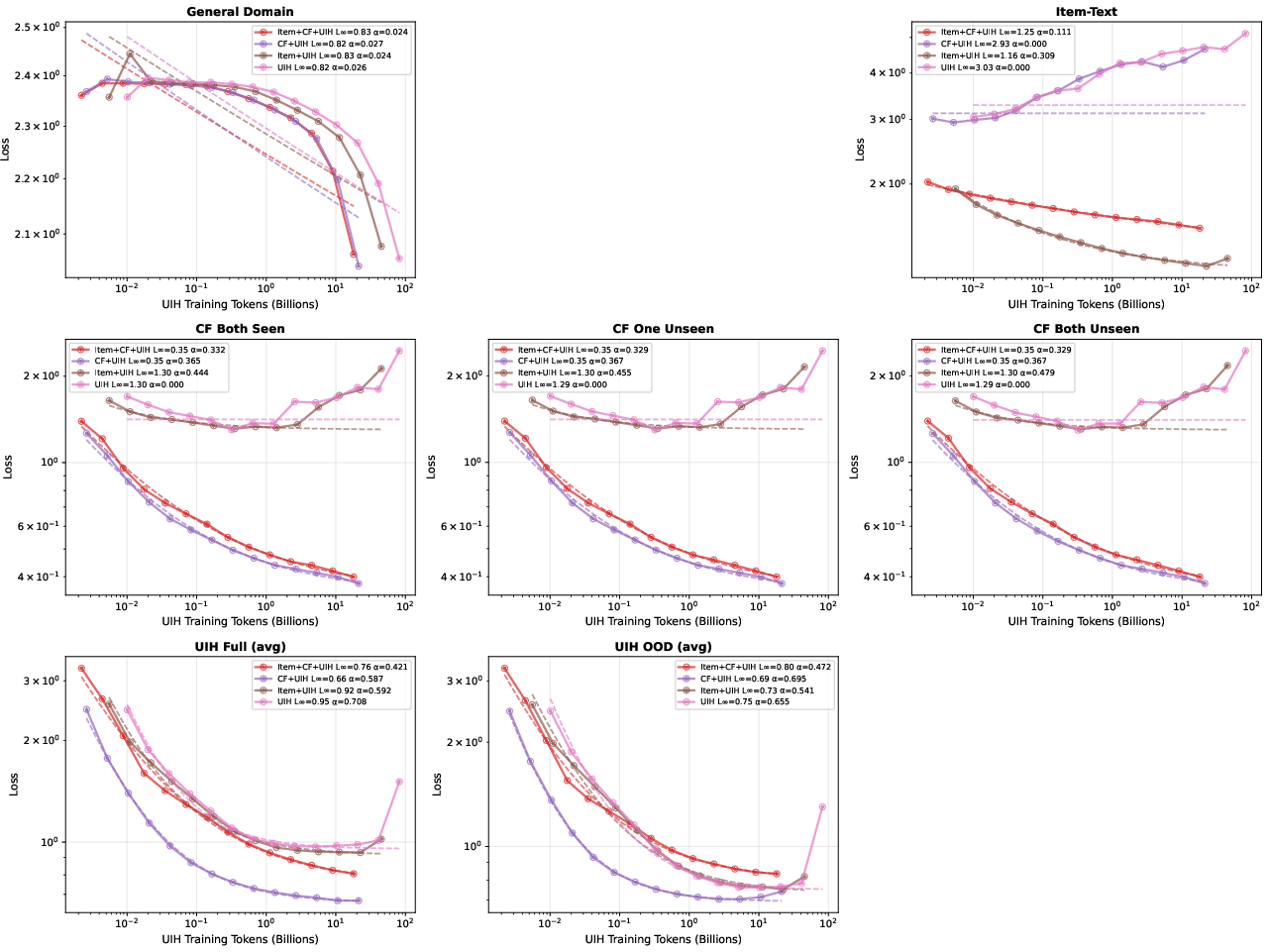
Figure 4: UIH evaluation perplexity vs UIH training tokens; including CF data further lowers UIH loss.
Data Mixture Ratio and Overfitting Dynamics
Scaling law robustness is sensitive to mixture ratios and data repeats. Excessive repetition of reduced UIH data induces overfitting—perplexity begins to increase after ~16 repeats, consistent with known repeat-induced memorization degeneration (Muennighoff et al., 2023). Performance degradation occurs earlier in training for higher mixture ratios, and is largely invariant to model scale.
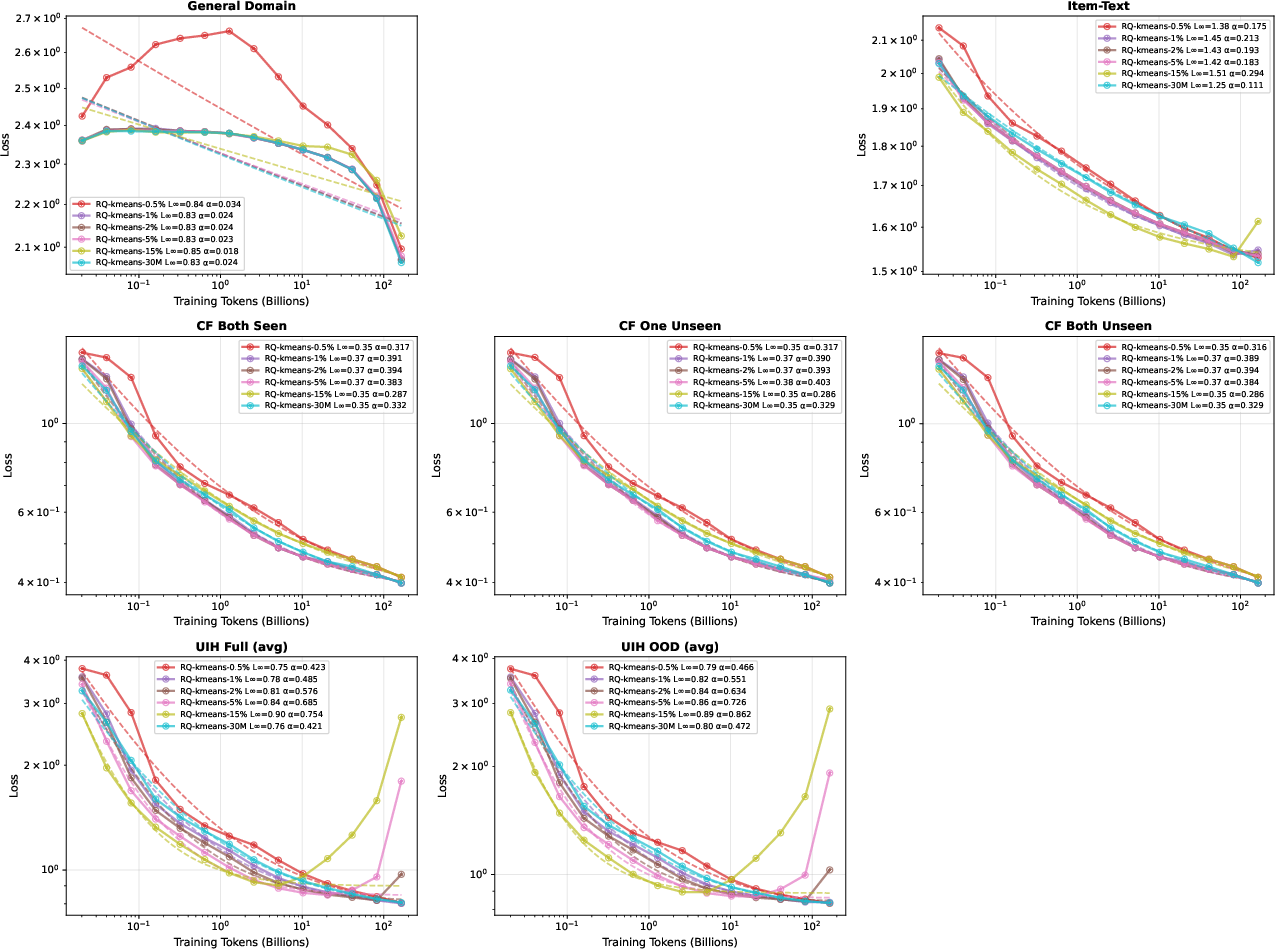
Figure 5: Scaling laws on 4B models with varying UIH mixture ratio; overfitting emerges when repeat count exceeds a threshold.
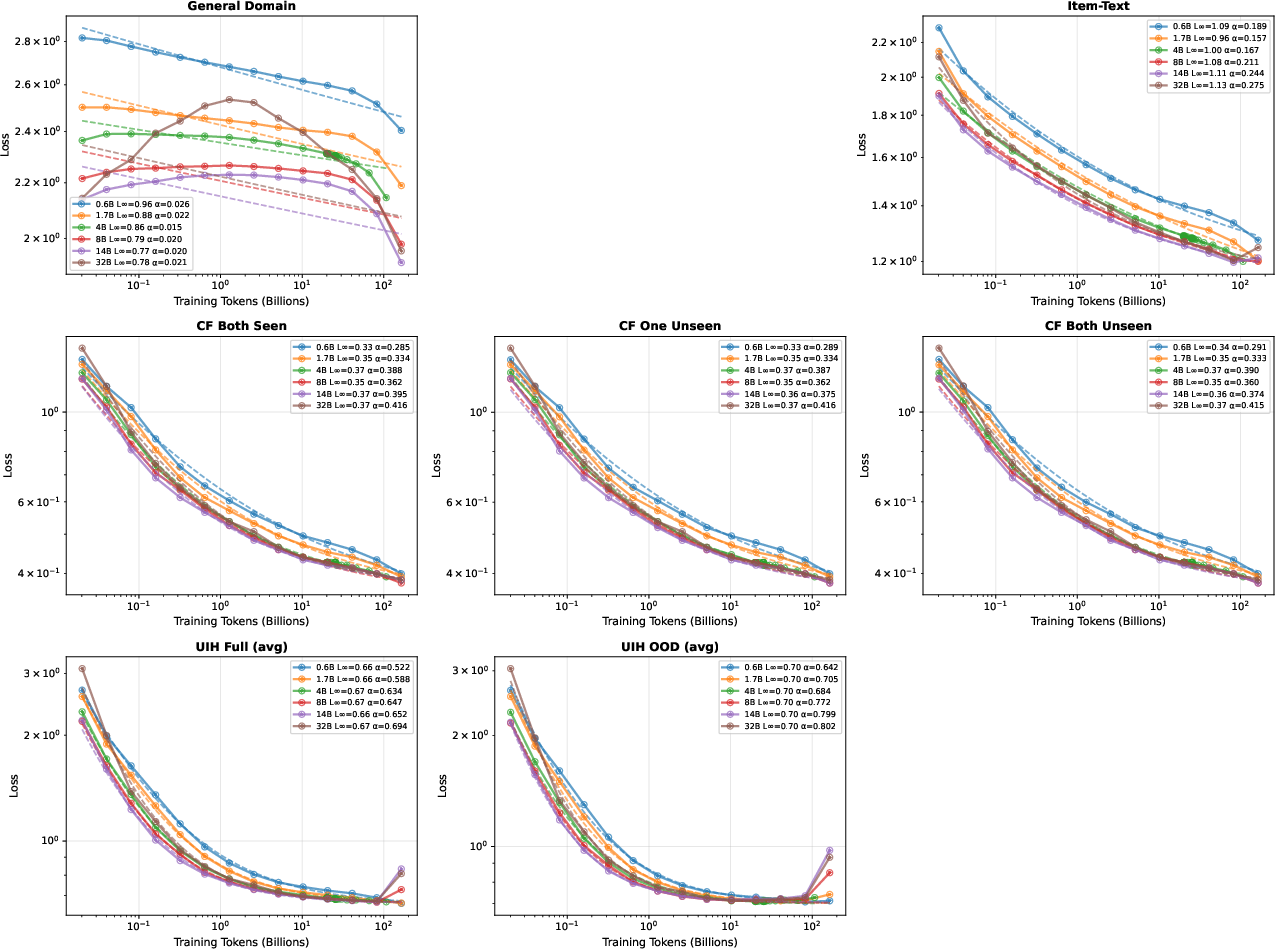
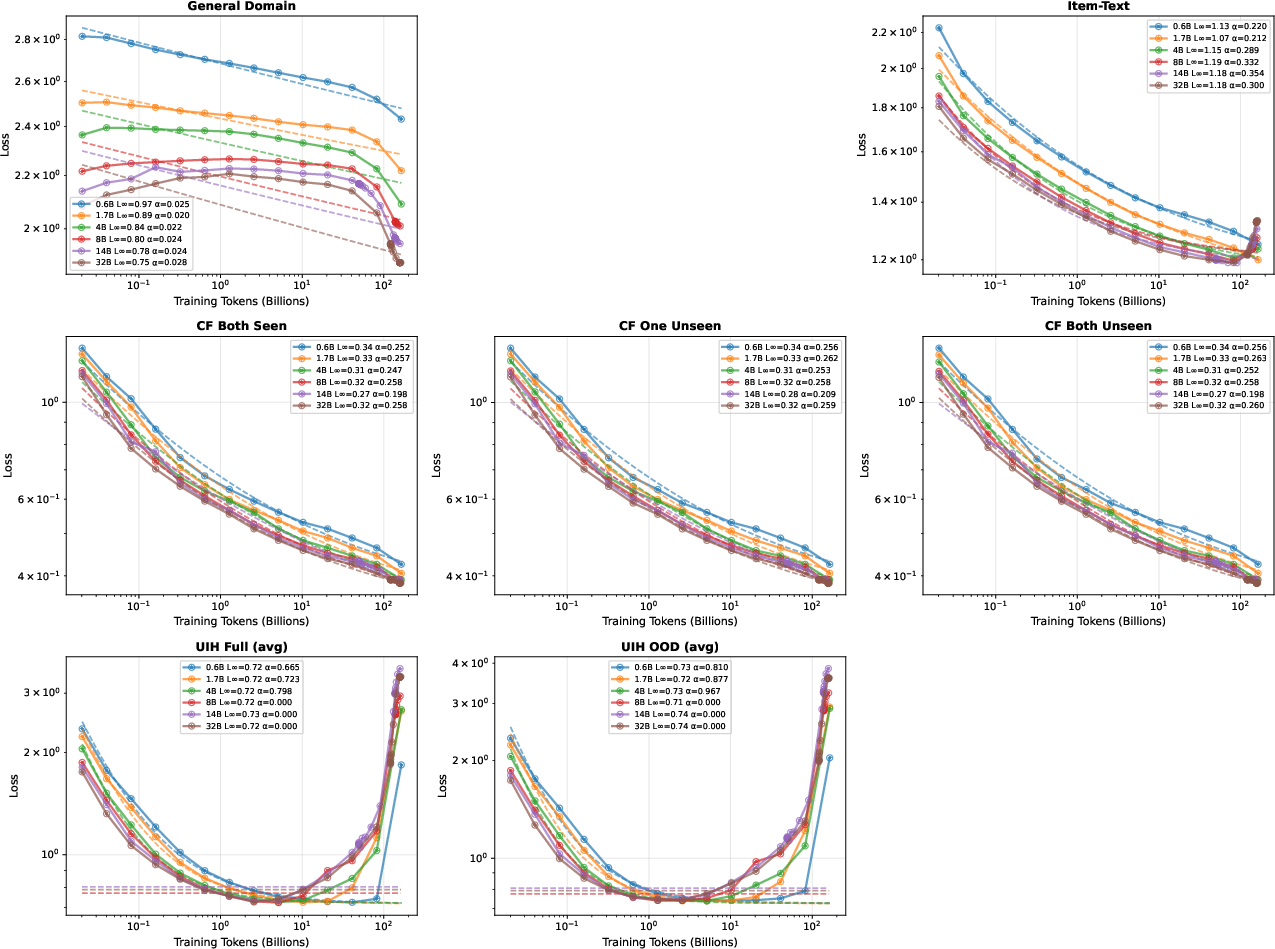
Figure 6: UIH mixture ratio of 2% yields predictable scaling; overfitting manifests at higher ratios.
Compute-Optimal Scaling and Capacity-Repeat Interactions
Compute-optimal scaling analysis reveals that general domain perplexity follows expected Pareto-optimal scaling, but recommendation domains diverge due to repeated synthetic data. For UIH, smaller models trained with extreme repetition generalize better OOD than larger models at Chinchilla-optimal tokens/parameter, highlighting the regularization-like effect of repetition-versus-capacity.
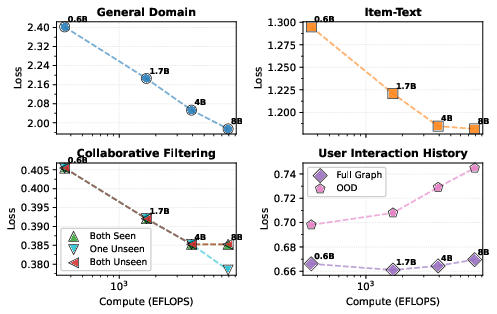
Figure 7: Compute-optimal scaling—general domain follows Pareto frontier, recommendation domains (especially UIH) show non-monotonic behavior due to interaction of repeat and model scale.
Tokenization Study
Domain-adaptive semantic tokenization is addressed via comparison of Sparse Autoencoder (SAE) and RQ-Kmeans methods. Scaling law analysis decisively favors SAE tokenization for item representations across all domains.
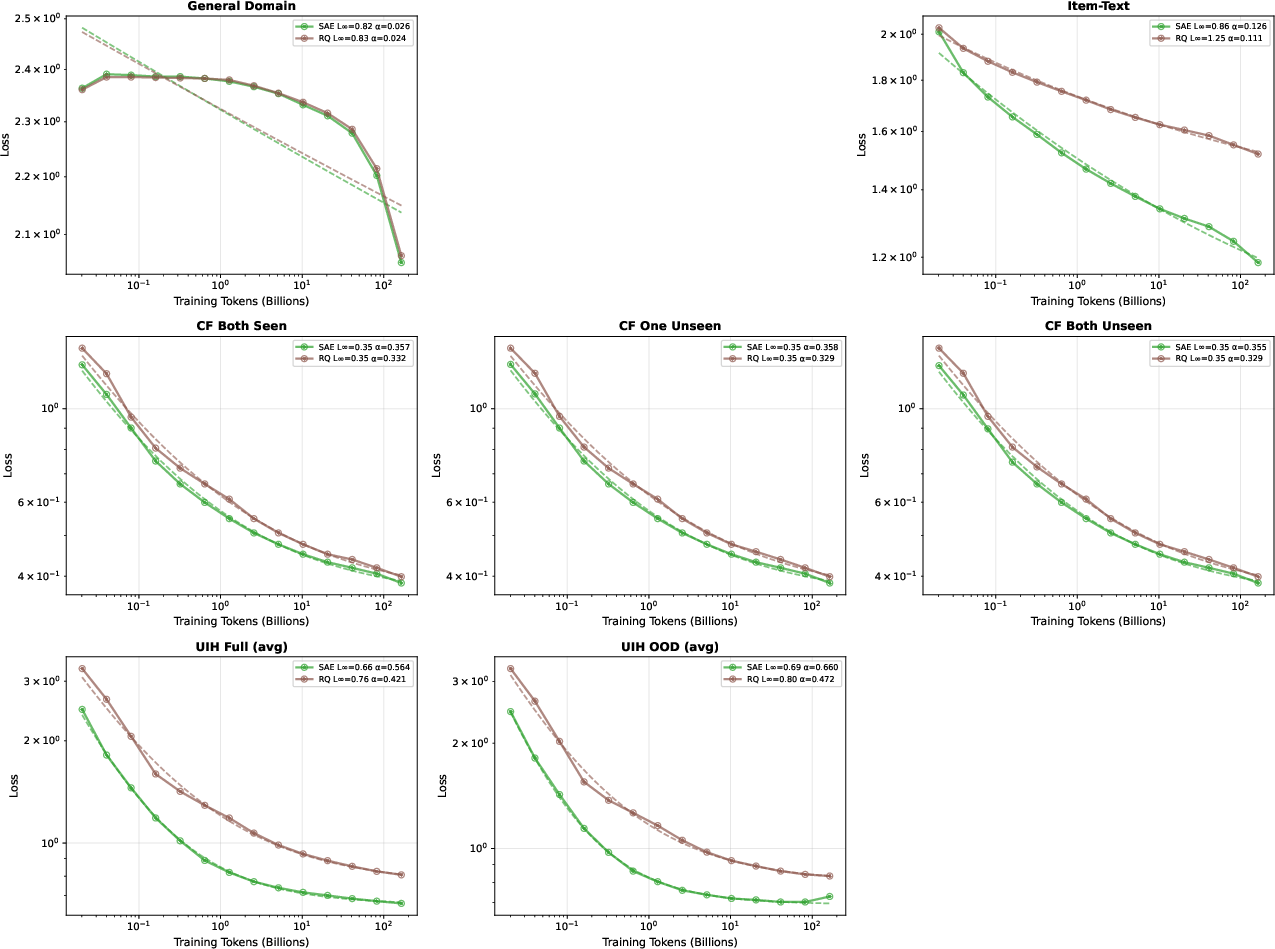
Figure 8: Scaling laws on 4B models with SAE vs RQ-Kmeans tokenization; SAE outperforms RQ-Kmeans universally.
Implications, Limitations, and Outlook
The synthetic curriculum unlocks power-law scaling, transforming recommendation LLM development from heuristic to principled. For practitioners, these laws provide resource allocation guidance and end predictable trial-and-error design cycles. The inherent privacy preservation and debiasing open avenues for fairer, more equitable recommendation systems—decoupling from engagement-driven bias amplification known to afflict production logs.
Future research will likely focus on extending synthetic curriculum methods to domains with richer context (multi-modal, agentic flows), refining cross-domain transfer architectures, and developing longitudinal evaluation frameworks for fairness and generalization. As scaling law methodologies mature in recommendation, they will drive broader adoption of LLMs as the foundation of end-to-end generative recommender infrastructure.
Conclusion
This work establishes principled synthetic data as the enabling substrate for robust scaling laws in LLM recommendation. The layered synthetic curriculum cleanses user preference signal, achieves superior ranking generalization, and empirically unlocks power-law scaling across model and data scales. The research reframes the recommendation LLM pipeline from model-centric to data-centric design, inaugurating an era of systematic, predictable, and privacy-preserving development. The theoretical and practical implications decisively shift the domain from incremental heuristics to foundational scientific progress (2602.07298).