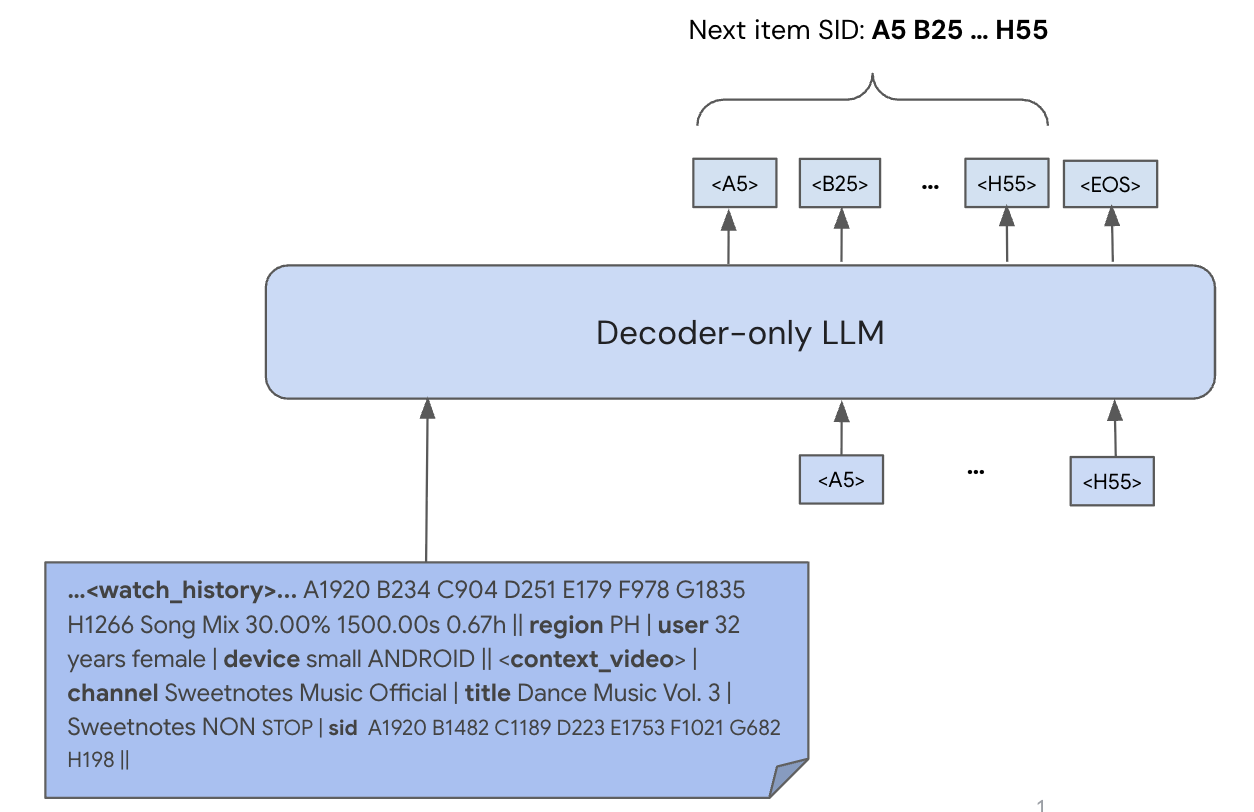
- The paper introduces PLUM, which adapts pre-trained LLMs for recommendation systems using tokenized semantic IDs and continued pre-training on domain data.
- It employs a Residual-Quantized VAE and contrastive learning to fuse multi-modal embeddings, enhancing item representation and retrieval quality.
- Experimental results demonstrate improved recall rates, engagement metrics, and scalability compared to traditional embedding-based recommenders.
PLUM: Adapting Pre-trained LLMs for Industrial-scale Generative Recommendations
Introduction
The paper "PLUM: Adapting Pre-trained LLMs for Industrial-scale Generative Recommendations" (2510.07784) presents a novel approach to adapting pre-trained LLMs for recommendation systems. Traditionally, recommendation systems have relied on Large Embedding Models (LEMs), which use extensive embedding tables to encode high-cardinality categorical features. However, the scalability of LLMs offers a potent alternative, often hindered by domain gaps and unique feature-coding paradigms present in recommendation tasks. PLUM aims to bridge this gap by introducing a structured framework.
PLUM Framework
PLUM consists of three key stages:
- Item Tokenization with Semantic IDs (SIDs): Items are represented by discrete token sequences. This is achieved using multi-modal embeddings and a Residual-Quantized Variational AutoEncoder (RQ-VAE). The process involves fusing content features, enhancing hierarchical structure with multi-resolution codebooks, and integrating user behavior through co-occurrence contrastive learning (Figure 1).
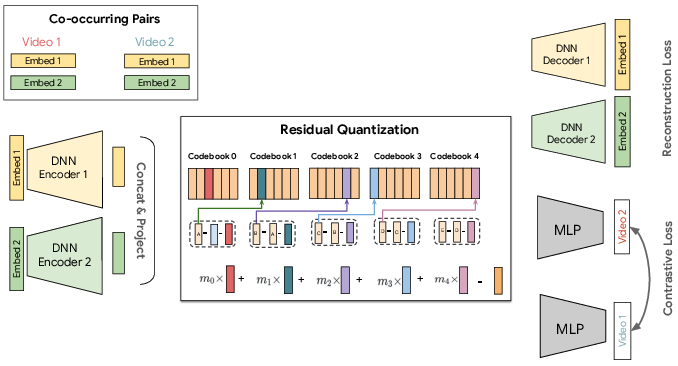
Figure 1: Illustration of our Semantic ID model. It takes two multi-modal video embeddings, encodes them, and compresses the result into a quantized ID using a residual quantizer. This ID is trained to both reconstruct the original inputs and semantically cluster co-occurring videos using a contrastive loss.
- Continued Pre-training (CPT): The LLM's vocabulary is expanded to encompass SID tokens. This stage incorporates domain-specific data, bridging the domain gap and aligning SID and language tokens. The training involves user behavior data and a corpus of video metadata, embedding SIDs within an extensive language understanding.
- Task-specific Fine-tuning for Generative Retrieval: The framework employs autoregressive generative retrieval, training the model to output SIDs of recommended items based on user context. This eschews the need for traditional item indices, addressing traditional limitations of embedding-based retrieval.
Experimental Results
The PLUM framework demonstrates superior performance compared to traditional models primarily reliant on embedding tables:
Impact of Continued Pre-Training
Ablation studies reveal that the CPT stage significantly enhances the model's training efficiency and its capability to generalize. Initializing from a pre-trained LLM further improves performance, leveraging LLMs' text sequence modeling capabilities for recommendation tasks.
Scaling Study
The scaling analysis of the PLUM framework across varying model sizes and computational budgets highlights the framework's adaptability and efficiency. Larger models demonstrate enhanced generalization capabilities, showing consistent improvements in retrieval metrics with increased compute, indicating successful scalability of the generative approach.
Conclusion
PLUM presents a scalable and efficient framework aligning LLMs with recommendation systems, demonstrating significant improvements in generative retrieval tasks. As the framework continues to evolve, future research could expand its application to various recommendation-related tasks, further integrating natural language processing capabilities with recommendation-specific model architectures.