- The paper presents a 150B parameter decoder-only model, 360Brew V1.0, that replaces complex feature engineering with a unified textual interface.
- The methodology employs large-scale pre-training on diversified LinkedIn data to support over 30 predictive ranking and recommendation tasks without task-specific fine-tuning.
- The study demonstrates improved handling of cold-start issues and interaction dynamics, complemented by scalable inference through optimized distributed training frameworks.
360Brew: A Decoder-only Foundation Model for Personalized Ranking and Recommendation
The paper "360Brew: A Decoder-only Foundation Model for Personalized Ranking and Recommendation" (2501.16450) introduces a novel approach to improving the performance of recommendation systems by utilizing a large-scale decoder-only LLM. This model, named 360Brew V1.0, is specifically designed for the LinkedIn platform to tackle a wide variety of predictive tasks related to ranking and recommendation. Unlike existing systems that predominantly employ ID-based models and complex feature engineering, 360Brew leverages a unified model architecture that uses natural language as a comprehensive interface for defining tasks, thus reducing the need for extensive feature engineering and complex model dependencies.
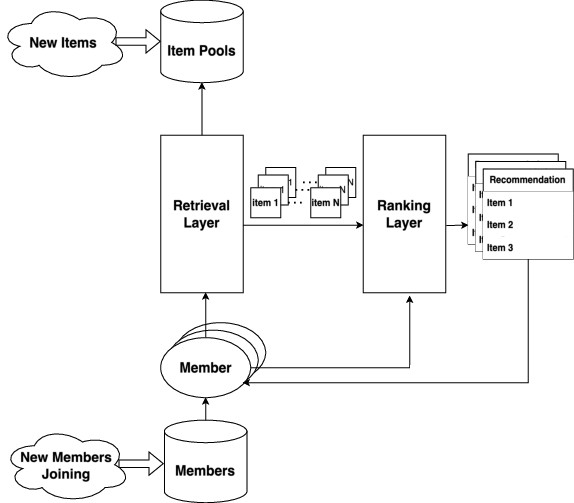 *Figure 1: Overview of A Recommendation System (RS) %{Shall we make this fig a bit smaller? just asking}. *
*Figure 1: Overview of A Recommendation System (RS) %{Shall we make this fig a bit smaller? just asking}. *
Construction Challenges in Traditional Recommender Systems
The existing recommendation systems—comprising of the retrieval, ranking, and blending layers—are often based on ID and handcrafted features. These allow model specialization but lead to several challenges:
- Cold-start Problem: Traditional systems tend to struggle with new items or members due to their reliance on specific feature embeddings.
- Interaction Dynamics: With diverse user actions requiring complex feature engineering, traditional models were constrained in efficiently generalizing across different surfaces and tasks.
The paper discusses the use of a 150B parameter decoder-only foundation model that is trained and fine-tuned on LinkedIn’s proprietary data. This approach is said to support over 30 predictive tasks without task-specific fine-tuning, achieving performances that can match or exceed existing production systems based on offline metrics.
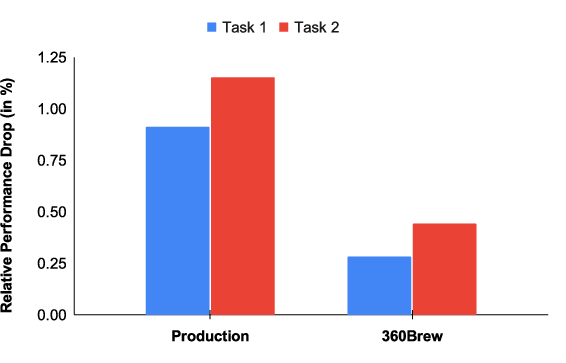
Figure 2: Performance of model compared to baselines as the test data gets temporally farther from the training data.
Decentralization via Decoder-Only LLMs
The paper proposes utilizing a large LLM architecture with a textual interface to capitalize on its comprehension and reasoning capabilities, allowing the model to perform manual feature engineering implicitly through contextual learning, previously a burden in traditional RS models.
Recent studies have demonstrated that LLMs can integrate (e.g., member profiles and content descriptions) in a textual interface, showcasing promising resolution to the cold-start problem (Figure 3).
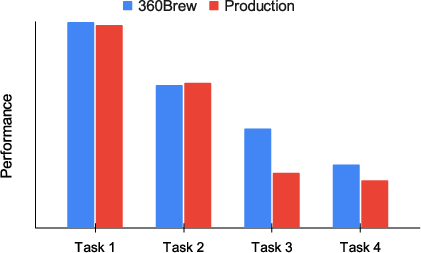
Figure 3: Performance on 4 T2 tasks across 4 surfaces which were not part of the training.
The approach challenges the traditional reliance on with ID-based features by replacing them with centralized prompt engineering, using a deep, multilayer transformer model architecture that is adaptive to changing data and new tasks.
Continuous Pre-training via Mixtral 8x22B Model
The foundation model, termed V1.0, effectively leverages the Mixtral 8x22B MoE~(Esmaeili et al., 2023) architecture. This model accommodates more complex relationships, thus avoiding the need for vast numbers of manually crafted features, a common bottleneck in traditional RS.
Figure 4 in the original paper illustrates the improvement in model performance with an increase in the model's parameters.
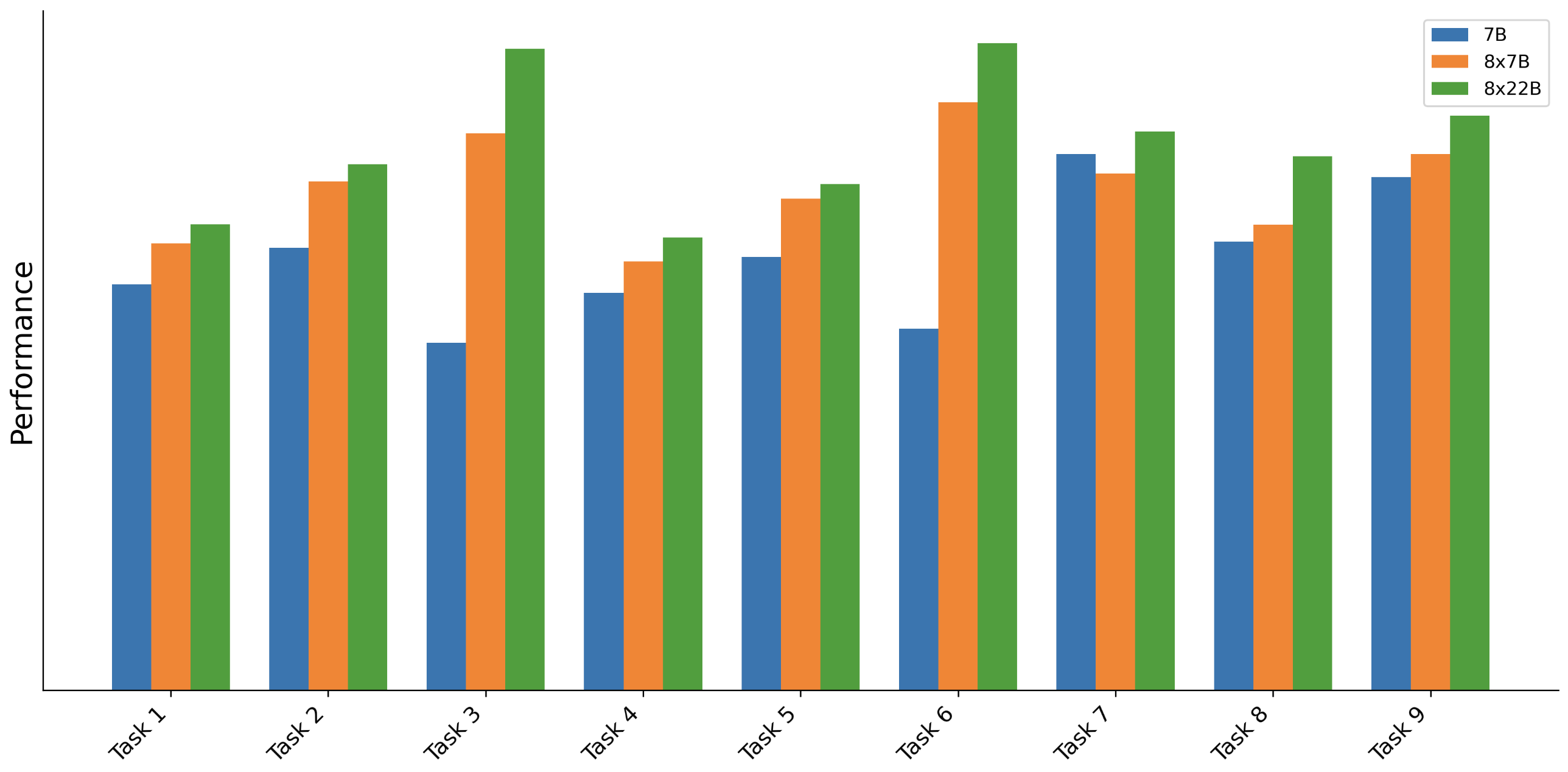
Figure 4: Effects of model size (in parameters) on the performance across different tasks.
Data-centric Approach and Pre-training
The data used for pre-training on the LinkedIn Economic Graph involves a diverse range of interactions, profiles, job descriptions, and network data spanning 3-6 months and engaging approximately 45 million active monthly members.
Data diversification, especially through stratified and importance sampling, plays a significant role in enhancing model generalization. Through continuous pre-training by scaling the token count, 360Brew effectively closes the gap to production models on T1 tasks, as demonstrated in (Figure 5).
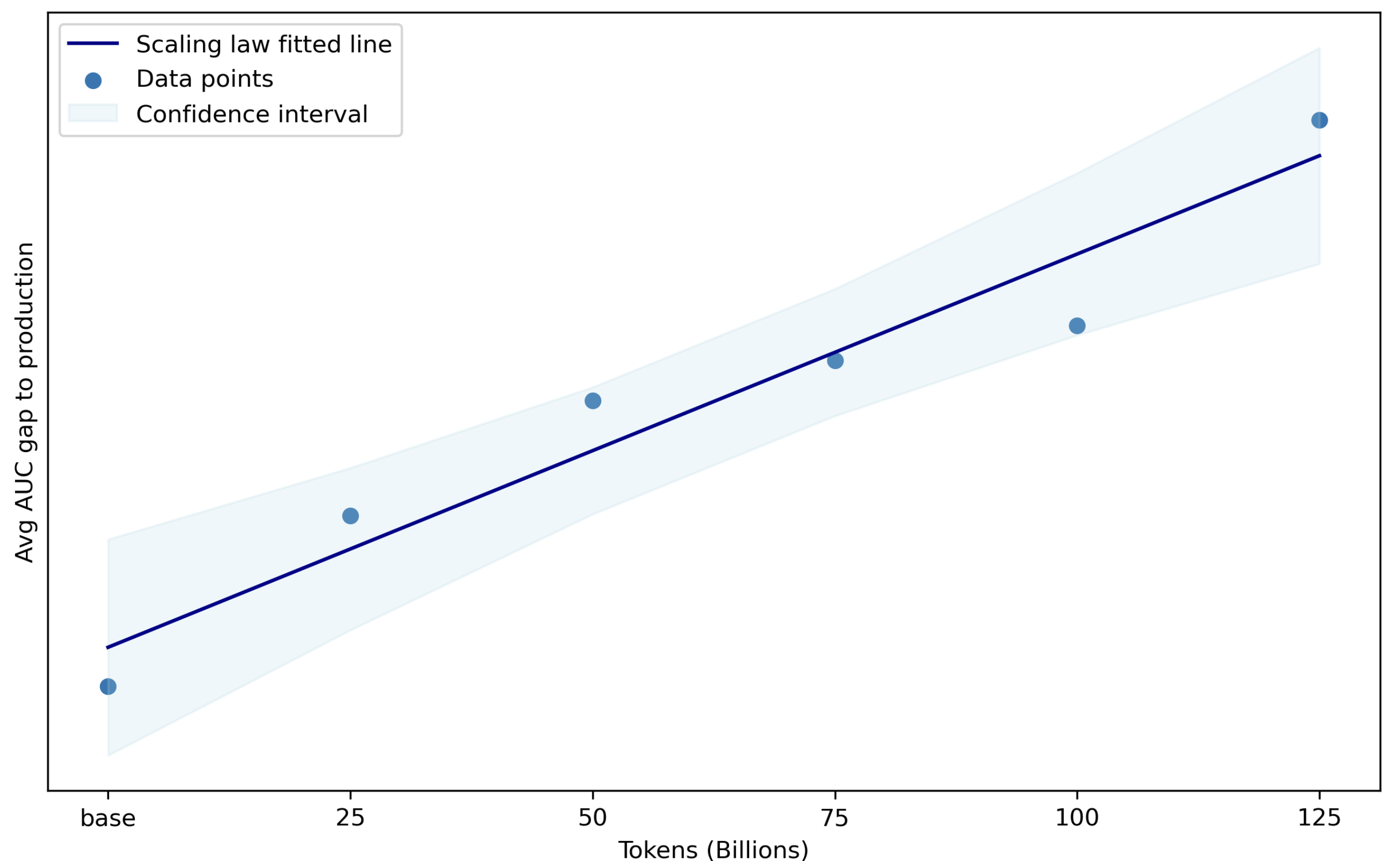
Figure 5: Closing the gap to production models on T1 tasks by scaling the token count during continuous pre-training.
Infrastructure Scaling and Technical Challenges
To cope with the computational demands of a 150B parameter model, the paper employs PyTorch Lightning and the PyTorch-native FSDP for distributed training. Efficient handling of large models was enabled by optimal checkpointing to ensure minimal disruption during the training loop. The Lightning Fully Sharded Data Parallel strategy was used to enhance training parallelism while optimizing resource utilization.
The team evaluated traditional 3D parallelism approaches as well as DeepSpeed ZeRO-2 and ZeRO-3 methods but ultimately chose to use PyTorch-native FSDP due to its compatibility and reduced operational burden. While FSDP was favored for training, vLLM was selected for inference due to its strong community support and the ability to maintain consistent inference across various use cases with efficient KV-caching for autoregressive generation, as shown in (Figure 6).
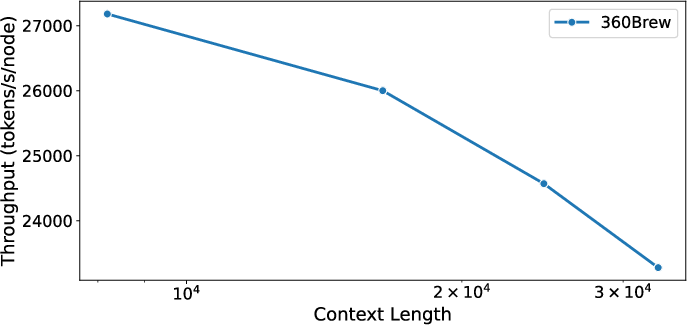
Figure 6: Effect of context length on batch inference throughput on Nvidia A100. Throughput decreases with increasing context length but not linearly with log2(context length).
Despite these advantages, the implementation using vLLM faced challenges related to performance drops due to configuration assumptions and issues with multiprocessing workers in offline scripts. However, community support played a significant role in addressing many of these issues.
Successful Application and Generalization of ICL
The paper explores the power of ICL in creating personalized recommendations. Using a Many-Turn Chat (MTC) template for supervised fine-tuning, the model becomes adept at generating personalized prediction based on historical interactions within given contexts.
Despite the cost of additional CPT, significant improvements are observed in long-context generalization, maintaining competitive performance across both in-domain and out-of-domain tasks without additional fine-tuning. The model leverages its ICL capabilities to optimize the personalization of recommendations through the effective use of historical member interactions as context (Figure 3).
Figure 3: Performance on 4 T2 tasks across 4 surfaces which were not part of training.
Conclusion
The paper presents a hierarchical, decoder-only model architecture, "360Brew V1.0," for personalized recommendation and ranking tasks, effectively addressing the limitations of traditional ID-based RS models. By substituting feature engineering with prompt engineering, 360Brew highlights the advantages of scaling architectures and data on computational resources. The authors outline a comprehensive training pipeline that harnesses the scalable architecture of a 150B parameter, decoder-only model leveraging advanced pre-training techniques and gaze into the potential of such models in diverse recommendation tasks. While challenges in context length generalization and dependency on active community support for inference frameworks are acknowledged, the research indicates promising avenues for the adaptability and scalability of foundation models for RS tasks in the future.