- The paper proposes a method that compresses long user histories via personalized learnable tokens, reducing inference cost while maintaining accuracy.
- It employs segment-wise token generation and a modified causal attention mask to integrate historical data with recent interactions efficiently.
- Empirical results show comparable recall performance to full-sequence models with inference speed improvements exceeding 75% on large datasets.
Efficient Long-Term Sequential Recommendation via Personalized Experts
Introduction
The challenge of efficiently incorporating long user interaction histories into recommender systems is acute for large-scale applications. Traditional transformer-based sequential recommenders such as HSTU and HLLM have empirically demonstrated that extending sequence length improves recommendation performance. However, the quadratic computational complexity with respect to sequence length presents significant scalability barriers. The paper "Efficient Sequential Recommendation for Long Term User Interest Via Personalization" (2601.03479) proposes a principled approach to decouple sequence length from inference-time cost by compressing historical user interactions into personalized learnable tokens (termed 'personalized experts'). These compressed representations are then combined with short recent contexts for efficient high-quality sequential recommendation.
Scaling Sequential Recommendation Models
Empirical evidence presented establishes that recall metrics for both HSTU and HLLM scale positively with sequence length on the MerRec dataset.
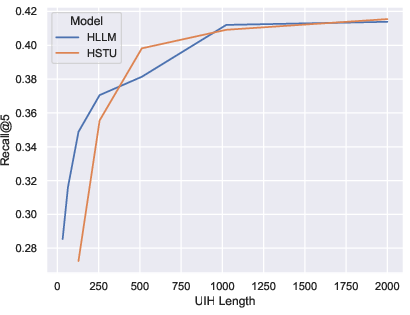
Figure 1: Performance (Recall@5) of HSTU and HLLM models increases as the user interaction sequence length grows, highlighting the importance of long-term history modeling.
Despite this, traditional approaches such as sequence truncation or clustering-based two-stage pipelines (SIM, TWIN, KuaiFormer) suffer from either computation-accuracy tradeoffs or lack of modeling alignment. The proposed method addresses these by maintaining fully end-to-end training and integrating compression operations directly into the model's training and inference procedure.
Methodology
The core proposal is to divide the user's interaction history into manageable segments and compress each segment into a (set of) learnable token(s) using a dedicated segment decoder, which may share parameters with the main model.
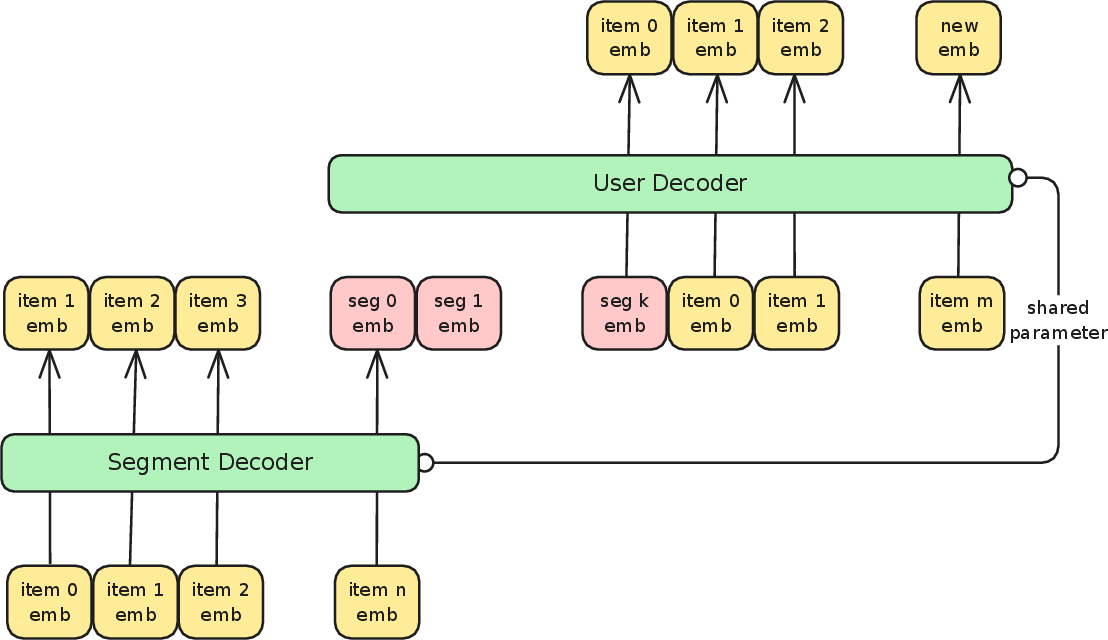
Figure 2: Architecture overview; long sequences are divided into segments, each compressed into segment embeddings (personalized experts) that, concatenated with recent segment item embeddings, enable efficient sequential recommendation.
By appending learnable tokens at segment boundaries and manipulating attention masks, the approach restricts information flow, ensuring tokens only attend to items within the same segment (and previous segment experts), thus enforcing localized compression.
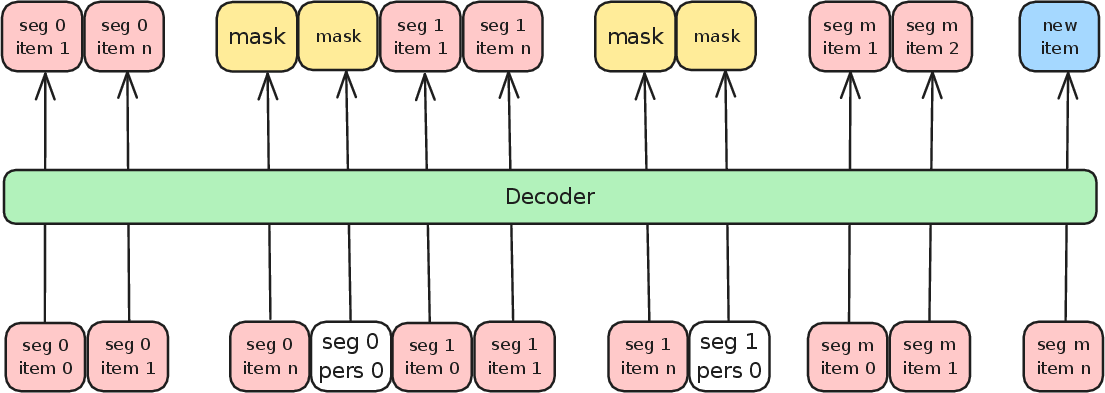
Figure 3: Attention structure for training—each position may attend only to its segment's past and the accumulated learnable tokens, avoiding information leak and ensuring segment-local compression.
This is implemented via a modified causal attention mask that disconnects segments except via their compressed tokens.
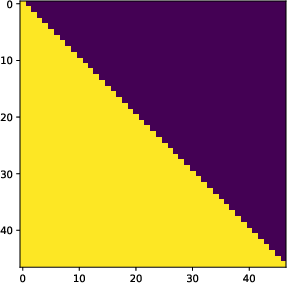
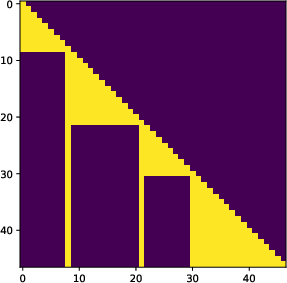
Figure 4: Left: Standard causal attention used for next-item prediction. Right: Segment-wise mask restricting cross-segment attention to pass only through compressed tokens.
Training is performed with a standard next-item prediction loss, omitting the learnable token positions from the loss computation.
Inference uses a progressive scheme: compress past segments once (caching the activations of learnable tokens—effectively a segment-wise KV cache) and use these, together with recent uncompressed events, for downstream predictions.
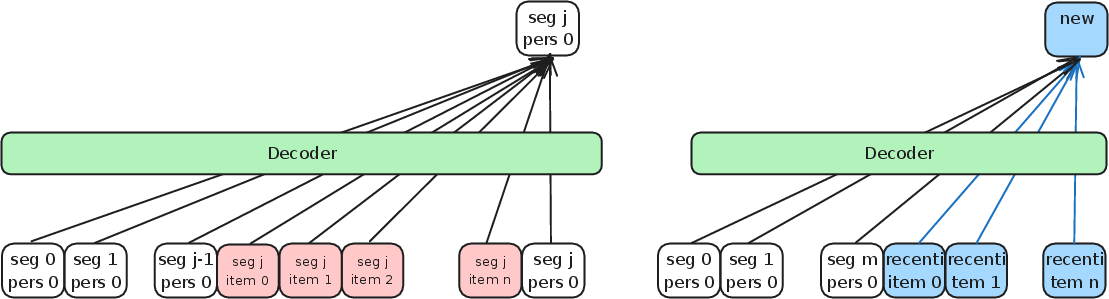
Figure 5: Inference procedure—learnable token activations are cached per segment and used as context for new item prediction, minimizing recomputation.
Computational Complexity
Standard transformer inference cost is O(n2d) per layer for sequence length n and hidden size d. The proposed method reduces the quadratic term by amortizing compression. For n items split into m segments with k total experts, the total computation for inference is approximately:
O(m(n+k)2d)
with k≪n, achieving a significant reduction in wall-clock latency and resource usage, especially when segment compression is reused for multiple predictions.
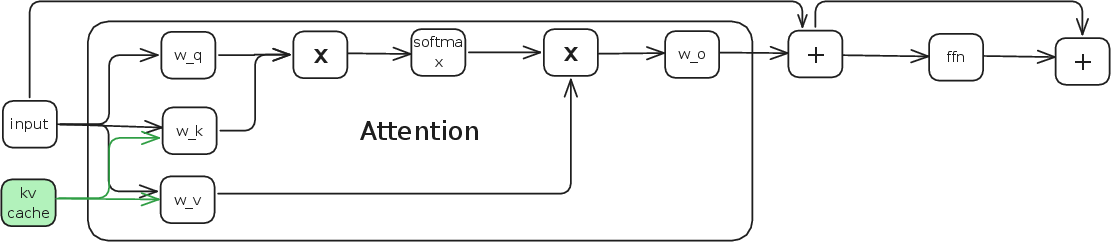
Figure 6: Decoder layer structure demonstrating how cached keys and values (from learnable tokens) are concatenated to contextualize new input at inference.
Empirical Results
Experiments on MerRec and EB-NeRD datasets show that compressing large history segments into a small set of personalized experts, combined with a short "recent" uncompressed context, yields retrieval performance close to (or matching) full-sequence baselines, with dramatic inference speed gains.
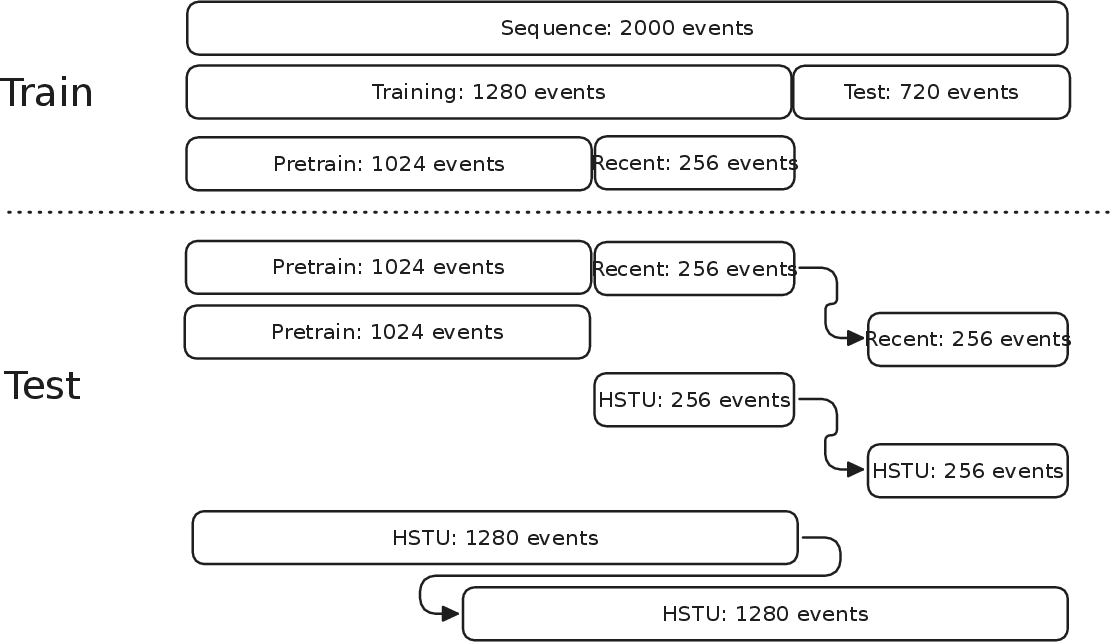
Figure 7: Experimental protocol for temporal distance analysis—performance as recent segment slides farther from the pretrain (expert-generating) segment.
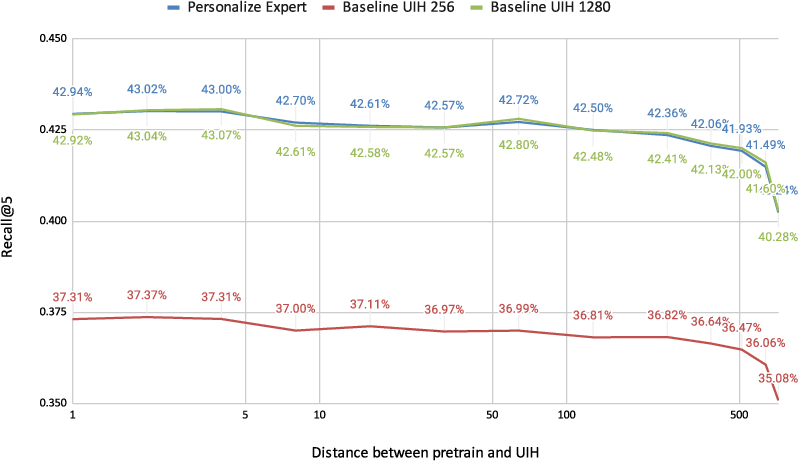
Figure 8: Retrieval performance (Recall@5) versus the temporal gap between recent segment and expert segment; compressed models maintain performance close to full-history baselines regardless of the offset.
Table-based analysis additionally shows:
- Training-time overhead is negligible (<5%);
- Inference-time savings can exceed 75% versus processing full-length sequences;
- The method is robust to the number of experts (except at pathological settings);
- Placement strategy for learnable tokens matters, with all experts placed after a single long pretrain segment performing better than more granular splits.
Analysis of Token Compression
Interpretability investigations show that the learned expert tokens capture salient aspects of historical behavior. Non-negative matrix factorization (NMF) of token activations reveals they are typically linearly spanned by a sparse set of relevant history items, matching the target's semantic characteristics.
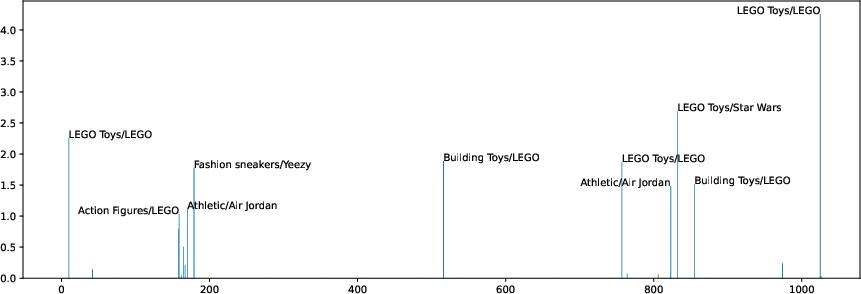
Figure 9: NMF-based visualization demonstrating that learnable experts encode history information closely related to the target, as measured by top-weighted items.
Practical and Theoretical Implications
This work unifies key LLM-based context compression ideas (e.g., SepLLM (Chen et al., 2024), Gist (Mu et al., 2023), AutoCompressor (Chevalier et al., 2023)) with the specific requirements of large-scale recommendation. The approach retains the benefits of long-term history modeling while making sequential models tractable for real-world deployment—an essential property for recommender systems at scale. Notably, the personalized expert framework provides a general mechanism for fixed-cost historical summarization, applicable to both ID-based and content-based architectures.
This also offers a path for integrating pre-computed representations across multimodal or multi-behavior user traces, given the segment-agnostic nature of expert token generation.
Conclusion
The proposed personalized expert compression paradigm enables scalable sequential recommendation, maintaining accuracy comparable to full-sequence models with significantly reduced inference cost. Analysis demonstrates robustness with respect to expert number and placement, and interpretability evidence supports that compressed tokens retain relevant historical signal. This method, being generic, could lay the groundwork for a new class of scalable, personalized, and efficient recommendation systems and contextual LLM architectures for user modeling.
Future work may explore joint multi-behavior or multimodal compression, expert adaptation for continual learning, and extending the caching paradigm to hierarchical contexts for further scalability advances.