HyTRec: A Hybrid Temporal-Aware Attention Architecture for Long Behavior Sequential Recommendation
Abstract: Modeling long sequences of user behaviors has emerged as a critical frontier in generative recommendation. However, existing solutions face a dilemma: linear attention mechanisms achieve efficiency at the cost of retrieval precision due to limited state capacity, while softmax attention suffers from prohibitive computational overhead. To address this challenge, we propose HyTRec, a model featuring a Hybrid Attention architecture that explicitly decouples long-term stable preferences from short-term intent spikes. By assigning massive historical sequences to a linear attention branch and reserving a specialized softmax attention branch for recent interactions, our approach restores precise retrieval capabilities within industrial-scale contexts involving ten thousand interactions. To mitigate the lag in capturing rapid interest drifts within the linear layers, we furthermore design Temporal-Aware Delta Network (TADN) to dynamically upweight fresh behavioral signals while effectively suppressing historical noise. Empirical results on industrial-scale datasets confirm the superiority that our model maintains linear inference speed and outperforms strong baselines, notably delivering over 8% improvement in Hit Rate for users with ultra-long sequences with great efficiency.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making recommendation systems better and faster when they read very long histories of what people do online (like clicks, views, or purchases). The authors introduce a new model called HyTRec that looks at two things at the same time:
- Your long-term tastes (what you usually like).
- Your short-term interests (what you’re suddenly into right now).
The goal is to recommend the next item you’ll want, even if you have thousands or tens of thousands of past interactions.
Key Objectives
The researchers ask:
- How can we use very long user histories without the system becoming too slow?
- How can we keep recommendations precise when a user’s interests change quickly (for example, during a flash sale or a sudden new hobby)?
- Can we balance speed and accuracy by combining different “attention” styles in one model?
“Attention” here means how the model decides what parts of your history to focus on—like a spotlight that highlights the most relevant moments.
Methods and Approach (with simple analogies)
Splitting the user’s history
Imagine your browsing or shopping history as a long timeline. HyTRec splits it into two parts:
- The short-term part: your most recent actions (like the last K items). This catches sudden interest spikes—think of a recent binge of sports shoes.
- The long-term part: everything before that. This shows steady preferences—like loving sci-fi movies for years.
These two parts are processed separately, then combined.
Hybrid attention: two kinds of focus
There are two common “attention” types:
- Softmax attention: very accurate but slow on long sequences because it compares many things with many other things. Think of carefully reading every page in a huge book.
- Linear attention: much faster but can miss fine details when the history is very long. Think of reading the summary instead of the whole book.
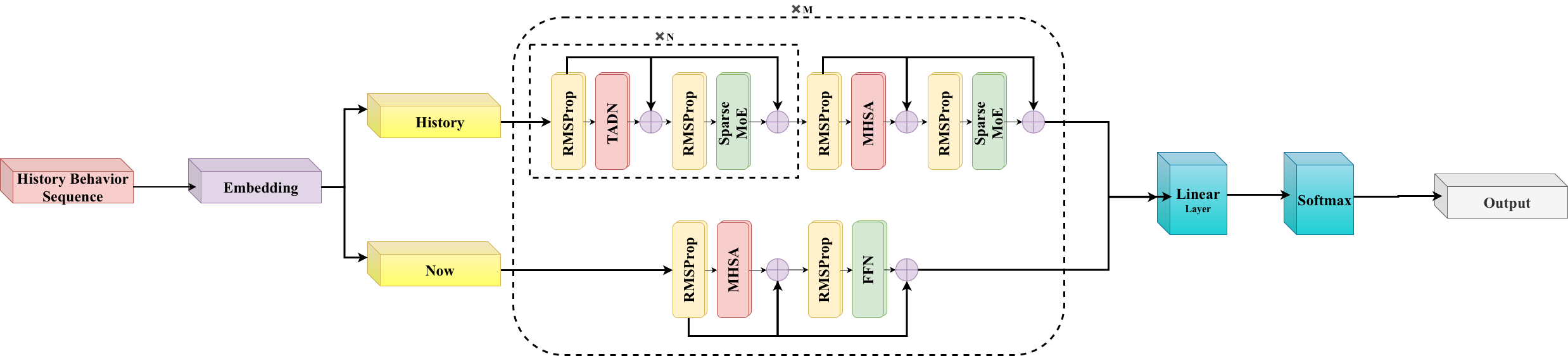
HyTRec uses both:
- Recent actions are handled with softmax attention for precision (so sudden interests are captured clearly).
- Long histories are handled mostly with linear attention for speed (so the model stays fast), with a few softmax layers mixed in to avoid losing important details.
This “hybrid” design tries to get the best of both worlds: fast on big histories, but still precise when it matters.
Temporal-Aware Delta Network (TADN)
People’s interests fade over time. TADN adds a “time-aware” gate—like a volume knob—that turns up the importance of fresh signals and turns down old noise.
Analogy:
- Imagine your playlist: songs you played this week should influence recommendations more than songs you liked years ago.
- TADN uses a time-decay rule (recent actions count more) and blends it with the similarity of items you’ve interacted with. The result is a smart gate that boosts what’s new and relevant and lowers what’s outdated.
Technically, TADN works inside the linear attention part, updating a compact memory of your history while giving extra weight to recent intent. This helps the model react quickly when your interests drift.
Main Findings and Why They Matter
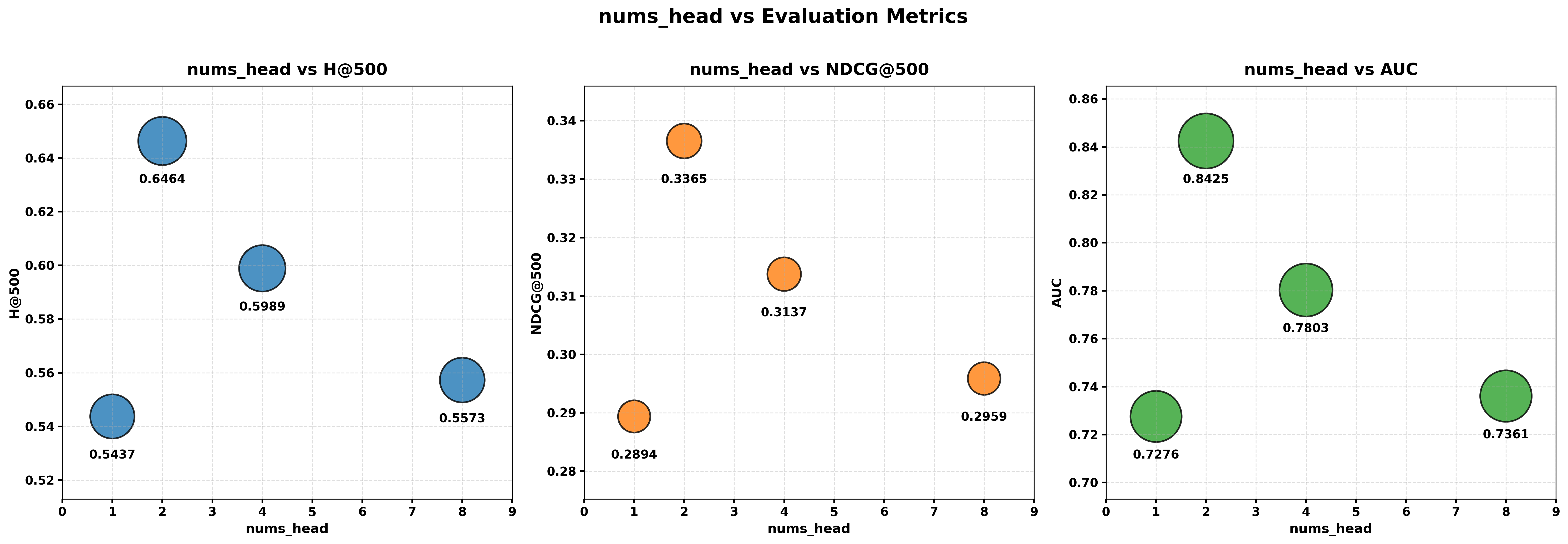
The authors tested HyTRec on large, real-world datasets (like Amazon categories) and against strong baseline models. Key results:
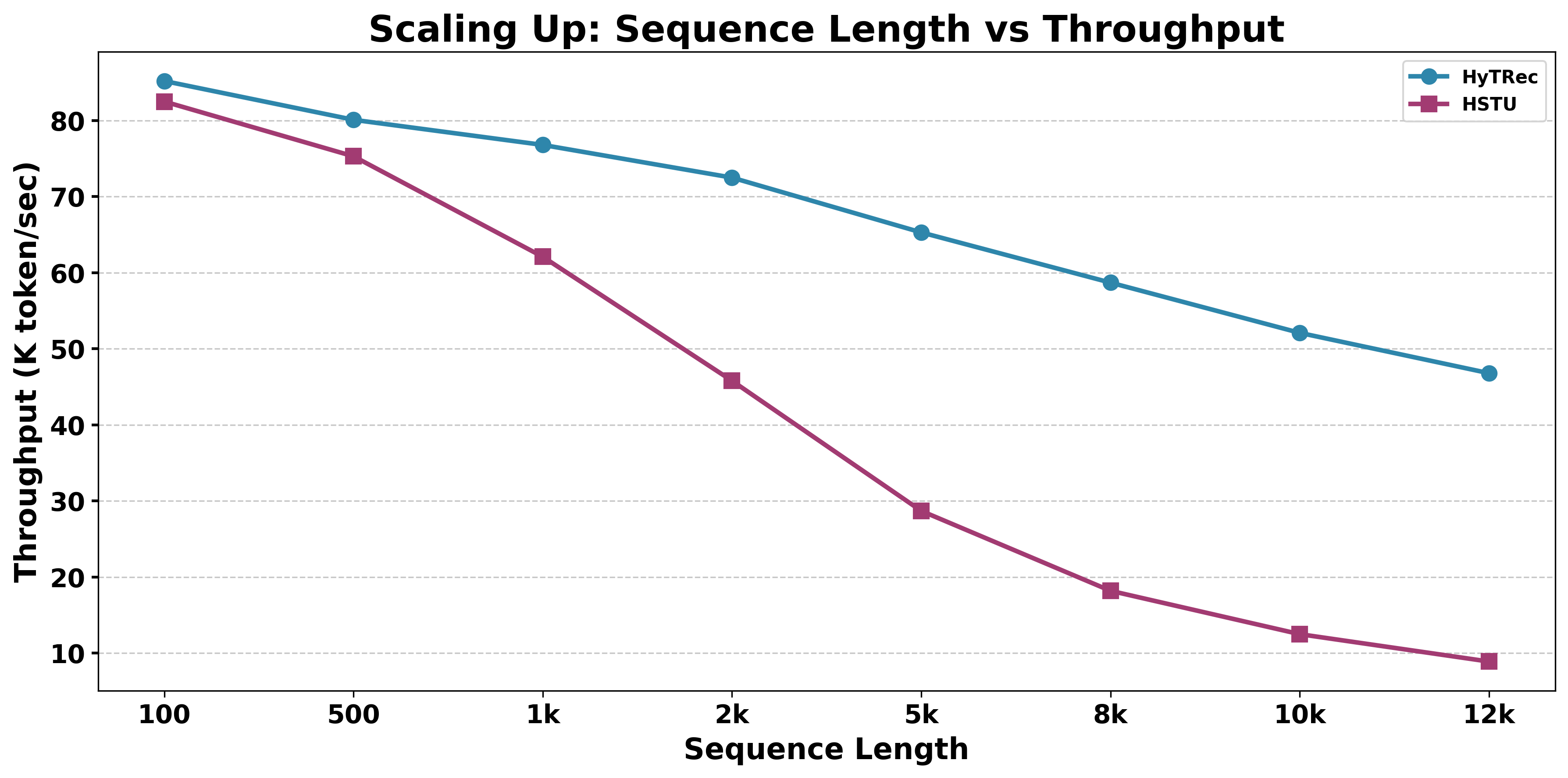
- HyTRec stays fast even when users have ultra-long histories (thousands of interactions), keeping near-linear time as the sequence grows.
- It consistently beats strong baselines on recommendation quality. In industrial-scale settings with very long histories, it delivered over 8% improvement in Hit Rate for those users.
- On average across benchmarks, it improved NDCG (a ranking quality metric) by about 5.8%.
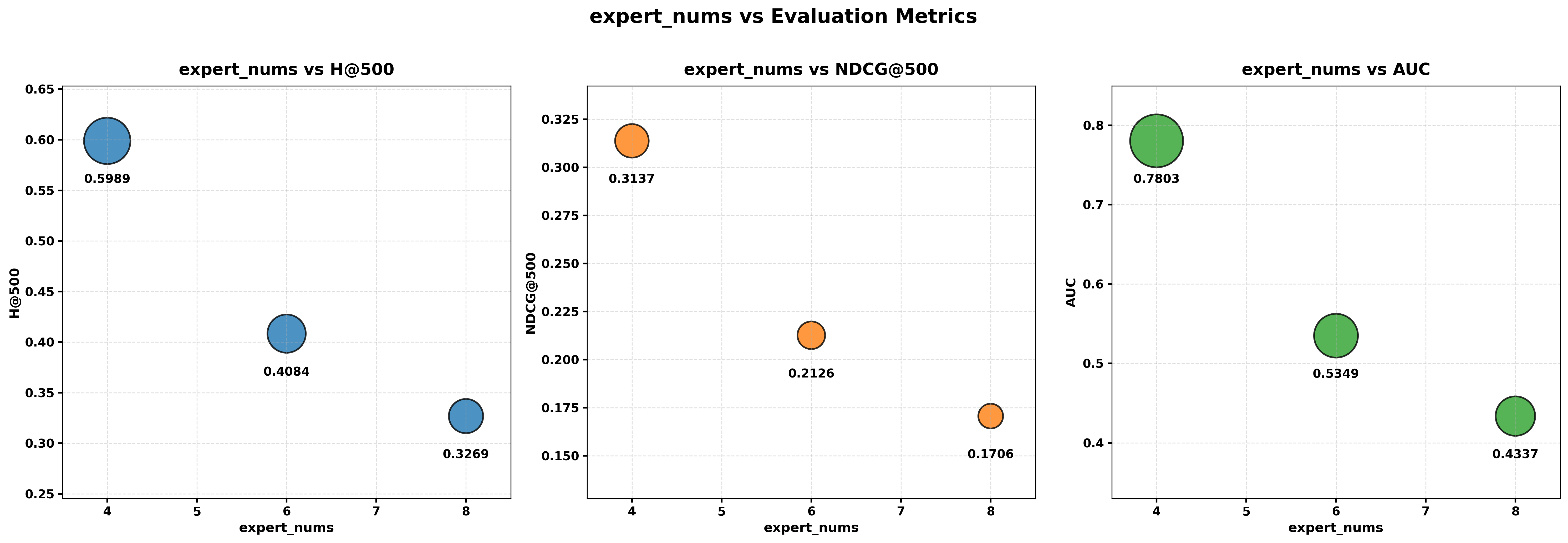
- Ablation studies (turning parts on/off) showed both parts matter: the short-term softmax branch helps catch sudden interests, and TADN in the long-term branch improves overall accuracy. Using both together gives the best results.
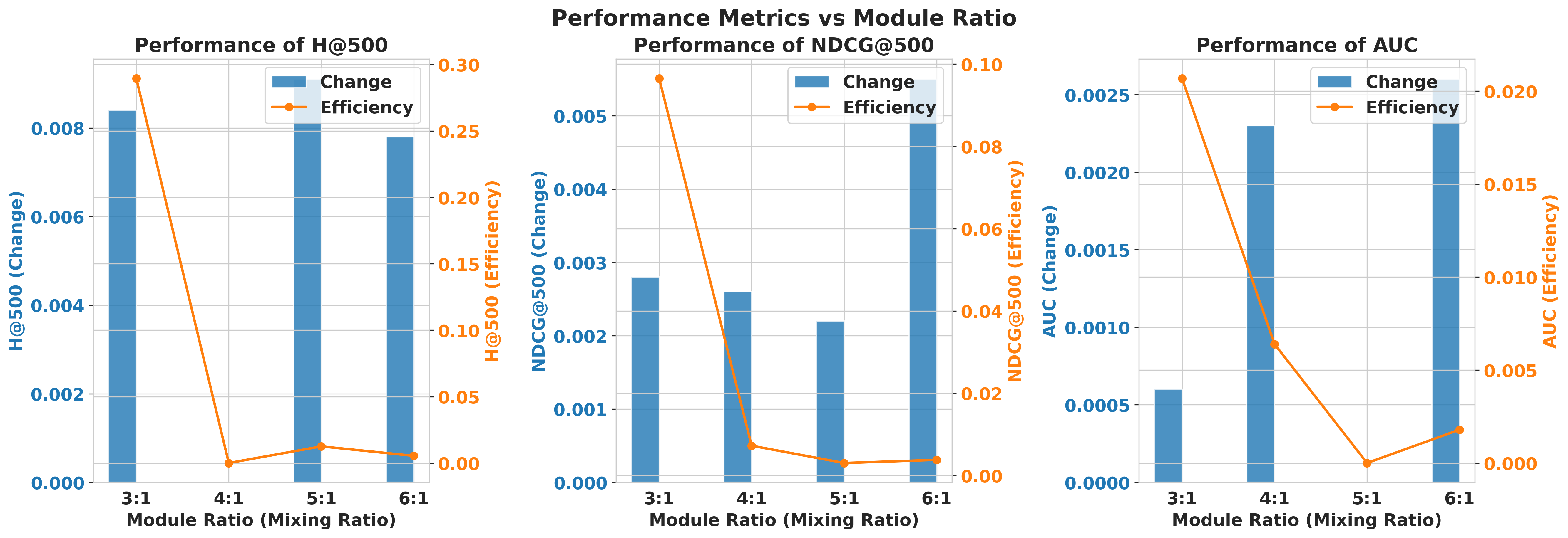
- The mix ratio of “mostly linear with a few softmax layers” affects the trade-off between speed and accuracy. A small number of softmax layers (for example, roughly 3 linear layers to 1 softmax layer in their tests) provided a good balance.
This means HyTRec delivers high-quality recommendations without slowing down, which is crucial for real-time systems.
Implications and Impact
- Better user experience: The system can recommend more relevant items quickly, even if you’ve used the platform for years and have a huge history.
- Industrial practicality: Companies need fast models to respond in milliseconds. HyTRec’s design makes long-history modeling feasible in production.
- Robust to changing tastes: By upweighting recent behavior, HyTRec adapts faster when your interests shift.
- Generalization potential: The approach can help in different domains (e-commerce, media, ads) and in tough scenarios like cold-start (with help from similar users’ patterns).
In short, HyTRec shows a smart, efficient way to read your long “story” of actions while paying close attention to what’s hot right now—leading to better, faster recommendations.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete gaps that, if addressed, could strengthen the paper’s claims and guide follow-up research.
- Unspecified fusion mechanism: The paper does not describe how outputs from the short-term softmax branch and the long-term TADN branch are fused (e.g., concatenation, gating, attention over branches, learned weights). Provide the exact operator, learned parameters, and an ablation on fusion choices.
- Temporal decay hyperparameter T: It is unclear whether the decay period T is fixed, learned, per-user, per-item, or context-dependent, and what time units are used. Add a sensitivity study and alternative parameterizations (e.g., learnable per-user T, piecewise decay, Hawkes-like kernels).
- Handling missing/irregular timestamps: The method assumes well-formed timestamps and a clear t_current. Describe how missing, noisy, batched, or irregular event times are handled; quantify robustness to timestamp jitter and time-zone issues.
- Gate dimensionality and shapes: The formulation of g_t alternates between scalar and vector roles (e.g., in S_t update). Precisely define the dimensionality of g_t, k_t, v_t, and S_t, and how broadcasting is implemented; provide a reference implementation to resolve ambiguity.
- Mathematical correctness and notation errors: Several equations have mismatched parentheses/braces and undefined symbols (e.g., τ_t, Δh_t, h̄, g_static). Provide corrected derivations, proofs of stability, and a clear mapping from notation to implementation.
- Theoretical guarantees: The paper claims restored retrieval fidelity but provides no formal analysis. Offer theoretical bounds or formal arguments on injectivity/expressivity for the hybrid stack and conditions under which TADN mitigates semantic confusion.
- Complexity and memory characterization: “Near-linear” claims lack concrete constants. Report per-layer FLOPs, memory footprint, cache/state size, and end-to-end latency vs. sequence length, batch size, and hybrid ratio; include peak memory and throughput at deployment-relevant batch sizes.
- Hybrid ratio inconsistency and rationale: The text mentions 7:1 (TADN:softmax) while experiments assess 2:1–6:1. Resolve the inconsistency, specify what the ratio measures (per-block count, interleave pattern), and provide a principled selection strategy (e.g., scaling law or adaptive routing).
- Short-term window size K: K is fixed but its selection criterion, sensitivity, and potential per-user adaptivity are not studied. Evaluate K across datasets, sequence lengths, and interest-drift intensities; explore adaptive K learned from data.
- Loss/objective and candidate set: The training objective (pointwise/batch softmax/listwise), negative sampling strategy, and candidate generation for H@500/AUC are unspecified. Detail the loss, sampled vs. full-ranking evaluation, and their effect on reported metrics.
- “Generative” vs. discriminative setup: Although framed as generative recommendation, experiments appear to use discriminative ranking metrics. Clarify whether the model generates item IDs autoregressively, how the vocabulary is constructed, and how generation is evaluated (e.g., log-likelihood, perplexity, top-k accuracy).
- Baseline coverage and fairness: Important long-sequence baselines (e.g., SIM, ETA, S4/Mamba-based recommenders, recent retrieval-augmented methods) are referenced but not evaluated. Expand baselines and ensure matched compute with transparent FLOPs, depth/width, and training steps.
- Metrics and inconsistencies: The use of H@500 is non-standard for recsys comparisons; report standard top-k (e.g., Recall@10/20, NDCG@10/20). Resolve discrepancies between claims (e.g., “average +5.8% NDCG”) and Table values where HyTRec’s NDCG lags some baselines.
- Statistical significance and variance: No confidence intervals or significance tests are reported. Include multiple seeds, variance bars, and paired tests to support claims.
- Dataset preprocessing transparency: Filtering thresholds, sequence truncation rules, deduplication, and time-aware train/val/test splits are not specified. Provide full preprocessing details to assess leakage risks and reproducibility.
- Cold-start augmentation procedure: The “similar-user augmentation” used for cold-start/silent users is underspecified (similarity metric, neighbor count, safeguards against leakage, ablation vs. no augmentation). Detail the method and its effect on non-cold users.
- Robustness to noise and distribution shift: Beyond future work, there is no empirical robustness evaluation (noisy clicks, bot traffic, out-of-order events, label noise). Add stress tests and noise ablations; evaluate under domain/time drift.
- Online/streaming deployment: The paper does not specify how user states are maintained across sessions (state caching, eviction, update cost), per-user memory budget, or incremental update latency. Provide an online inference design and benchmarks.
- Interpretability of temporal gating: No analysis of whether g_t aligns with human-understandable recency patterns. Visualize gate trajectories, measure calibration, and test causal impact via counterfactual timestamp perturbations.
- Personalization of temporal dynamics: g_t and T appear global. Explore personalized decay (per-user/per-category), learned time-scales, and content-aware modulation (e.g., durable vs. fad items).
- Multi-interest modeling: The hybrid design does not explicitly disentangle multiple concurrent intents. Compare/augment with multi-interest extractors (e.g., MIND/ComiRec) and quantify gains or redundancy.
- Side information and item cold-start: The approach uses only ID sequences; there is no integration of content (text/image), attributes, or graph context to handle item/user cold-start. Assess TADN in multimodal or feature-rich settings.
- Decoupled embeddings: The related work highlights decoupled embeddings for long sequences, but the model’s embedding design is unspecified. Evaluate decoupled vs. shared embeddings and their impact on long-range capacity.
- Calibration of TADN vs. softmax layers: No ablation disentangles the temporal factor from the gate (e.g., TADN with τ_t removed vs. ALiBi vs. learned positional biases) or compares to pure-softmax/pure-linear stacks under equal compute.
- Scaling limits: Experiments show sequences up to 12k on a single V100, but scalability to 50k–100k tokens, multi-GPU training, and memory-bandwidth bottlenecks are not characterized.
- Cross-domain generalization: Cross-domain results compare only to SASRec on a single dataset with unusually large gains (GAUC jump from ~0.42 to ~0.88). Validate across multiple domains, stronger baselines, and standardized protocols.
- Reproducibility: Critical implementation details (hyperparameters, optimizer/schedule, seeds, batch sizes, early stopping) and code/data release plans are missing. Provide artifacts for verification.
- Fairness and bias: There is no analysis of performance across user groups (activity level, demographics if available) or potential unintended biases introduced by decay and filtering. Add subgroup evaluations and fairness diagnostics.
- Energy/latency trade-offs: Latency is discussed qualitatively; detailed p50/p90/p99 latency, energy per inference, and throughput under production-like loads are not reported. Provide standardized efficiency metrics.
- Safety and feedback loops: The effect of recency upweighting on echo chambers or overexposure to transient trends is not studied. Propose mitigation (e.g., diversity/novelty constraints) and evaluate their interplay with TADN.
- Notation and dataset name errors: Typos (e.g., Movies{paper_content}TV) and broken LaTeX hinder clarity. Provide an erratum and consistent naming to avoid ambiguity in replication.
These gaps suggest clear next steps: formalize the method specification and theory, broaden and standardize evaluation, expose deployment details, and test robustness, fairness, and scalability under practical constraints.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, derived directly from the paper’s findings on hybrid attention and temporal-aware gating for long behavior sequences.
- Ecommerce: ultra-long sequence product recommendation and feed ranking
- What: Use HyTRec as the next-item predictor and re-ranker for users with thousands to tens of thousands of interactions, combining linear attention for long-term preferences with softmax attention on the latest K events for sharp short-term intent capture.
- Sector: Retail/ecommerce
- Tools/products/workflows:
- “HyTRec Re-Ranking” module after candidate generation (e.g., SIM/ETA, ANN/KNN)
- Sequence splitter middleware that maintains two views: S_long and S_short
- Request-Level Batching (RLB) with sparse training and dense inference
- Hybrid-layer scheduler (start with the empirically efficient 3:1 or 7:1 linear:softmax ratio and tune)
- Assumptions/dependencies:
- High-quality, timestamped user-event logs and robust item embeddings
- Long behavior sequences are available and cleaned (de-duplication, noise handling)
- Latency budgets that can exploit HyTRec’s near-linear inference; compatible serving infra (GPU/CPU)
- Digital advertising: real-time targeting, CTR/CVR optimization
- What: Deploy HyTRec in ad retrieval and ranking to blend durable interest signals with recent spikes (e.g., campaign launches, flash sales), supported by paper’s cross-domain transfer results.
- Sector: Advertising/marketing tech
- Tools/products/workflows:
- Plug-in ad-ranking model with TADN gating for recency
- A/B testing harness monitoring GAUC/AUC and latency
- Feature store with recency-aware decay for ad interactions
- Assumptions/dependencies:
- Frequent, reliable impression/click/conversion timestamps
- Access to cross-domain signals if transferring from one vertical to another; domain fine-tuning
- Streaming media and news recommendation: trend-sensitive personalization
- What: Improve watch-next/read-next models by decoupling long-term taste (genres, creators) from short-term spikes (trending shows, breaking news).
- Sector: Media/entertainment
- Tools/products/workflows:
- Temporal-aware gating for event-time features
- Hybrid attention layer interleaving for large watch histories; on-demand ratio tuning to meet peak-load latency
- Assumptions/dependencies:
- Granular content metadata; precise session boundaries and timestamps
- Latency SLAs compatible with near-linear attention inference
- Search and marketplace re-ranking (query-less and query-aware feeds)
- What: Use HyTRec as a re-ranking layer that emphasizes recent interactions (e.g., last K clicks) without losing the signal from lifetime engagement.
- Sector: Retail marketplaces, classifieds, travel, real estate
- Tools/products/workflows:
- Two-branch inference: linear branch over lifetime interactions, softmax branch over most recent K items
- Integration with existing retrieval stack (BM25/ANN) as a second-stage re-ranker
- Assumptions/dependencies:
- Efficient candidate generation upstream; stable item representations
- Exposure bias monitoring and calibration
- Cold-start and silent-user handling via similar-user augmentation
- What: Apply the paper’s strategy to augment sparse histories using neighbors (users with similar interests), then run HyTRec to enhance hit rate and NDCG without heavy latency penalties.
- Sector: All consumer platforms with intermittent or new users
- Tools/products/workflows:
- Similar-user retrieval service (clustering/ANN over user embeddings)
- Lightweight augmentation policy (limits on borrowed interactions; recency-aware filters)
- Assumptions/dependencies:
- Accurate user embedding space; guardrails to avoid data leakage or unfairness
- Monitoring for overfitting to dominant cohorts
- Cost and latency optimization of recommender stacks
- What: Replace full softmax attention models with HyTRec in long-sequence stages to maintain accuracy while cutting quadratic costs, validated by throughput results (e.g., 12k-length sequences).
- Sector: Platform engineering/infra
- Tools/products/workflows:
- Hybrid layer auto-tuner targeting H@NDCG vs. latency trade-offs (paper suggests 3:1 as a strong default)
- Model distillation from quadratic baselines to HyTRec
- Assumptions/dependencies:
- Comparable compute budget and serving stack; careful FLOP/runtime alignment in offline evaluation
- Sufficient GPU/CPU memory bandwidth for long-sequence linear state updates
Long-Term Applications
These applications are plausible extensions that require further research, scaling, or productization before broad deployment.
- Unifying retrieve-and-rank under generative recommenders at industrial scale
- What: Use HyTRec as the efficient backbone that enables “OneRec-like” iterative preference alignment in trillion-parameter, long-context generative frameworks without violating latency SLAs.
- Sector: Ecommerce, ads, media
- Tools/products/workflows:
- Managed “HyTRec-in-the-loop” for LLM-based recommenders
- Iterative preference alignment pipelines with hybrid attention
- Assumptions/dependencies:
- Robust alignment of generative models with recommendation objectives
- Significant engineering for streaming context ingestion and online learning
- Conversational recommendation with long memory
- What: Integrate HyTRec as the memory module for conversational agents so dialogues exploit lifelong histories while staying responsive to the most recent conversational intent.
- Sector: Software, customer support, retail
- Tools/products/workflows:
- Memory-augmented dialogue manager (HyTRec/TADN for historical context + short-term turn-level intent)
- Safety and preference-tracking layers
- Assumptions/dependencies:
- Reliable user consent, privacy-preserving storage; dialog-state tracking and grounding
- On-device privacy-preserving personalization
- What: Move HyTRec’s linear inference components to user devices (phones/TVs) to reduce server-side data exposure and support edge personalization.
- Sector: Consumer devices, smart TVs, mobile apps
- Tools/products/workflows:
- Edge model package with quantization/pruning and temporal-aware gating
- Federated learning or split learning for updates
- Assumptions/dependencies:
- Sufficient device compute; robust model compression and update protocols
- Local storage policies and permissioned data access
- Cross-domain and cross-scenario transfer recommendation
- What: Generalize HyTRec from ecommerce to ads, media, and beyond using transfer learning and domain-adaptive temporal gating.
- Sector: Multi-vertical platforms, B2B SaaS
- Tools/products/workflows:
- Domain-adaptive decoupled embeddings and time-decay schedules
- AutoML-driven ratio selection for hybrid attention per domain
- Assumptions/dependencies:
- Availability of labeled behavioral sequences; mitigation of domain shift and covariate shift
- Continuous evaluation on GAUC/AUC/H@NDCG with fairness checks
- Real-time interest drift detection for pricing and promotion engines
- What: Leverage TADN’s temporal decay and gating to detect ephemeral intent shifts (e.g., event-driven demand spikes) and feed signals to dynamic pricing or promotion systems.
- Sector: Retail, travel, ride-hailing, food delivery
- Tools/products/workflows:
- Drift detectors on top of gating weights; policy engine linking drift magnitude to price/promo actions
- Assumptions/dependencies:
- Causal validation to avoid spurious promotions; guardrails against price discrimination risks
- Extending to non-recommendation sequence tasks
- What: Adapt the temporal-aware hybrid attention scheme to tasks like session-based fraud detection, long-horizon user churn prediction, or IoT telemetry anomaly detection.
- Sector: Finance (fraud), telecom, IoT
- Tools/products/workflows:
- Task-specific heads (classification/regression) on top of HyTRec/TADN encoders
- Event-time feature pipelines and decay calibration
- Assumptions/dependencies:
- Suitable labels and evaluation metrics (e.g., F1/AUROC), domain-specific feature engineering
- Open-source hybrid temporal-attention toolkit
- What: Package a reusable library implementing sequence decomposition, TADN gating, hybrid-layer scheduling, and ratio auto-tuning compatible with Mamba/GLA/DeltaNet stacks.
- Sector: Academia and industry R&D
- Tools/products/workflows:
- “hytrec” Python library; integration adapters for PyTorch/JAX
- Benchmark suite for long-sequence rec under matched FLOPs and latency
- Assumptions/dependencies:
- Community adoption; standardized datasets and reproducible pipelines
- Policy-aligned personalization with time-decay defaults
- What: Use temporal decay and gating to operationalize data minimization (older events carry less weight by design), with auditable decay schedules for compliance and fairness reviews.
- Sector: Policy/regulatory compliance, platform governance
- Tools/products/workflows:
- Governance dashboards exposing decay parameters and impact on outcomes
- Consent-aware retention policies and transparency reports
- Assumptions/dependencies:
- Legal counsel review; robust privacy engineering; mechanisms to detect and mitigate disparate impact across user cohorts
Glossary
- ALiBi: A method that adds linear position-based biases to attention scores to help models generalize to longer inputs. "Techniques such as ALiBi \cite{press2021train} utilize static linear biases to weight local context effectively"
- Area Under the Curve (AUC): A metric measuring ranking quality by the probability that a randomly chosen positive is ranked above a randomly chosen negative. "We adopt H@500, NDCG@500, and AUC as metrics"
- Causal settings: Sequence modeling setups that only allow information to flow from past to future to maintain causality. "For causal settings, linear attention can be implemented with recurrent state updates"
- Cold-start: The challenge of making recommendations for users or items with little to no historical data. "such as the cold-start phase for new users?"
- Cross-domain transfer: Evaluating or adapting a model trained in one domain to perform in a different domain. "Cross-domain transfer experiments based on the 2022 Huawei Advertising Challenge Dataset."
- Delta rule: An incremental update rule used to adjust a state or memory based on current input signals. "from the standard delta rule"
- Decoupled embeddings: Separating embedding spaces or parameters to avoid capacity bottlenecks in ultra-long sequences. "necessitating the use of decoupled embeddings to preserve model capacity"
- Exponential gating mechanism: A multiplicative gate using exponential terms (e.g., time decay) to weight signals dynamically. "an exponential gating mechanism to dynamically upweight fresh behavioral signals"
- GAUC: Grouped AUC; an AUC variant aggregated across user groups to evaluate ranking across heterogeneous populations. "Recall@10, GAUC and AUC metrics."
- Gated DeltaNet: A linear attention/state-update framework that uses gates to control memory writing and decay. "Unlike standard Gated DeltaNet where decay is purely semantic"
- Gated Linear Attention (GLA): A linear-time attention formulation augmented with gates to modulate information flow. "we compare Transformer, GLA, and Qwen-next (2 blocks)"
- Generative recommendation: Framing recommendation as a generative task, often leveraging language-modeling paradigms. "has emerged as a critical frontier in generative recommendation"
- Hybrid Attention: An architecture combining different attention types (e.g., softmax and linear) to balance precision and efficiency. "a Hybrid Attention architecture that explicitly decouples long-term stable preferences from short-term intent spikes"
- Inference latency: The time it takes a model to produce predictions at serving time. "the practical deployment of generative recommendation is severely constrained by inference latency"
- Injectivity: The property of mappings being one-to-one; in this context, maintaining distinct hidden states without collapsing information. "resulting in semantic ambiguity and limited injectivity"
- Interest drifts: Rapid changes in user preferences over time that models must track and adapt to. "adapt to interest drifts"
- Kernel-based approximations: Techniques that approximate softmax attention using kernel features to reduce complexity. "utilized kernel-based approximations"
- Kernelization: Reformulating attention using kernel feature maps to enable linear-time computation. "typically via kernelization and reordering matrix multiplications"
- LLMs: Large-scale pretrained models that process and generate text, increasingly adapted for recommendation tasks. "inspired by LLMs"
- Linear attention: Attention mechanisms with linear complexity that avoid forming the full attention matrix to improve scalability. "linear attention mechanisms achieve efficiency at the cost of retrieval precision"
- Linear complexity O(n): Algorithmic complexity that scales linearly with sequence length. "achieved strict linear complexity "
- Locality Sensitive Hashing (LSH): A hashing technique that preserves similarity, used for efficient retrieval in large spaces. "utilizes Locality Sensitive Hashing for end-to-end processing"
- Markov Chains: Probabilistic models capturing state transitions with memory limited to the previous state. "Early methodologies primarily utilized Markov Chains for short-term transitions"
- Multi-Head Self-Attention (MHSA): A Transformer mechanism that attends to different representation subspaces in parallel. "using standard multi-head self-attention (MHSA) to ensure maximum precision for recent behaviors"
- NDCG@500: Normalized Discounted Cumulative Gain at rank 500; measures ranking quality with position-based discounting. "We adopt H@500, NDCG@500, and AUC as metrics"
- Quadratic complexity: Computational cost that scales with the square of sequence length, typical of standard self-attention. "traditional softmax attention suffers from quadratic complexity"
- Recall@10: The fraction of cases where the true item appears in the top 10 predictions. "Recall@10"
- Request Level Batching (RLB): A serving strategy batching multiple requests together to improve throughput. "and adopt Request Level Batching (RLB) with sparse training and dense inference"
- Semantic ambiguity: Blurring or loss of precise distinctions in representations, harming retrieval fidelity. "resulting in semantic ambiguity and limited injectivity"
- Semantic dilution problem: The tendency of long-sequence models to weaken important signals as history grows. "semantic dilution problem common in long-sequence modeling"
- Sequence FLOPs: Floating point operations required per input sequence, used to compare computational budgets. "the per-sample sequence FLOPs"
- Sparse attention: Attention patterns that limit interactions to a subset of tokens to reduce cost. "introduced sparse attention patterns"
- State Space Models (SSMs): Sequence models that maintain a latent state updated over time, enabling long-context processing. "State Space Models such as S4 \cite{gu2021efficiently} and Mamba \cite{gu2023mamba}"
- Target-to-History Cross Attention (STCA): An attention pattern that conditions a target on historical context, often stacked for efficiency. "Stacked Target-to-History Cross Attention (STCA)"
- Temporal-aware decay mask: A decay term embedded in attention that downweights older contributions based on time. "a linear attention operation with a temporal-aware decay mask"
- Temporal decay factor: A function that reduces the influence of past interactions as they become older. "We define the temporal decay factor to measure the relevance of a past interaction to the current decision:"
- Temporal-Aware Delta Network (TADN): A linear attention/state-update module that uses time-aware gating to emphasize recent signals. "we incorporate a Temporal-Aware Delta Network (TADN)"
- Throughput: The processing rate (e.g., tokens per second) during training or inference. "We compare the training throughput of models"
- Two-stage search-based strategy: A retrieval approach that first narrows candidates then refines ranking for efficiency. "which employs a two-stage search-based strategy"
- Ultra-long behavioral sequence scenarios: Settings where user histories span thousands of interactions, stressing model scalability. "ultra-long behavioral sequence scenarios"
Collections
Sign up for free to add this paper to one or more collections.