- The paper presents a novel recommendation framework that uses Chain-of-Thought tokenization and journey-aware sparse attention to enhance interpretability and modeling of user behaviors.
- The methodology strategically reduces computational overhead by up to 48%, enabling efficient processing of longer and more complex user interaction sequences.
- Experimental results demonstrate significant performance gains, with improvements up to +106.9% HR@10 and +106.7% NDCG@10, underscoring its practical impact.
GRACE: Generative Recommendation via Journey-Aware Sparse Attention on Chain-of-Thought Tokenization
Introduction
The paper "GRACE: Generative Recommendation via Journey-Aware Sparse Attention on Chain-of-Thought Tokenization" (2507.14758) presents a novel approach to address challenges in multi-behavior sequential recommendation systems. It identifies three main problems limiting current generative models: lack of explicit token reasoning, high computational costs due to dense attention mechanisms, and limited multi-scale modeling over user histories. GRACE introduces two key innovations to overcome these obstacles: Chain-of-Thought (CoT) tokenization and Journey-aware Sparse Attention (JSA). These advances aim to enhance interpretability, efficiency, and the expressive capability of generative recommendation models.
Methodology
GRACE's architecture integrates hybrid tokenization and sparse attention strategies to improve recommendation accuracy and computational efficiency.
Chain-of-Thought Tokenization: This technique enriches semantic tokenization with explicit attributes like category, brand, and price extracted from product knowledge graphs. By forming a hierarchical Chain-of-Thought path, GRACE enables an interpretable and behavior-aligned generation of user-item interaction sequences.
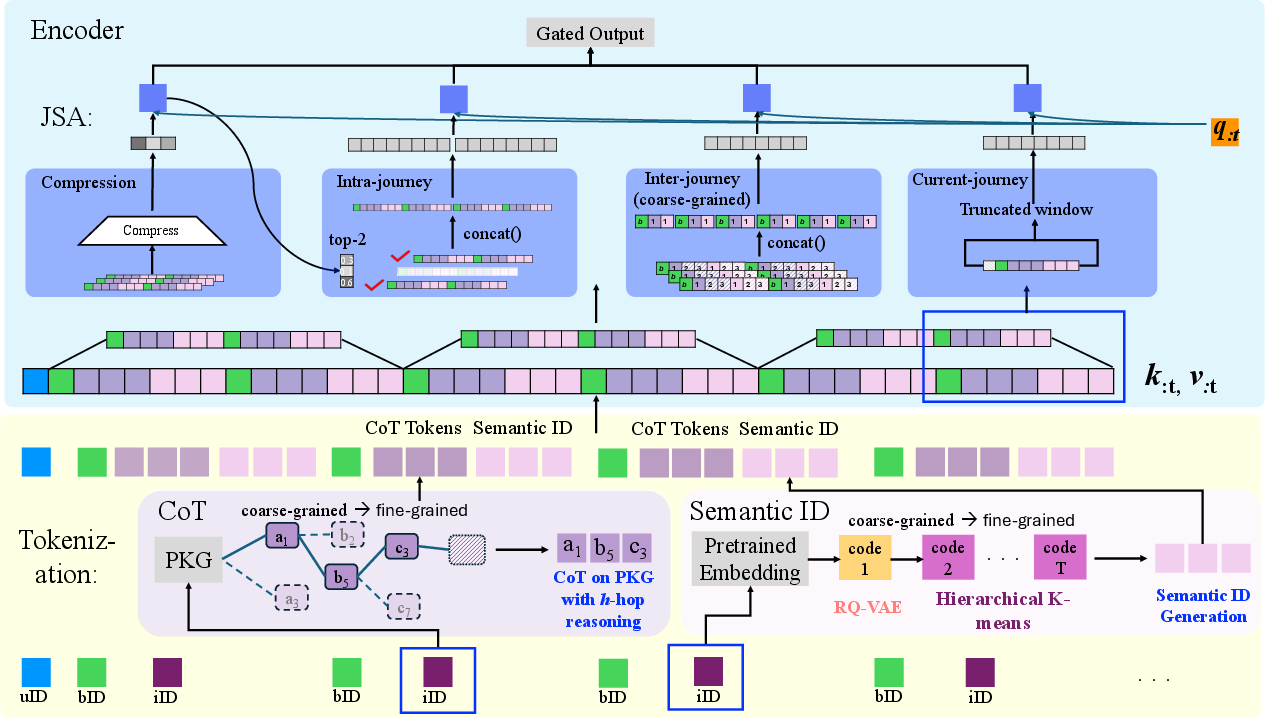
Figure 1: Illustration of GRACE framework with Hybrid Tokenization and Journey-aware Sparse Attention (JSA). Hybrid Tokenization (bottom) contains Chain-of-Thought tokens and semantic IDs. The JSA (top) is a combination of compression, intra-journey, inter-journey, and current-journey attentions.
Journey-aware Sparse Attention: To overcome the inefficiencies of full attention mechanisms, GRACE employs JSA, which selectively attends to compressed, intra-journey, inter-journey, and current-context segments of tokenized sequences. This strategic decomposition allows GRACE to focus computational resources on the most pertinent tokens for recommendation tasks, reducing attention computation up to 48% in long sequences.
Results and Analysis
GRACE demonstrates substantial improvements over baseline models in experiments conducted on real-world datasets from Walmart. It significantly outperforms state-of-the-art models, achieving up to +106.9% HR@10 and +106.7% NDCG@10 improvements in the Home domain, and +22.1% HR@10 in the Electronics domain.
The results also reveal the hybrid tokenization scheme's contribution to accurately capturing user shopping journeys, which traditional models struggle to express comprehensively. GRACE's JSA mechanism facilitates efficient handling of longer and more complex user interaction sequences without sacrificing accuracy.
Hyper-parameter Evaluation: Sensitivity analysis on parameters like window size for current-journey attention and beam width during inference further confirms GRACE's robustness. Optimal values ensure both effective sequence modeling and manageable computational overhead.

Figure 2: Hyper-parameter analysis
Computational Efficiency
GRACE's JSA achieves significant computational savings, reducing activated parameters by up to 48% compared to full attention solutions at longer sequence lengths. This efficiency stems from JSA's ability to dynamically allocate attention based on token relevance, addressing the quadratic growth problem inherent in dense attention mechanisms.
Multi-behavior Recommendation
In finer-grained evaluations, GRACE outperforms existing methods in modeling diverse user behaviors such as clicks, likes, and add-to-cart actions. By leveraging CoT tokenization, GRACE enhances its capability to predict complex user intents across varied product types, significantly improving recommendation quality.
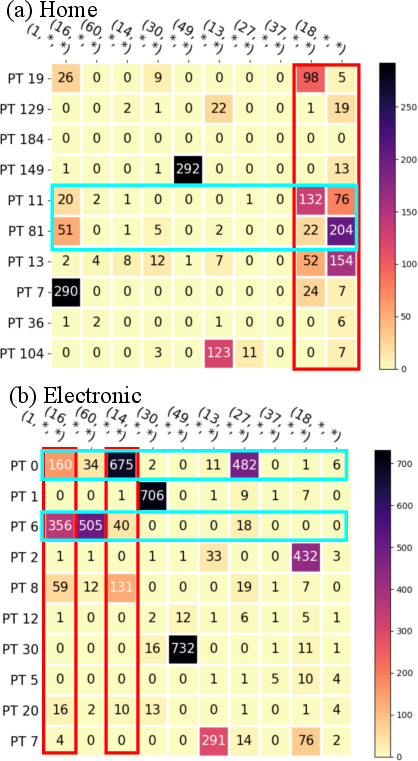
Figure 3: CoT-PT and L1 tokens co-occurrence heatmap.
Conclusion
GRACE represents a significant advancement in generative recommendation models, addressing long-standing challenges through innovative tokenization and attention designs. Its ability to integrate behavioral and semantic signals via CoT tokenization, coupled with the efficient JSA mechanism, marks a substantial leap in both practical applicability and theoretical understanding of next-generation recommender systems. Future developments may focus on extending GRACE's principles to broader applications, integrating richer contextual data, and refining sparse attention strategies to capture evolving user patterns in real-time.