- The paper introduces a contrastive framework that fuses text, image, collaborative, and spatial data to produce unified semantic item identifiers.
- The paper employs a soft residual quantization with Gumbel-softmax relaxation, enhancing item discrimination and mitigating representation collapse.
- The paper demonstrates a 15% improvement in Recall@1000 on large-scale datasets, underscoring its scalability and effective cross-modal fusion.
SimCIT: A Contrastive Framework for Multi-modal Item Tokenization in Generative Recommendation
Introduction
This paper presents SimCIT, a contrastive learning-based framework for item tokenization tailored to generative recommendation systems. The motivation stems from the limitations of reconstruction-based quantization methods (e.g., RQ-VAE), which focus on independent embedding reconstruction and often fail to optimize for discriminative item differentiation required in generative retrieval. SimCIT leverages multi-modal item information—text, image, collaborative signals, and spatial relationships—integrating them via a learnable attention mechanism and aligning them through a contrastive loss. This approach yields semantic item identifiers that are both compact and highly discriminative, facilitating efficient and effective generative recommendation.
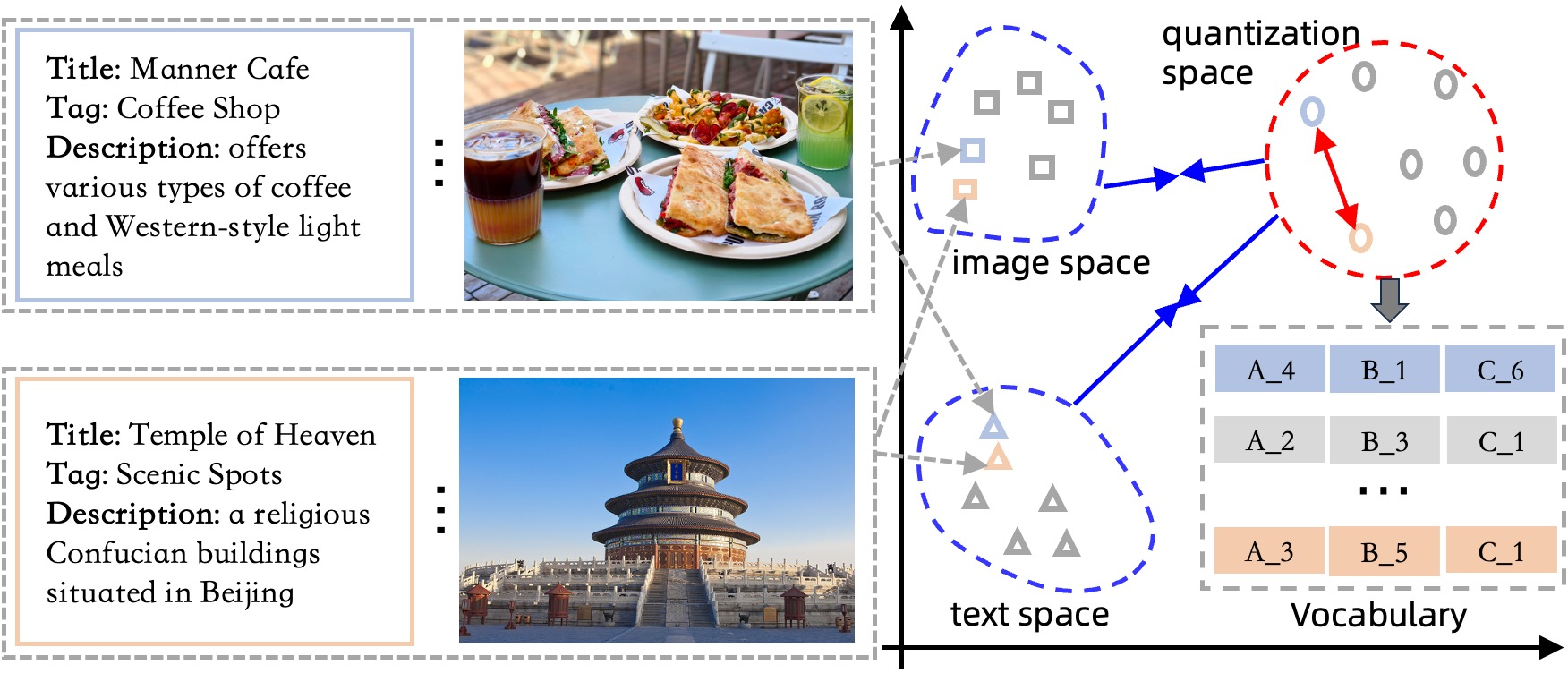
Figure 1: SimCIT translates items from diverse domains and modalities into unified semantic IDs, enabling cross-domain retrieval knowledge transfer.
SimCIT builds upon several research directions:
- Generative Recommendation: Prior works (e.g., TIGER, LIGER, OneRec) reformulate item retrieval as sequence generation, using semantic tokenization to reduce vocabulary size and enable direct item ID generation.
- Semantic Indexing and Tokenization: Vector quantization and hierarchical clustering have been used to discretize item embeddings, but reconstruction-based methods often suffer from representation collapse and poor differentiation in long-tail item distributions.
- Multi-modal Recommendation: Recent models incorporate text, image, and graph-based features to enrich item representations, but fusion strategies are often primitive and fail to capture hierarchical semantic dependencies.
- Contrastive Representation Learning: Contrastive objectives have proven effective for cross-modal alignment, but require careful handling of negative samples and modality balancing to avoid feature collapse.
SimCIT Framework
Multi-modal Semantic Fusion
SimCIT encodes each modality (text, image, collaborative, spatial) using dedicated encoders (e.g., BERT, ViT, GraphSAGE). A learnable attention mechanism computes modality importance scores, producing a fused representation:
z=m=1∑∣M∣pm⋅zm
Contrastive Item Tokenization
Instead of reconstruction loss, SimCIT employs a soft residual quantization module with Gumbel-softmax relaxation for differentiable codeword assignment. The process iteratively quantizes the fused representation, generating a tuple of semantic tokens per item. The contrastive loss (NT-Xent) aligns the reconstructed embedding with all modality-specific representations, promoting both cross-modal alignment and inter-item discrimination:
L=−m=1∑∣M∣log∑h−∈Bexp(h^⋅h−/τ)exp(h^⋅hm+/τ)
This loss implicitly regularizes identifier diversity, mitigating code assignment bias and representation collapse.
Autoregressive Generation
SimCIT integrates with encoder-decoder transformer architectures for generative recommendation. Item sequences are tokenized, and the model predicts the next item’s token tuple autoregressively. Beam search and token-to-item mapping enable efficient top-k candidate generation.
Experimental Results
SimCIT is evaluated on four public datasets (Amazon INS, BEA, Foursquare NYC, TKY) and a large-scale industrial dataset (AMap). It consistently outperforms both traditional sequential recommenders (GRU4Rec, SASRec, BERT4Rec) and generative baselines (TIGER, LETTER) across Recall@K metrics. On AMap, SimCIT achieves a 15% improvement over the second-best generative model at Recall@1000, demonstrating scalability and industrial applicability.
Ablation Studies
Ablation experiments reveal that:
- Removing the projection head or Gumbel-softmax relaxation significantly degrades performance.
- Omitting multi-modal fusion reduces identifier quality and recommendation accuracy.
- Annealing the Gumbel-softmax temperature is critical for codebook exploration and diversity.
Multi-modal Synergy
Progressive integration of modalities (text, image, spatial, collaborative) yields monotonic performance gains. Spatial features provide the largest individual boost, and full quad-modal fusion achieves the best results.
Training Dynamics
SimCIT’s training exhibits three phases: initial modality-level discrimination, cluster dispersion with increased identifier diversity, and final convergence to hierarchical clustering. This process is visualized via code embedding distributions and loss/perplexity trajectories.
Code Assignment Distribution
Hierarchical codebook visualizations confirm that SimCIT learns multi-granular item taxonomy, with each codebook layer stratifying items into distinct clusters. This structure reduces computational complexity and enhances generative retrieval.
Sensitivity Analysis
Performance improves with larger batch sizes, longer training epochs, and lower temperature τ in the contrastive loss. Increasing codebook size and number of codebooks enhances representation granularity, but excessive embedding dimension can lead to overfitting.
Practical and Theoretical Implications
SimCIT’s contrastive tokenization framework addresses key limitations of reconstruction-based methods, offering:
- Scalability: Efficient token space reduction and fast decoding for large-scale recommendation.
- Transferability: Unified semantic IDs enable cross-domain and cross-modal retrieval knowledge transfer.
- Discriminative Power: Contrastive loss enforces inter-item differentiation, critical for generative retrieval.
- Modality Fusion: Learnable attention and contrastive alignment synthesize heterogeneous item information, improving cold-start and long-tail item handling.
Theoretically, SimCIT’s approach aligns with minimal sufficient identifier learning, optimizing mutual information between item views and identifiers for generative tasks.
Future Directions
Potential extensions include:
- Incorporating natural language token spaces for further semantic alignment.
- Exploring top-k neighborhood alignment in contrastive objectives.
- Adapting SimCIT for zero-shot and few-shot recommendation scenarios.
- Investigating dynamic codebook adaptation for evolving item corpora.
Conclusion
SimCIT introduces a contrastive learning paradigm for item tokenization in generative recommendation, leveraging multi-modal fusion and hierarchical quantization to produce compact, discriminative semantic identifiers. Extensive experiments validate its superiority over existing methods, particularly in large-scale and multi-modal settings. The framework’s scalability, transferability, and discriminative capacity position it as a robust foundation for future generative recommender systems.