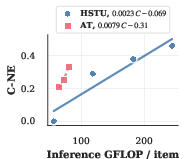
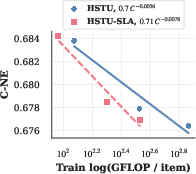
- The paper introduces ULTRA-HSTU, an end-to-end system co-design that bends scaling laws by jointly optimizing input sequences, attention mechanisms, and compute efficiency.
- It utilizes semi-local attention and mixed-precision computation to reduce complexity, achieving up to 21.4× inference speedup and significant throughput gains.
- Empirical results validate the approach with improved scaling exponents and practical production gains in recommendation quality over billions of events.
Bending the Scaling Law Curve in Large-Scale Recommendation Systems
Motivation and Problem Statement
Transformer-based sequential models have redefined industrial-scale recommendation systems by enabling deeper architectures capable of capturing comprehensive long-term and short-term user preferences. Prior advances, notably the Hierarchical Sequential Transduction Units (HSTU), established that scaling sequence length and depth in transformer architectures improves model quality. However, these benefits are constrained by quadratic complexity O(L2) in self-attention, making ultra-long user histories computationally infeasible for production deployment. Existing workaround strategies, such as cross-attention or model shallowness, reduce computational complexity at the expense of representational power and model quality. The research presented in "Bending the Scaling Law Curve in Large-Scale Recommendation Systems" (2602.16986) addresses these limitations by proposing ULTRA-HSTU: an end-to-end model-system co-design approach that fundamentally redefines the scaling law curve for large-scale recommendation systems.
Model and System Innovations in ULTRA-HSTU
ULTRA-HSTU delivers efficiency and quality improvements through joint optimizations across input sequence design, attention mechanisms, mixed-precision computation, memory management, and dynamic model topology.
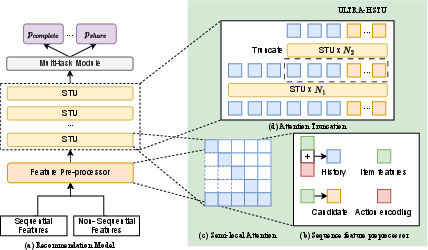
Figure 1: ULTRA-HSTU architecture integrates input sequence optimizations, semi-local attention, and dynamic topologies to maximize scaling efficiency.
ULTRA-HSTU improves input efficiency by merging item and heterogeneous action representations, reducing sequence length by 2× and attention FLOPs by 4×. Candidate masking is introduced to prevent action information leakage. Additionally, the Load-Balanced Stochastic Length (LBSL) sampling algorithm enforces per-rank compute-load constraints during distributed training, balancing compute and delivering a 15% throughput uplift.
Semi-Local Attention: Linear Sparse Self-Attention
To overcome quadratic complexity, the Semi-Local Attention (SLA) mechanism structures the attention mask into linear complexity, combining a local window (K1) for context and a global window (K2) for recency/long-term patterns. This partitioning reduces complexity to O((K1+K2)⋅L), maintaining quality while enabling inference on histories far exceeding $10k$ events.
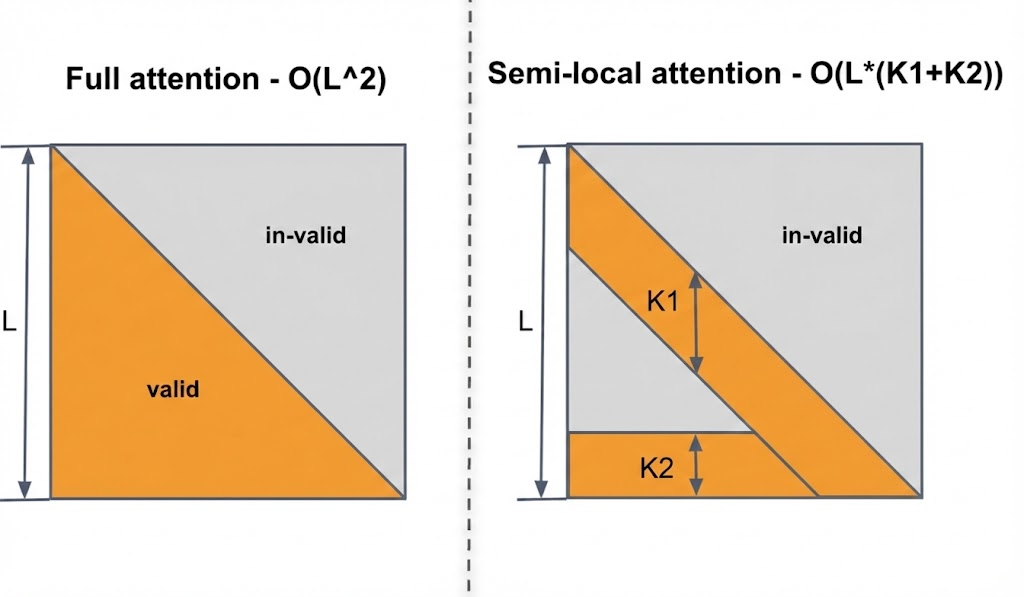
Figure 2: Comparison between full causal self-attention masks (left) and semi-local attention masks (right), highlighting SLA's focus on both recent and historical user interactions.
Mixed-Precision and Kernel-Level Optimizations
ULTRA-HSTU applies a recsys-tailored mixed-precision computation framework: major operations utilize BF16 for stability, dominant matrix computations leverage FP8 for throughput, and embeddings are quantized to INT4 for serving efficiency. Fused kernels combine scaling/quantization with layer normalization or residual additions, eliminating redundant memory passes and maximizing hardware utilization across heterogeneous GPU platforms (NVIDIA H100, AMD MI300).
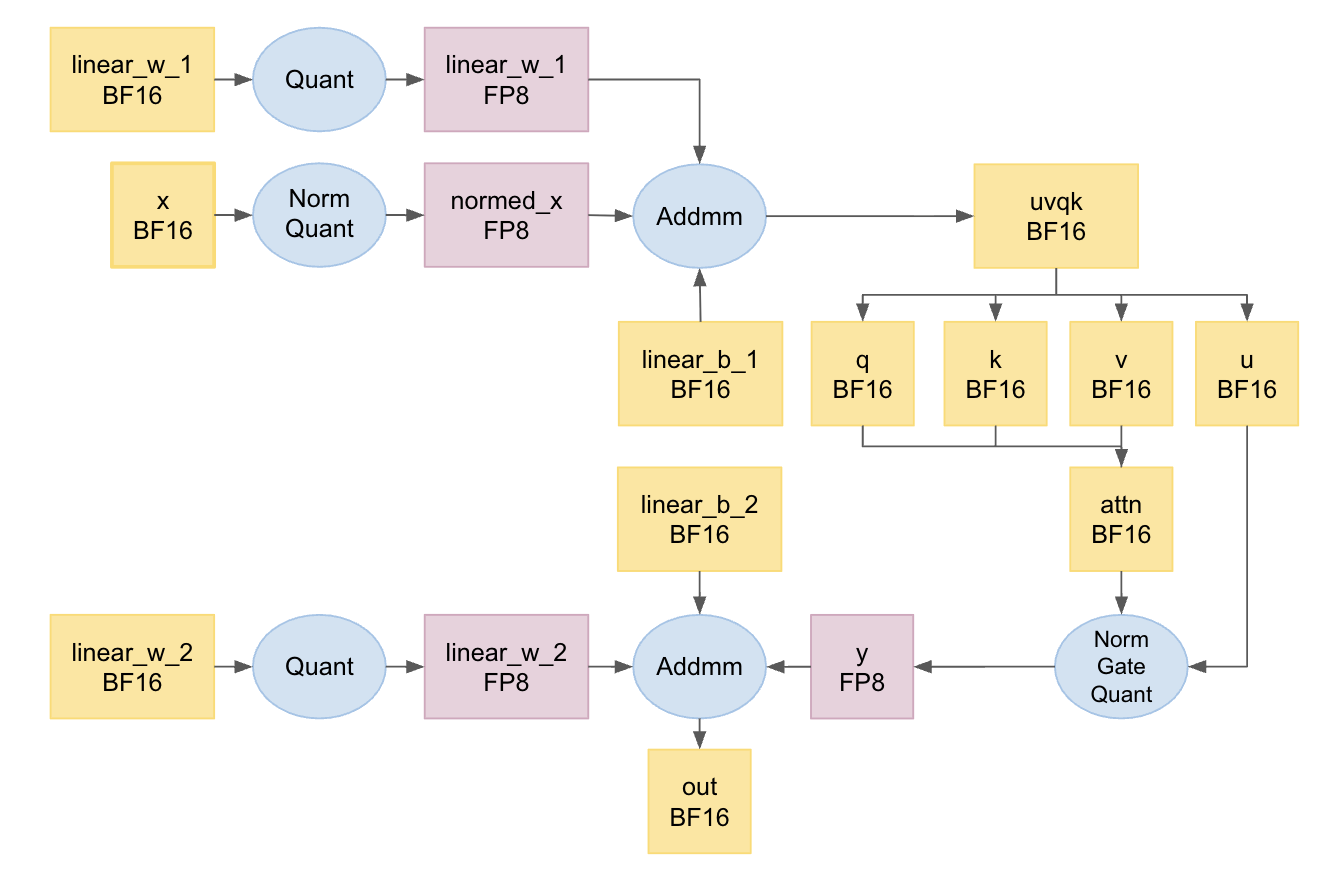
Figure 3: Mixed-precision computation stack, illustrating integration of scaling/quantization with preceding operations for optimal efficiency.
Memory Management and Activation Rematerialization
Selective activation rematerialization reconstructs large forward-pass tensors only during backpropagation, reducing memory footprint by 67% per layer with negligible overhead. Fully jagged tensor implementations eliminate padding, further optimizing memory and compute utilization.
Dynamic Topological Model Designs
Scaling model depth amplifies representational capacity but incurs resource costs. ULTRA-HSTU introduces dynamic topological strategies:
- Attention Truncation: After a set of layers operating over the full sequence, additional layers function only over truncated (high-value recent) segments, slashing computation while preserving predictive performance.
- Mixture of Transducers (MoT): Heterogeneous user signals are processed in dedicated transducers for targeted computation, preventing signal dilution and competitive suppression seen in monolithic architectures.
Empirical Results and Scaling Law Analysis
ULTRA-HSTU is rigorously benchmarked against production datasets (over $6$ billion samples, sequences up to $16,384$ events) and open-source benchmarks with shorter sequences. Across all regimes, the model demonstrates superior normalized entropy (NE), with substantial reductions versus STCA, Transformer, DIN, and SASRec baselines, and consistently outperforms vanilla HSTU.
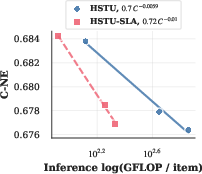
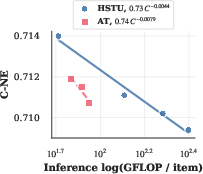
Figure 5: Scaling law exponents for SLA and attention truncation: SLA improves training exponent by 1.39× and inference exponent by 1.69×, while attention truncation achieves 1.8× improvement in inference compute scaling.
Theoretical and Practical Implications
The research demonstrates that carefully engineered self-attention—rather than cross-attention or model shallowness—is optimal for scaling sequential recommender systems. ULTRA-HSTU’s system-level optimizations enable unprecedented model deployment (18-layer self-attention on $16k$ sequences, hundreds of H100 GPUs), validating the hypothesis that compute-optimal sequential architectures can be realized in production workflows with billions of daily users.
Practically, these results advance the feasibility of deploying ever-larger sequential models, providing market-scale recommendation domains with tools previously available only to LLMs. Theoretically, the findings reinforce that scaling law exponents, improved even moderately, compound advantages polynomially as compute budgets increase, enabling models with orders-of-magnitude lower resource requirements to achieve equivalent performance.
Future directions include further refinement of dynamic topology (MoT, topological fusion), exploration of adaptive window mechanisms in SLA, and system co-designs for next-generation hardware architectures tailored specifically to ultra-long sequence processing.
Conclusion
ULTRA-HSTU represents a comprehensive advance in end-to-end co-design for sequential recommendation modeling, demonstrating that model quality and scaling efficiency can be jointly maximized. The explicit confirmation that self-attention architectures, augmented via linear complexity mechanisms and system optimizations, drive superior scaling laws in industrial recommender systems establishes a new paradigm for practical and theoretical progress. The deployment results and scaling analyses in "Bending the Scaling Law Curve in Large-Scale Recommendation Systems" (2602.16986) provide authoritative guidance for both the future of large-scale recommendation and AI foundation model engineering.