- The paper introduces TokenMixer-Large, which scales ranking models by innovating with a mixing-and-reverting paradigm and enhanced per-token MoE.
- It implements sparse training/inference and tailored operators to achieve near-dense performance at reduced computational costs.
- Empirical results across e-commerce, advertising, and live streaming scenarios show significant gains in key business metrics.
TokenMixer-Large: Systematic Scaling of Ranking Models for Massive-Scale Industrial Recommenders
Introduction
The paper "TokenMixer-Large: Scaling Up Large Ranking Models in Industrial Recommenders" (2602.06563) addresses critical scalability and efficiency bottlenecks in deep learning recommendation models (DLRMs). Building on the prior TokenMixer architecture, the authors expose several limitations—sub-optimal residual paths, loss of semantic alignment, vanishing gradients in deep networks, incomplete MoE sparsification, and restricted scalability to billion-scale parameters. TokenMixer-Large introduces architectural and engineering innovations, achieving robust performance across diverse real-world scenarios (advertising, e-commerce, live streaming), with successful deployment at ByteDance.
Architecture and Methodological Advances
TokenMixer-Large is structured around three principal components: semantic tokenization, a revised TokenMixer-Large block, and an efficient, sparsified Per-token MoE.
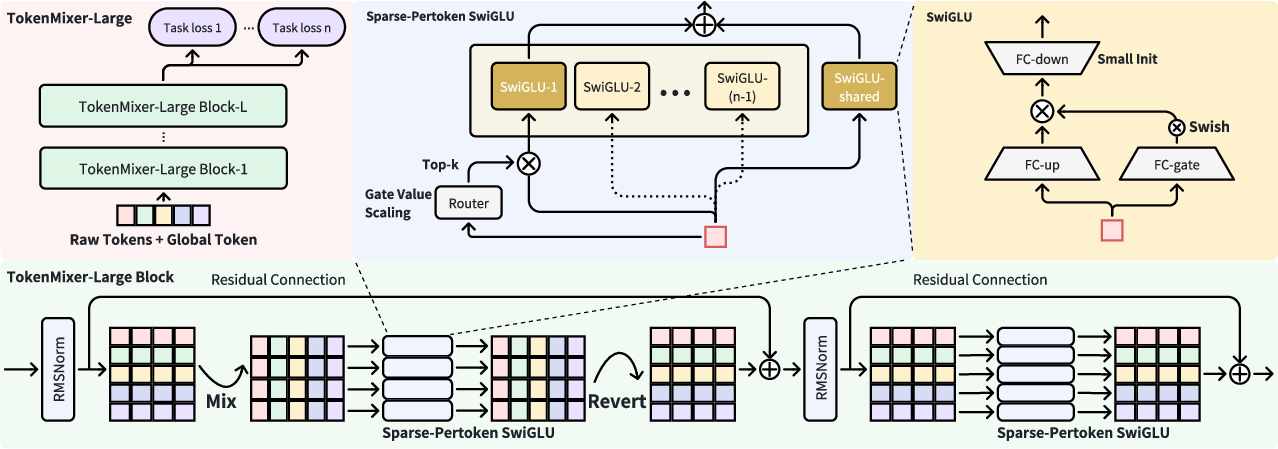
Figure 1: The architecture of TokenMixer-Large, showing token processing, mixing/reverting, S-P MoE, and residual connections.
Semantic Group-wise Tokenization
Dense embeddings are produced from high-dimensional, sparse user/item/sequence features, grouped semantically to preserve heterogeneity. Each group’s concatenated embeddings are compressed to aligned tokens, utilizing distinct MLP mappings. A global token aggregates collective information, analogous to [CLS] in BERT, improving context propagation.
Mixing-and-Reverting Paradigm
A core innovation is rectifying residual pathway deficiencies from RankMixer. TokenMixer-Large uses a symmetric two-step process: information mixing followed by dimensional reverting. This ensures input-output alignment and enables seamless semantic propagation across network depth, crucial for robust residual connections and stable gradient flows.
Pertoken SwiGLU
Pertoken FFN from RankMixer is upgraded to Pertoken SwiGLU, enhancing expressivity and representing token-wise heterogeneity. SwiGLU’s gating and up/down projections augment nonlinearity and allow fine-grained control over feature interactions.
Residual and Auxiliary Loss Mechanisms
TokenMixer-Large employs both standard and interval (inter-residual) connections. The latter, applied regularly but not to the final layer, prevent gradient vanishing in deep stacks. An auxiliary loss combines logits from lower and upper layers, ensuring robust multi-layer parameter convergence and improving stability.
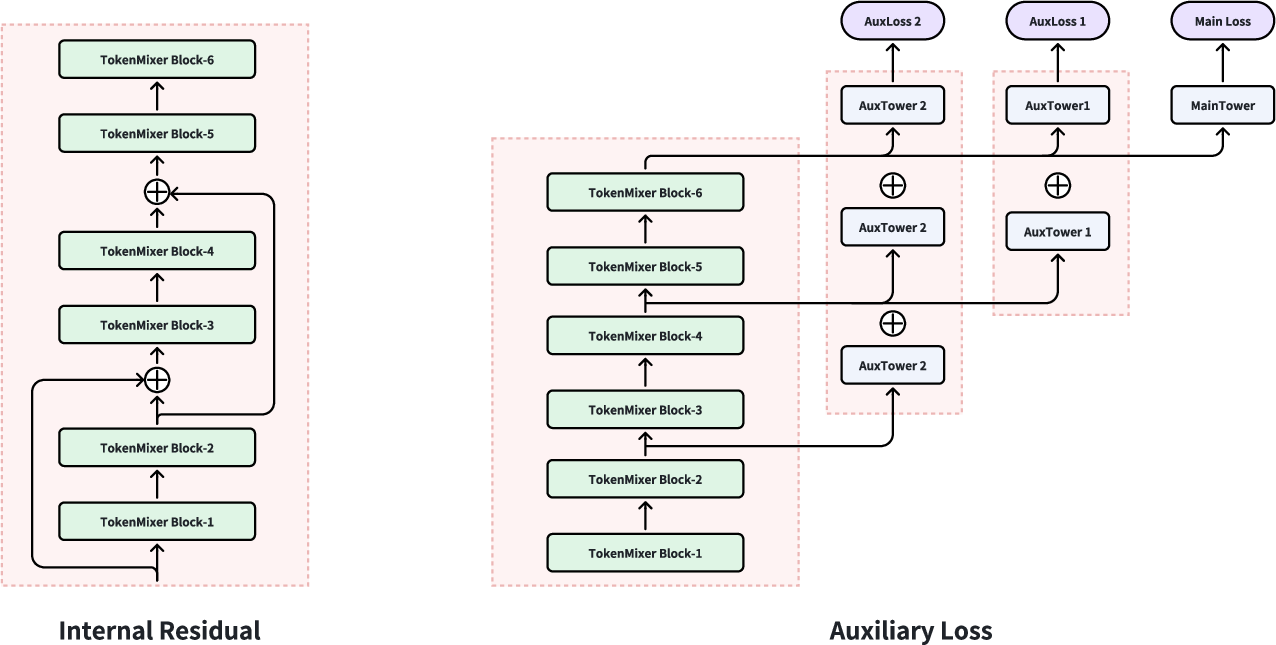
Figure 2: Diagram of internal residual and auxiliary loss, highlighting information flow and gradient stabilization.
Sparse-Pertoken MoE and Engineering Optimization
First Enlarge, Then Sparse
The model first scales up all Pertoken SwiGLU layers, then applies sparse activation ("Sparse Train, Sparse Infer"), enabling up to 1:2 sparsity with minimal performance loss. This achieves near-dense performance with only half the training/inference cost. The authors detail that sparsity levels greater than 1:8 are not yet feasible with current performance requirements.
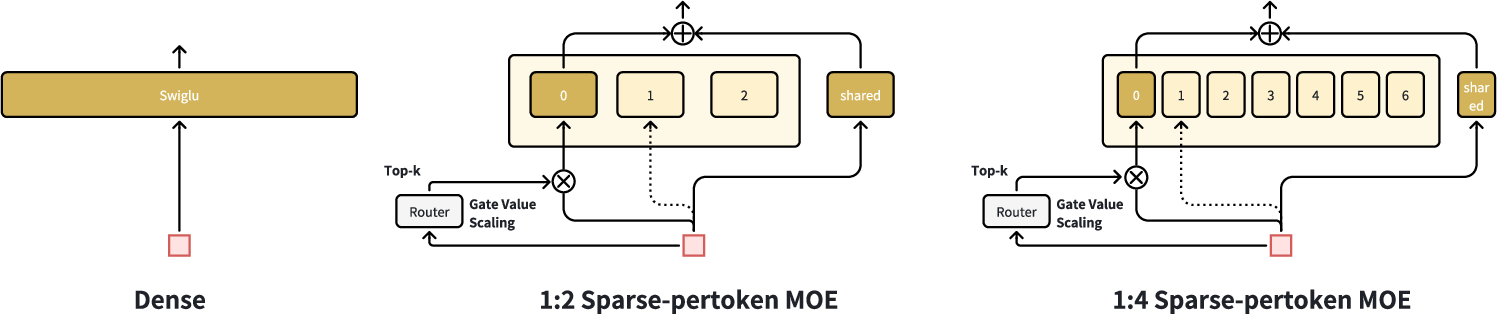
Figure 3: Illustration of the 'First Enlarge, Then Sparse' iteration, showing how dense layers are refined and sparsified.
Load-Balanced Sparse MoE
With token-wise routing and shared experts, the load is balanced across tokens, negating the necessity for auxiliary load-balancing loss. Routing probabilities are scaled (Gate Value Scaling) in proportion to sparsity, ensuring consistent gradient updates.


Figure 4: Token-wise load balancing in sparse-Pertoken MoE at sparsity 1:2 and 1:8.
Small Initialization for SwiGLU
Reducing FC-down initialization variance (from stddev 1 to 0.01) allows near-identity mapping at initialization, stabilizes training, and controls output explosion risk.
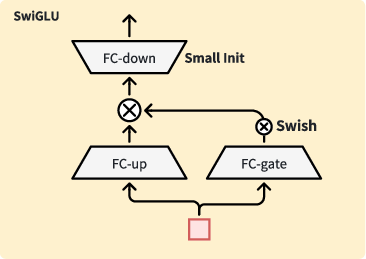
Figure 5: Effect of small initialization in SwiGLU impacting early-stage convergence.
Operator and Serving Innovations
Specialized high-performance operators (MoEPermute, MoEGroupedFFN, MoEUnpermute) are designed to optimize memory/computation ratios. FP8 quantization is applied for inference, achieving a 1.7x speedup with equivalent accuracy. The Token Parallel training strategy reduces communication overhead and boosts throughput by up to 96.6% in production.
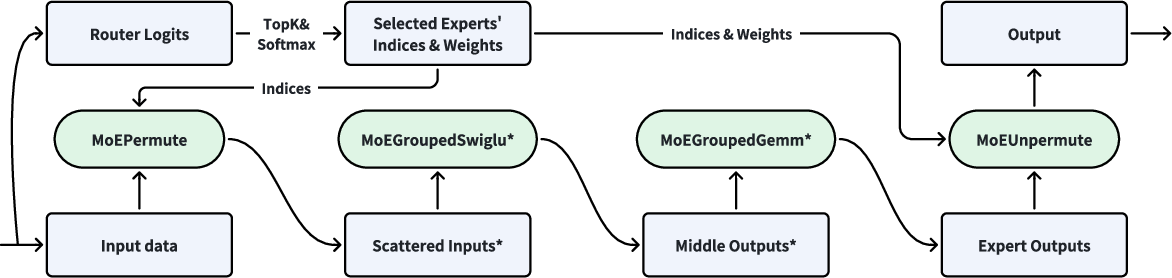
Figure 6: Workflow of high-performance operators in a TokenMixer-Large block with FP8 quantization.
Empirical Evaluation and Scaling Laws
TokenMixer-Large achieves statistically significant gains across industrial scenarios:
- E-commerce: +1.66% order, +2.98% GMV
- Advertising: +2% ADSS
- Live streaming: +1.4% payment
Experiments show superior Model FLOPs Utilization (MFU), scaling the architecture to 7B and 15B parameters offline, and 4B/7B in online traffic.
Scaling Law Verification
AUC and task performance consistently increase with parameter/FLOP growth. Balanced expansion across width, depth, and hidden expansion yields greater returns. Larger models require more extensive datasets for full convergence.
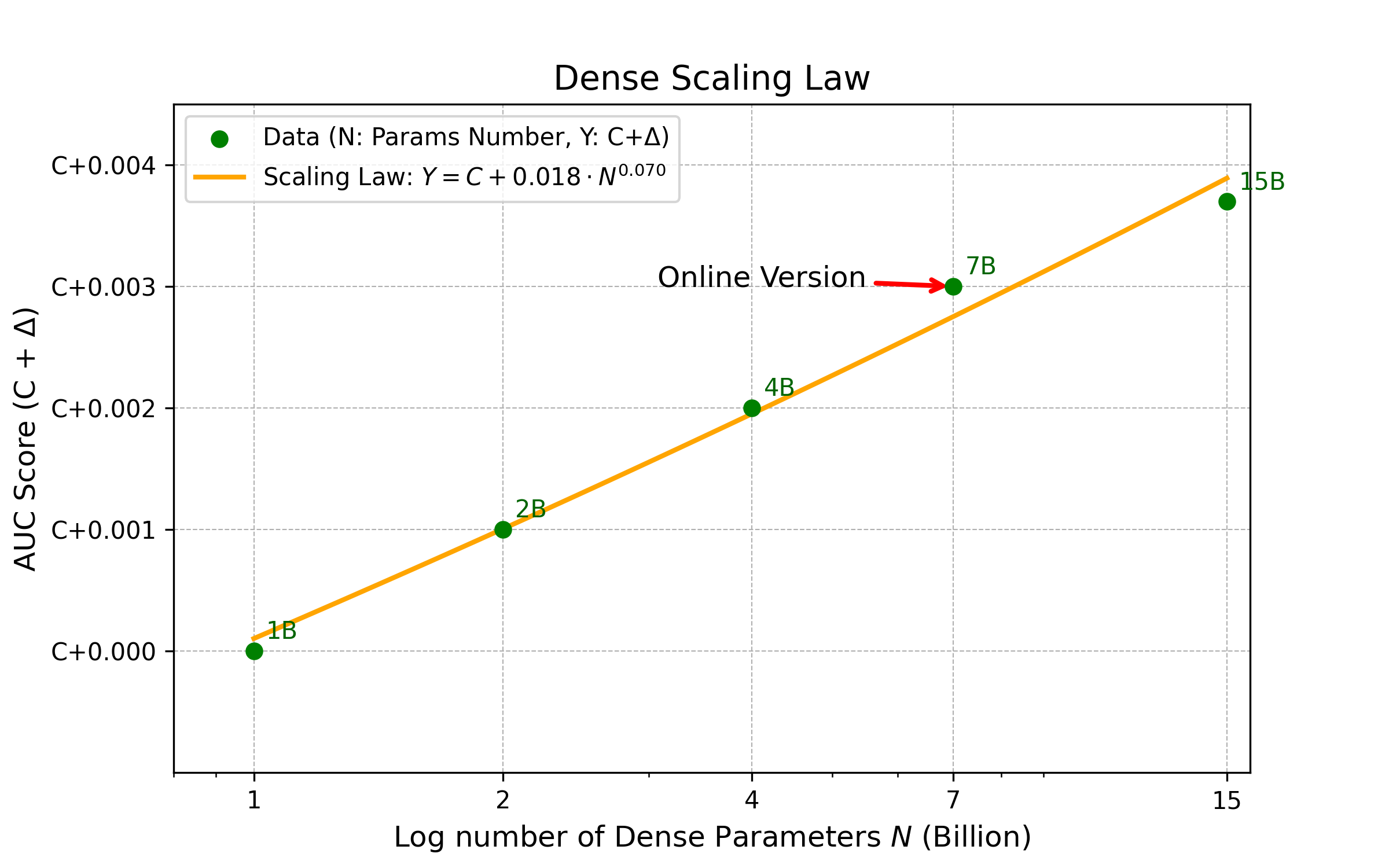
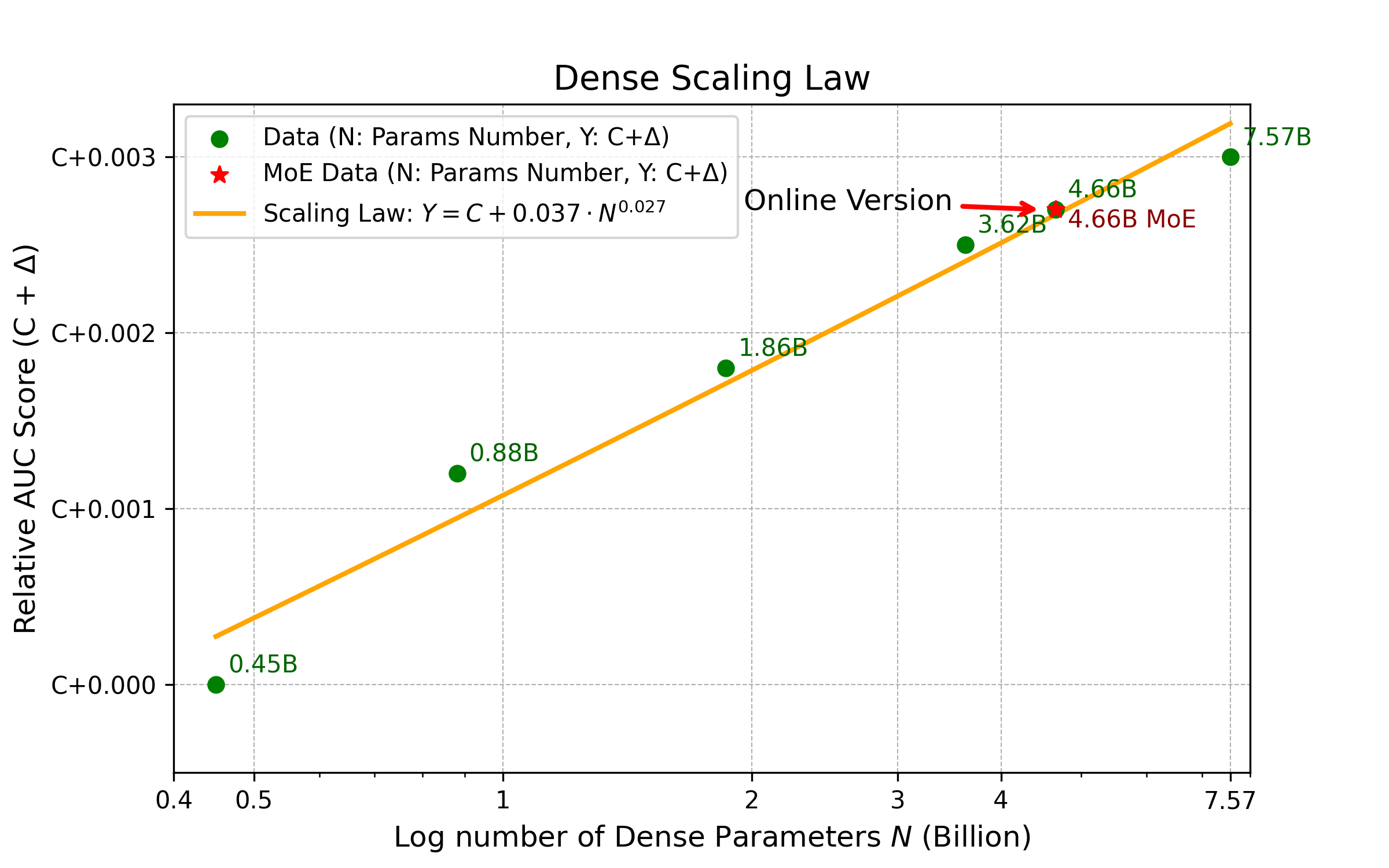
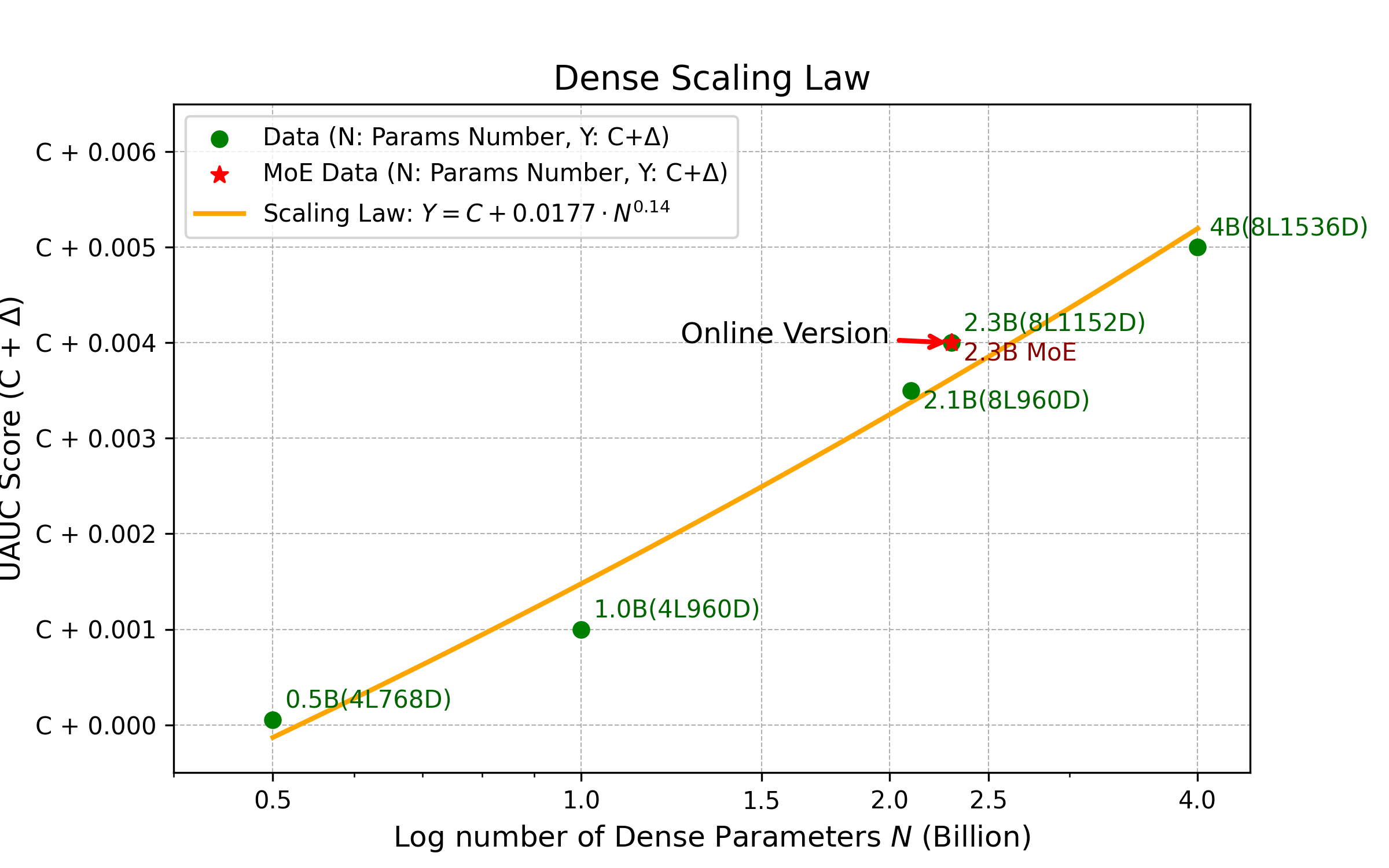
Figure 7: Scaling laws across Feed Ads, E-Commerce, and Live Streaming, confirming robust scaling behavior.
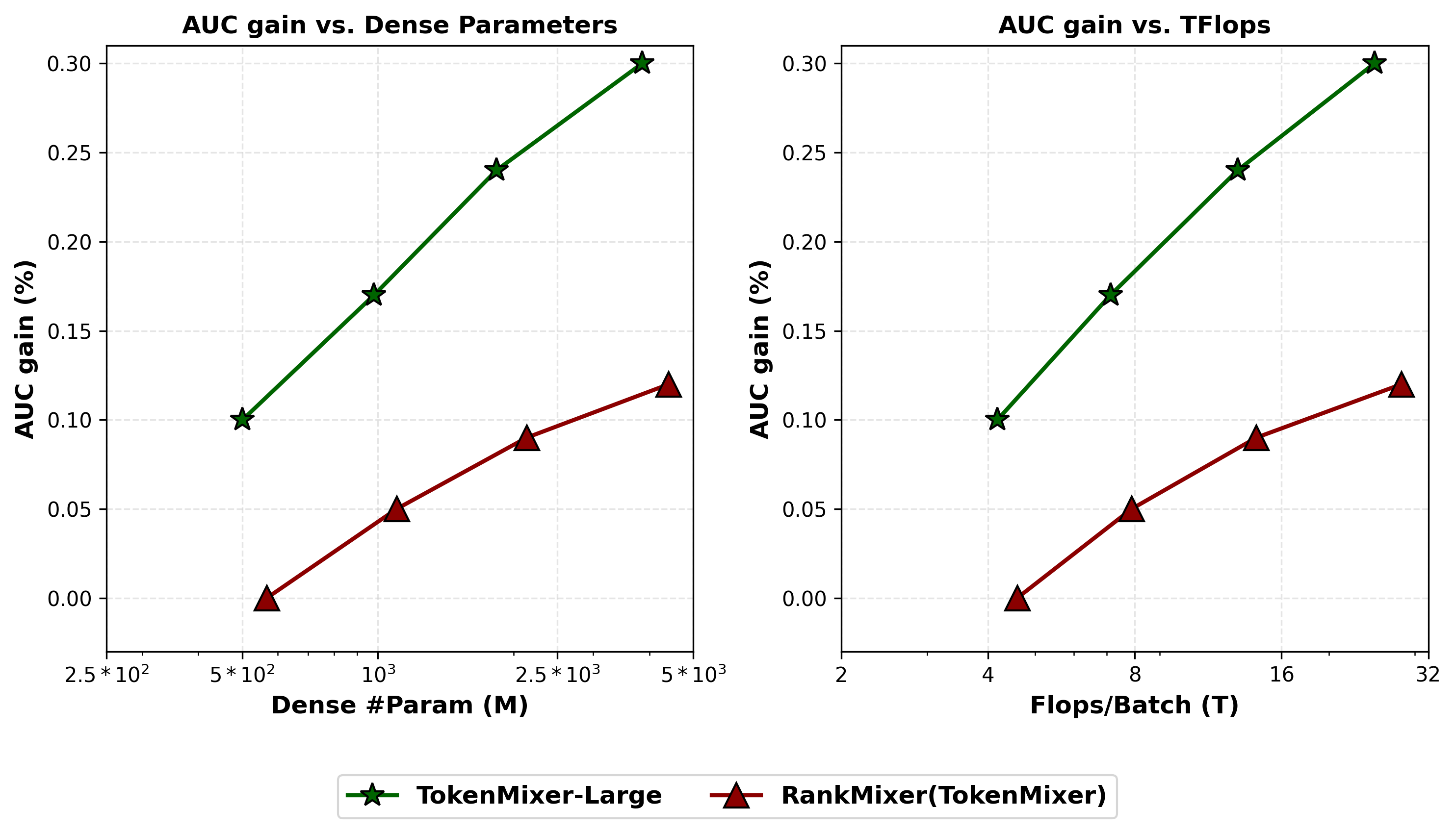
Figure 8: Scaling laws—AUC-gain vs Params/FLOPs for SOTA models, with logarithmic scaling on the x-axis.
Ablation: Architectural and MoE Components
Ablation studies confirm the criticality of mixing/reverting and Pertoken SwiGLU—removing these manifests the greatest performance drops. Removing fragmented, memory-bound operators (e.g., DCN/LHUC) at higher parameter scales has negligible impact, validating the "pure model" design philosophy. Pre-norm with RMSNorm is preferred for stable deep stack training.
Implications and Theoretical Considerations
TokenMixer-Large establishes a reproducible scaling law and co-design framework for stacking, sparsifying, and optimizing DLRMs in industrial settings. The mixing-reverting paradigm, interval residuals, and "sparse train/infer" with pertoken MoE offer architectural blueprints for robust, hardware-aligned recommender systems. Practical implications include substantial training and inference cost reduction at extreme scales and improved real-world business metrics.
Future Directions
The paper identifies open problems in pushing sparsity beyond 1:8, further optimizing token load balancing, integrating more complex sequence modeling, and exploring alternative normalization and mixing strategies as parameter and dataset scales continue to expand. The Token Parallel design can be generalized to other highly token-centric architectures seeking efficient distributed training paradigms.
Conclusion
TokenMixer-Large redefines scalable ranking models for industrial recommender systems. By systematically revising residual design, enabling sparse activation, and co-optimizing hardware execution, it delivers substantial improvements in efficiency and effectiveness at extreme parameter scales. The architecture establishes clear scaling law behavior and provides pathways for future DLRM and MoE advancements, both in theoretical modeling and system engineering.