LLM-I2I: Boost Your Small Item2Item Recommendation Model with Large Language Model
Abstract: Item-to-Item (I2I) recommendation models are widely used in real-world systems due to their scalability, real-time capabilities, and high recommendation quality. Research to enhance I2I performance focuses on two directions: 1) model-centric approaches, which adopt deeper architectures but risk increased computational costs and deployment complexity, and 2) data-centric methods, which refine training data without altering models, offering cost-effectiveness but struggling with data sparsity and noise. To address these challenges, we propose LLM-I2I, a data-centric framework leveraging LLMs to mitigate data quality issues. LLM-I2I includes (1) an LLM-based generator that synthesizes user-item interactions for long-tail items, alleviating data sparsity, and (2) an LLM-based discriminator that filters noisy interactions from real and synthetic data. The refined data is then fused to train I2I models. Evaluated on industry (AEDS) and academic (ARD) datasets, LLM-I2I consistently improves recommendation accuracy, particularly for long-tail items. Deployed on a large-scale cross-border e-commerce platform, it boosts recall number (RN) by 6.02% and gross merchandise value (GMV) by 1.22% over existing I2I models. This work highlights the potential of LLMs in enhancing data-centric recommendation systems without modifying model architectures.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making simple, fast recommendation systems (the kind that suggest “items similar to what you just clicked”) work better without making them bigger or slower. The authors show how to use a LLM—like a smart text AI—to create and clean better training data so these small “item-to-item” recommenders become more accurate, especially for rare or new items.
The big questions the authors asked
- Can we boost the accuracy of small, fast item-to-item recommenders by improving their training data instead of changing the models themselves?
- Can an LLM help “fill the gaps” for rare items that don’t have much data (the long-tail problem)?
- Can an LLM also help remove bad or noisy clicks (like accidental clicks) so the recommender learns from cleaner data?
- Will this work at real-world scale, and will it help business results without slowing the system down?
How the method works (in everyday terms)
Think of an online store like a giant library. Item-to-item (I2I) recommenders are like a quick librarian who says, “If you liked this, you might also like that,” based on what items tend to appear together. These systems are tiny and fast, but they struggle when:
- Rare items don’t have enough history (long-tail items).
- The data has noise (accidental clicks or messy behavior).
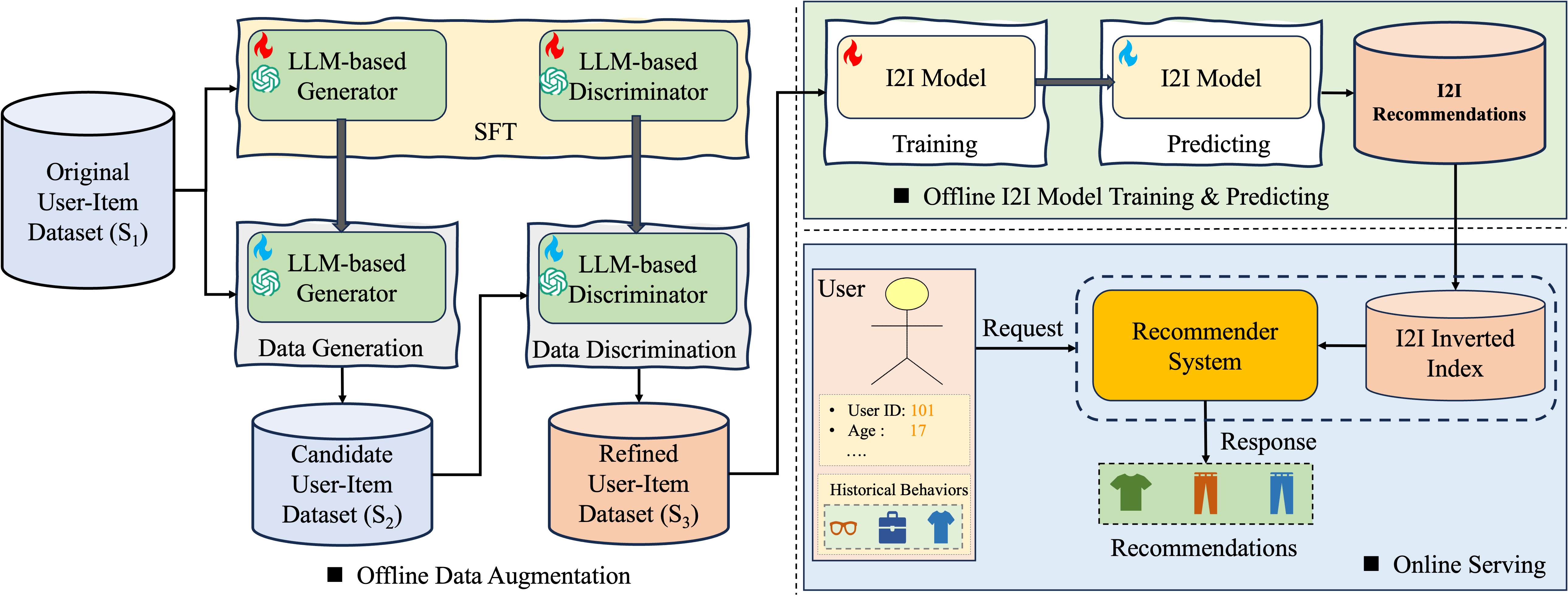
The authors build two LLM helpers:
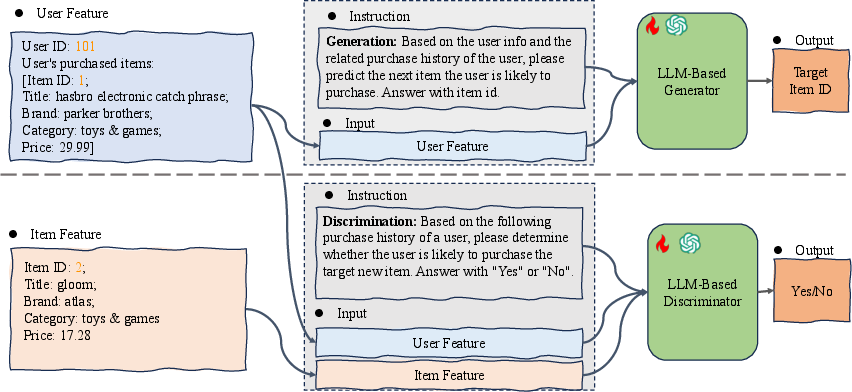
- The “Imagination” helper (Generator): This LLM looks at a user’s recent actions and imagines realistic extra interactions—like guessing what else they might have clicked or bought. It pays extra attention to rare items so they don’t get ignored. In training, they give the model stronger encouragement to learn about rare items (they “weight” rare items more heavily), so it becomes better at suggesting them.
- The “Fact-Checker” helper (Discriminator): Not all imagined data is good. So a second LLM double-checks each imagined user–item pair and scores how confident it is that the user would really interact with that item. Only high-confidence “Yes” pairs are kept.
After that:
- The system mixes the original real data with the high-quality, LLM-approved synthetic data.
- It trains the normal small item-to-item models (no changes needed).
- For online use, nothing changes: it still uses a fast lookup of “item → similar items” to respond in real time.
In short: the LLM “imagines” useful extra examples and then “filters” them, giving the small recommender better, cleaner training material—without making the live system heavier or slower.
What did they find?
Across both public benchmarks and a huge real dataset, the approach made recommendations better—especially for rare items.
Here’s what stood out:
- On three Amazon product categories (Beauty, Sports & Outdoors, Toys & Games), adding the LLM-generated-and-filtered data improved common accuracy measures (Recall@K and NDCG@K) for several classic item-to-item methods (BM25, BPR, YoutubeDNN, Swing). Swing, a strong baseline, still got notable gains.
- On a massive real-world dataset from AliExpress (billions of interactions), the method consistently improved Recall@K and NDCG@K across all tested models.
- For long-tail items (rare products), the gains were especially large. For example, on the industrial dataset, Recall@10 for long-tail items improved by about 61%, and NDCG@10 improved by about 86%.
- In a live A/B test on AliExpress:
- The system retrieved more relevant items (+6.02% RN).
- Overall sales value improved (+1.22% GMV).
- There was no slowdown in response time (latency stayed essentially the same) because all the LLM work happens offline.
Why this matters: Better recommendations without changing the live service or using more online computing power is a big win in practice.
Why this matters and what could happen next
- Practical impact: Many companies rely on small, fast recommenders because they’re cheap and quick. This method lets them get better results by improving the training data, not the model. That means no risky code changes, no extra online cost, and no slower responses.
- Helping the long tail: Rare items get more attention and become recommendable, which can improve user discovery and fairness for smaller sellers or niche content.
- Cleaner data, better learning: The “Fact-Checker” step shows that filtering synthetic data is crucial—more data isn’t helpful unless it’s high quality.
- Scalable strategy: Because the heavy lifting happens offline, this approach is suitable for very large platforms.
Looking ahead, this idea—using LLMs as smart data builders and cleaners—could be applied to other kinds of recommendation systems or even other AI tasks where data is sparse or noisy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete, actionable gaps left unresolved by the paper that future researchers could address.
- Item ID representation at scale: The paper does not explain how an LLM can generate and reference tens of millions of unique item IDs (e.g., in AEDS). Specify the ID tokenization/serialization scheme, how collisions or out-of-vocabulary IDs are handled, and evaluate scalability and accuracy of ID decoding.
- Missing prompt design details: The generator and discriminator depend on “well-designed” prompts, but no templates, schema, or serialization of user/item features are provided. Release prompt formats, provide ablations over prompt variants, and quantify their impact.
- Ambiguity in item feature inputs: It is unclear what constitutes the item features X_y (text, attributes, images, IDs only). Specify feature modalities and serialization; compare ID-only vs. content-rich inputs to the LLM and measure downstream effects.
- Discriminator confidence calibration: Confidence thresholds (e.g., requiring 1.0) are used without calibration or reliability assessment. Evaluate calibration (ECE/Brier), threshold sensitivity, and trade-offs between precision/recall for filtering synthetic data.
- Negative sampling quality: The discriminator is trained with random global negatives, which may produce easy negatives and false negatives. Compare random vs. exposure-aware or hard negative sampling and quantify the impact on denoising quality.
- Synthetic/real data mixing ratio: Although performance varies with the amount of synthetic data, the paper lacks a principled strategy to set user- or item-level mixture ratios. Develop and evaluate adaptive mixing policies (e.g., per-user/item, per-popularity bin) to prevent distribution drift.
- Long-tail loss hyperparameters and definition: The choice α=4, β=1 and defining long-tail items as the bottom 20% (vs. “clicked once” in AEDS) are arbitrary and inconsistent across datasets. Provide sensitivity analyses, a unified definition, and adaptive weighting schemes learned from data.
- Generator sampling strategy: The paper does not describe decoding strategies (greedy vs. top-k/top-p) for the generator, which affects diversity and noise. Evaluate sampling methods, temperature, and their impact on recall, NDCG, diversity, and denoising cost.
- Sequence length truncation: Inputs are limited to the last 10 interactions for prediction, but no study explores the optimal sequence length or recency weighting. Conduct ablations over sequence window size, recency decay, and session segmentation.
- Cold-start coverage: The method targets long-tail items but does not address item cold-start (zero interactions) or user cold-start. Extend the approach to cold-start by leveraging item content (text/images) and user profile priors; evaluate dedicated cold-start splits.
- Cross-domain and multilingual generalization: Results are limited to e-commerce (Amazon, AliExpress). Test in news/video domains and across languages (AliExpress is cross-border) to assess transferability and cultural/linguistic robustness.
- Comparison to non-LLM data-centric baselines: The paper compares mainly to LLM-CF. Add strong data-centric baselines (self-supervised denoising, contrastive augmentation, MixRec, Double Correction, exposure-aware debiasing) to isolate LLM-I2I’s incremental benefits.
- Offline cost and efficiency: Full-parameter SFT on large corpora and subsequent generation/discrimination at scale are claimed “cost-effective” but not quantified. Report training/inference FLOPs, wall-clock time, throughput, hardware, and incremental update costs; compare to LoRA/PEFT alternatives.
- Statistical rigor of online A/B tests: Online gains are reported over one week with 4% cohorts but lack p-values, confidence intervals, or variance analyses. Provide statistical significance, power analysis, and segment-wise breakdown (e.g., new vs. returning users, device types).
- Fairness, popularity bias, and coverage: While long-tail recall improves, the paper does not assess coverage, diversity, or bias shifts (e.g., toward certain sellers or categories). Report coverage@K, Gini/Herfindahl indices, and fairness metrics; add controls to prevent popularity amplification.
- Privacy and compliance: Prompts include user IDs and profiles, but privacy risks and regulatory compliance (PII handling, data minimization) are not discussed. Define privacy-preserving input schemas and assess privacy leakage risks from synthetic data.
- Robustness to adversarial or spurious interactions: The method aims to filter accidental clicks but does not test robustness against adversarial behaviors (e.g., seller manipulation). Design stress tests and adversarial data scenarios; measure discriminator resilience.
- Temporal stability and drift: The approach is trained on a 90-day window with no analysis of temporal drift, update cadence, or performance decay. Study continual learning strategies, retraining frequency, and time-aware prompting to maintain stability.
- End-to-end ranking impact: The paper focuses on recall/NDCG at retrieval but does not analyze interactions with downstream rankers (calibration, feature distributions). Conduct end-to-end evaluations, measure ranker calibration shifts, and devise mitigation (e.g., sample weighting).
- Synthetic data error analysis: No breakdown of error types (false positives/negatives) in generator outputs or discriminator decisions is provided. Perform qualitative/quantitative error analyses to guide prompt/model refinements.
- Item index size and system constraints: The choice to store top-200 related items per product is not justified or ablated. Evaluate index size vs. latency/GMV trade-offs and how synthetic edges affect memory and retrieval time.
- Reproducibility details: Key implementation specifics (SFT dataset size, training steps, prompt templates, seeds beyond 42, pre/post-processing) are missing. Release code/prompt templates and synthetic datasets for ARD to enable replication.
- Integration with content and tools: The LLM operates without retrieval-augmented item catalogs or multimodal signals. Explore RAG with item attributes and multimodal LLMs (text+image) to improve long-tail and cold-start handling.
- Safety of synthetic interactions: Ethical implications of augmenting with synthetic user behavior are not discussed. Establish guardrails (e.g., human-in-the-loop audits, constraints preventing unrealistic co-clicks) and monitor downstream business risks.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed today using the paper’s LLM-I2I approach. Each bullet includes sector alignment and key dependencies or assumptions.
- E-commerce and marketplaces: drop-in offline augmentation for existing item-to-item retrieval (BM25, BPR, YoutubeDNN, Swing) to boost long-tail coverage, recall, and GMV without changing online serving
- Sector: retail, cross-border e-commerce, classifieds, B2C/B2B marketplaces
- Tools/workflows: fine-tune
LLama2-7B-Chatgenerator and discriminator; apply long-tail weighted loss; generate items from last 10 user interactions; filter with confidence=1.0; fuse with real logs; rebuild I2I inverted index (top-K per item); aggregate top-M keys at serving - Evidence: +6.02% RN and +1.22% GMV on AliExpress with unchanged latency
- Dependencies/assumptions: access to historical user-item logs; privacy-safe feature processing; offline compute (DeepSpeed Zero2, FlashAttention2); careful prompt and threshold tuning; monitoring distribution shift
- Content platforms (news, video, music): better cold-start and discovery for niche content via synthetic interactions and denoising noisy clicks
- Sector: media, streaming, publishing
- Tools/workflows: generator/discriminator SFT on domain logs; integrate with existing item-similarity indices; editorial filters layered after recall
- Dependencies/assumptions: domain-adapted LLM prompts; confidence calibration to avoid promoting low-quality content; recent-behavior emphasis remains suitable
- Advertising and sponsored recommendations: improved item-to-item retargeting for long-tail advertisers or SKUs
- Sector: ad tech, retail media
- Tools/workflows: synthetic affinity pairs for catalog items; discriminator as quality gate; maintain latency by keeping augmentation offline
- Dependencies/assumptions: clear separation of paid vs. organic signals; guardrails against synthetic-data gaming; compliance with auction policies
- App stores and plugin marketplaces: app-to-app recommendations for indie/long-tail apps
- Sector: software distribution
- Tools/workflows: train on install/click logs; rebuild inverted index; expose “similar apps” recommendations at scale
- Dependencies/assumptions: accurate negative sampling; avoid overexposure of low-quality apps; developer fairness policies
- Travel, jobs, and rentals: item-to-item for listings (routes, roles, properties) where many items are long-tail
- Sector: travel, HR tech, real estate
- Tools/workflows: synthesize interactions for sparsely viewed listings; filter accidental clicks; keep small retrievers (Swing/BM25)
- Dependencies/assumptions: metadata quality for discriminator; job/rental specific compliance (anti-discrimination)
- CRM and lifecycle marketing: more diverse “you might also like” for email/push campaigns without increasing runtime costs
- Sector: marketing tech
- Tools/workflows: offline augmentation to build affinity lists; deploy via campaign orchestration and ranked templates
- Dependencies/assumptions: consented use of behavioral data; campaign-level A/B testing; alignment with deliverability constraints
- Data quality pipelines: LLM-based discriminator to filter noisy interactions (e.g., accidental clicks) before training
- Sector: data engineering, MLOps
- Tools/workflows: confidence scoring and thresholding; distribution monitoring (synthetic ratio vs. real); negative sampling strategy
- Dependencies/assumptions: reliable labels for SFT; stable confidence calibration; periodic retraining to track behavior drift
- Resource-constrained platforms: keep small, fast recommenders while benefiting from LLM-driven data improvements
- Sector: SMBs, emerging markets, edge services
- Tools/workflows: outsource or batch offline LLM jobs; update indices during low-traffic windows
- Dependencies/assumptions: affordable offline compute or managed LLM APIs; versioning and rollback support
- Academic research and benchmarking: reproducible pipeline integrating generator/discriminator and long-tail loss for public datasets (ARD)
- Sector: academia, research labs
- Tools/workflows: apply on Beauty/Sports/Toys datasets; run ablations; compare against LLM-CF and standard I2I baselines
- Dependencies/assumptions: open data access; consistent evaluation (Recall@K, NDCG@K); replicable seeds/configs
- Governance and risk controls: operational policies for synthetic-data ratios, confidence thresholds, and anonymization
- Sector: policy, compliance, data governance
- Tools/workflows: define max synthetic-to-real ratio; enforce confidence floor (e.g., 1.0); remove PII before LLM training
- Dependencies/assumptions: legal review (GDPR/CCPA); audit logs for synthetic contributions; bias monitoring for long-tail exposure
- Packaged augmentation module: productize “LLM-I2I Augmentor” with connectors to Implicit (BM25/BPR), YoutubeDNN, Swing/PAI
- Sector: MLOps, platform engineering
- Tools/workflows: pluggable generator/discriminator; Long-tail Loss Tuner (
alpha,β); Confidence Calibrator; Index Builder - Dependencies/assumptions: API contracts for data ingestion and index export; robust orchestration and backfill processes
Long-Term Applications
Below are use cases that require further research, scaling, or productization before widespread deployment.
- Real-time LLM gating: low-latency on-device or micro-LLM discriminators to adaptively filter candidates at serving time
- Sector: high-frequency recommender services
- Tools/products: distilled mini-LLMs; KV-caching; hardware acceleration
- Dependencies/assumptions: tight latency budgets; distillation quality; robust edge deployment
- Multi-modal augmentation: combine text/images/attributes for richer synthetic interactions and better coverage of visual items
- Sector: e-commerce, media, fashion
- Tools/products: vision-language LLMs; unified item embeddings; cross-modal discriminator
- Dependencies/assumptions: high-quality multimodal data; additional compute for SFT; guardrails for hallucinations
- Cross-lingual and cross-border recommenders: multilingual augmentation to improve item similarity across locales
- Sector: global marketplaces, travel
- Tools/products: multilingual LLMs; translation-aware prompts; locale-sensitive discriminators
- Dependencies/assumptions: language coverage; cultural relevance; compliance across jurisdictions
- Privacy-preserving training: federated or differentially private LLM-I2I pipelines to reduce exposure of raw logs
- Sector: healthcare, finance, regulated industries
- Tools/products: federated SFT; DP noise mechanisms; secure aggregation
- Dependencies/assumptions: strong privacy guarantees; utility-privacy trade-offs; alignment with regulatory requirements
- Fairness and diversity optimization: multi-objective training that balances accuracy with long-tail exposure and seller/content fairness
- Sector: policy, platform governance
- Tools/products: fairness-aware loss functions; exposure constraints; auditing dashboards
- Dependencies/assumptions: clear fairness definitions; stakeholder buy-in; risk assessment for unintended consequences
- Synthetic log simulation: scenario testing and stress simulation to evaluate recommender robustness before production
- Sector: MLOps, testing, risk management
- Tools/products: “Synthetic Interaction Factory”; controllable generators; shift detectors
- Dependencies/assumptions: realistic simulators; validation metrics beyond Recall/NDCG (e.g., satisfaction, churn)
- Managed augmentation SaaS: cloud providers offering turnkey LLM-I2I augmentation with connectors to common recommender stacks
- Sector: cloud platforms, enterprise ML
- Tools/products: service SLAs; cost controls; governance features
- Dependencies/assumptions: standard APIs; pricing acceptable to SMBs; robust compliance features
- AutoML for augmentation parameters: automate choice of
alpha/β, confidence thresholds, synthetic ratio,K/Mindex sizes per domain- Sector: platform engineering
- Tools/products: Bayesian optimization; bandit tuning; online metric monitoring
- Dependencies/assumptions: reliable online feedback loops; guardrails to prevent metric gaming
- Robustness and shift detection: continual learning and active selection to keep synthetic data aligned with real-world distributions
- Sector: all sectors using recommender systems
- Tools/products: distribution-shift detectors; confidence recalibration; human-in-the-loop review
- Dependencies/assumptions: labeled drift events; scalable monitoring; intervention policies
- Expanded sectors (education, finance, healthcare): long-tail recommendations for courses, financial products, medical devices/content
- Sector: education, fintech, healthcare
- Tools/products: domain-specific LLMs; risk-aware filters; explainability modules
- Dependencies/assumptions: strict regulatory compliance (e.g., suitability, medical safety); high-quality metadata; user consent
- Sustainability impact studies: quantify carbon and cost benefits from keeping small I2I models while using offline augmentation
- Sector: ESG, operations
- Tools/products: energy/cost telemetry; optimization tooling for batch scheduling
- Dependencies/assumptions: accurate energy accounting; willingness to prioritize sustainability KPIs
- Open-source library and standards: community-driven toolkit with pluggable backbones, reproducible pipelines, and synthetic data governance
- Sector: academia, open-source ecosystem
- Tools/products: connectors to Implicit/YoutubeDNN/Swing; deepspeed configs; governance templates for synthetic data use
- Dependencies/assumptions: maintainers and funding; consensus on best practices; licensing that permits commercial use
Glossary
- A/B testing: A controlled online experiment comparing two system variants to assess impact on metrics. "We conducted a rigorous one-week A/B test with the following experimental design"
- AEDS: A proprietary, billion-scale industrial dataset from AliExpress used to evaluate recommender systems. "AEDS is a billion-scale industrial dataset collected from AliExpress.com"
- Amazon Review Dataset (ARD): A public benchmark containing user-item interactions and reviews across product categories. "ARD is one of the most widely adopted public recommendation benchmarks, containing comprehensive user and item information"
- BM25: A ranking function used as a distance metric to compute item similarity in recommendation. "The widely-used distance metric function BM25 is selected as the baseline method."
- Bipartite graph: A graph with two disjoint node sets (e.g., users and items) used to model interactions for similarity computation. "Swing, a widely adopted I2I retrieval method in industrial recommendation systems, computes item similarity using a bipartite graph."
- BPR (Bayesian Personalized Ranking): A matrix factorization approach optimizing pairwise preferences to improve recommendations. "We adopt BPR, a model that enhances recommendation accuracy by maximizing the preference distance with items clicked and not clicked by the same user, as the baseline for matrix factorization-based I2I."
- Chain-of-Thought (COT): A prompting technique where models generate reasoning steps to enhance data or predictions. "In-context Chain-of-Thought (COT) dataset"
- Cold-start items: Items with little to no interaction data, making them difficult to recommend. "However, this method is primarily limited to small-scale cold-start items."
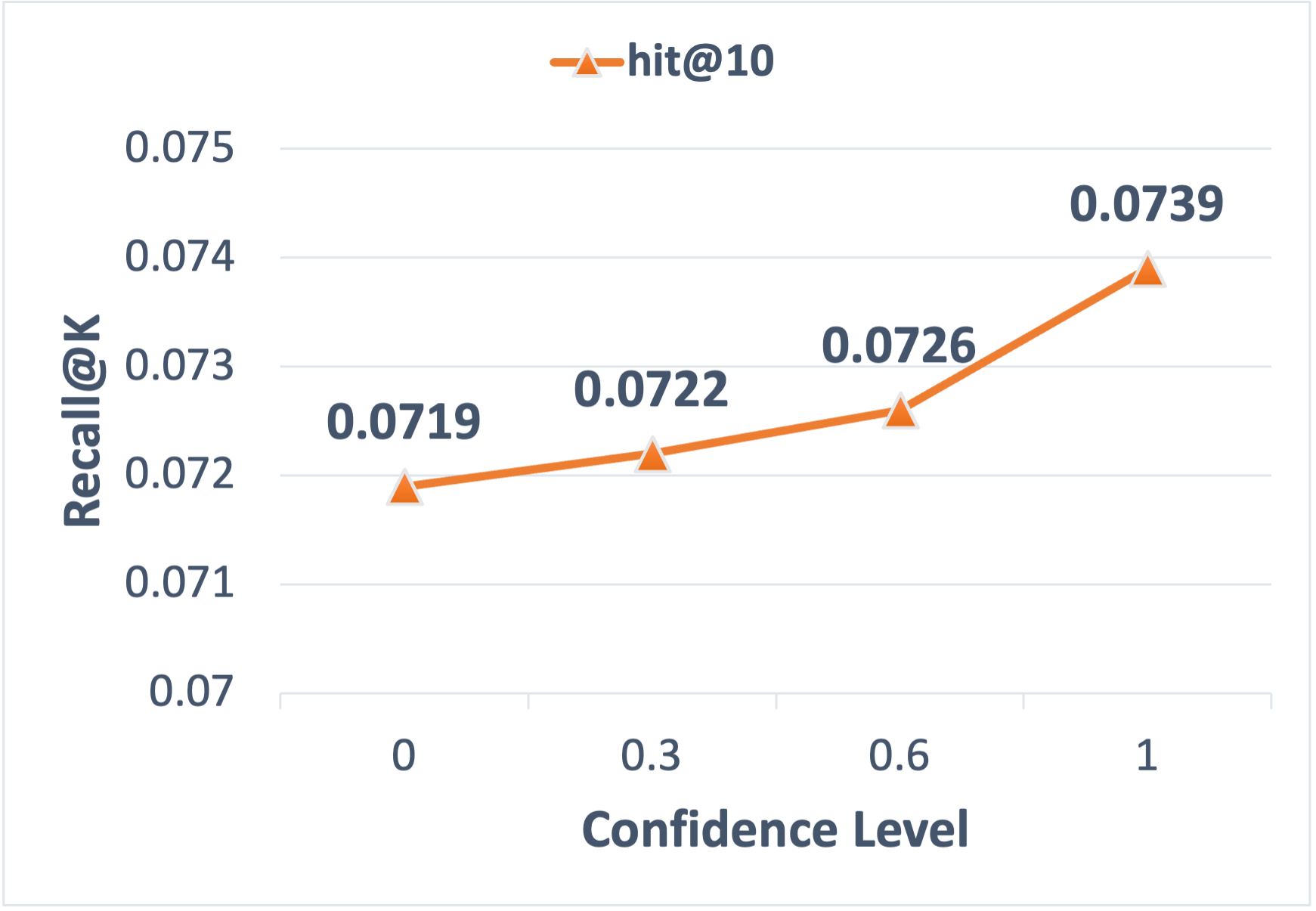
- Confidence level: The probability score from a discriminator indicating trust in synthetic interactions. "First, the higher the confidence level of the synthesized data, the better the training model will be."
- CTR (click-through rate): The percentage of impressions that result in user clicks, used to evaluate recommender effectiveness. "CTR and CVR are abbreviations for click-through rate and conversion rate, respectively."
- CVR (conversion rate): The percentage of clicks that result in purchases, measuring recommendation quality. "CTR and CVR are abbreviations for click-through rate and conversion rate, respectively."
- Data augmentation: Techniques to expand or enhance training data to improve model performance. "Current data augmentation methods primarily focus on either data generation or data selection."
- Data-centric methods: Approaches that improve recommendation performance by refining data rather than changing model architecture. "Data-centric approaches can be classified into heuristic-based and model-based methods"
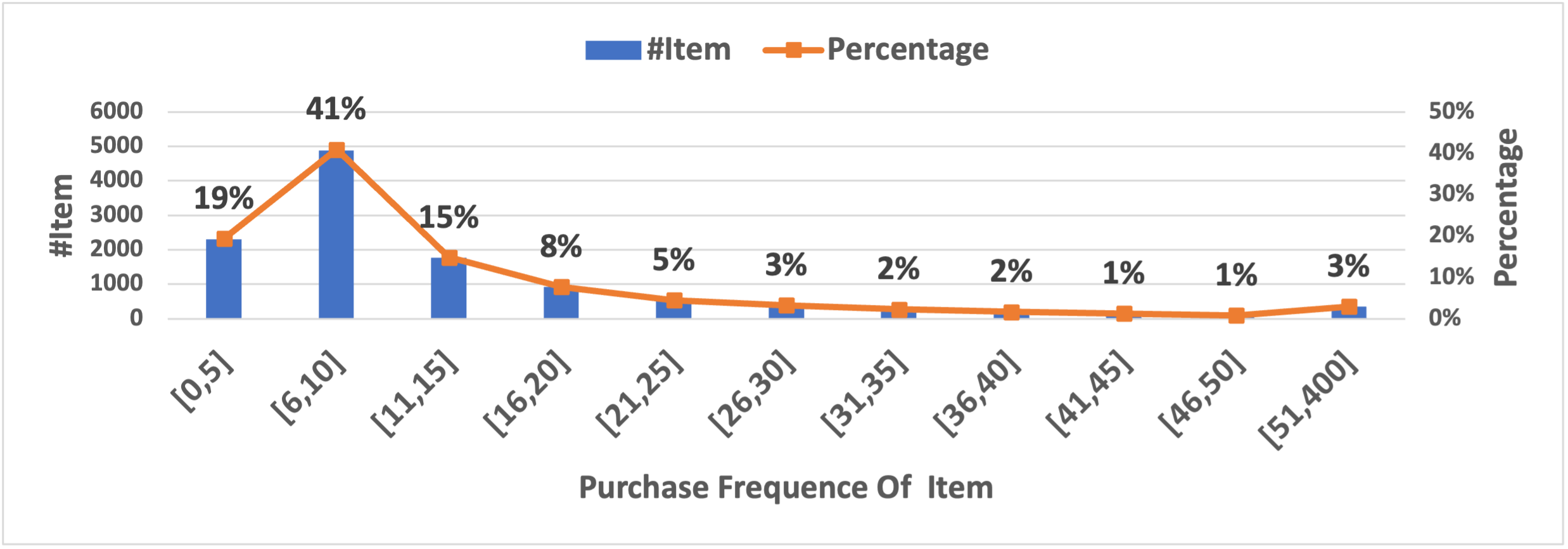
- Data sparsity: A condition where many items or users have few interactions, hindering effective modeling. "data sparsity poses a significant challenge, particularly for long-tail items."
- DeepSpeed Zero2: A distributed training optimization strategy used to accelerate large-model fine-tuning. "We utilized DeepSpeed Zero2 and FlashAttention2 to accelerate training."
- Distribution drift: A mismatch between synthetic and real data distributions that can degrade model performance. "Such a distribution drift can result in degrading the trained model's performance."
- FlashAttention2: An efficient attention implementation that speeds up transformer training/inference. "We utilized DeepSpeed Zero2 and FlashAttention2 to accelerate training."
- GMV (gross merchandise value/volume): A business metric measuring total sales value on a platform. "leads to 6.02% and 1.22% improvements over the existing I2I-based model in terms of recall number (RN) and gross merchandise value (GMV), respectively."
- Implicit feedback: Indirect user signals like clicks and views used as preference indicators. "This phenomenon is particularly pronounced in I2I algorithms that rely on implicit feedback."
- Inverted index: A lookup structure mapping items to their recommended neighbors for fast online retrieval. "an I2I inverted index to enable real-time online responses"
- Item-to-Item (I2I): A recommendation paradigm that finds items similar to those a user interacted with. "Item-to-Item (I2I) recommendation models have become a cornerstone of many real-world recommendation systems"
- L2P: The proportion of purchasing users reached by recommendations, used in online evaluation. "L2P denotes the percentage of users who purchased being exposed to the recommendations."
- Latency: The time taken by the system to process and return results, affecting user experience. "Latency quantifies the processing time required for retrieval."
- LLama2-7B-Chat: A LLM variant used as the base for fine-tuning in experiments. "we selected LLama2-7B-Chat as the base LLM model."
- LLM-CF: An LLM-enhanced collaborative filtering method using in-context COT-based synthesized data. "LLM-CF is a notable algorithm that improves recommendation performance by identifying similar samples within a constructed In-context Chain-of-Thought (COT) dataset."
- LLM-ERS (LLM Enhanced Recommender Systems): Systems that leverage LLMs to enhance recommendation tasks. "LLM Enhanced Recommender Systems (LLM-ERS) has gained considerable attention recently"
- LLM-based data discriminator: An LLM fine-tuned to filter weak or noisy synthetic interactions. "we build an LLM-based data discriminator to filter out weak or noisy user-item interactions"
- LLM-based data generator: An LLM fine-tuned to synthesize plausible user-item interactions to combat sparsity. "we first learn an LLM-based data generator with user historical behavior data to synthesize some user-item interaction data"
- Long-tail aware loss function: A training objective that upweights rare items to improve generation for underrepresented products. "we propose a long-tail aware loss function to focus on learning the underlying patterns of long-tail items"
- Long-tail items: Rarely interacted items that are underrepresented in training data but important for diversity. "long-tail items are often difficult to recommend due to historical user-item interaction records scarcity."
- Negative sampling: Selecting non-interacted items as negatives to train discriminative models. "random global negative sampling"
- NDCG@K (normalized discounted cumulative gain): A ranking metric evaluating the order quality of top-K recommendations. "NDCG@K measures the correctness of the ranking order among the retrieved K items."
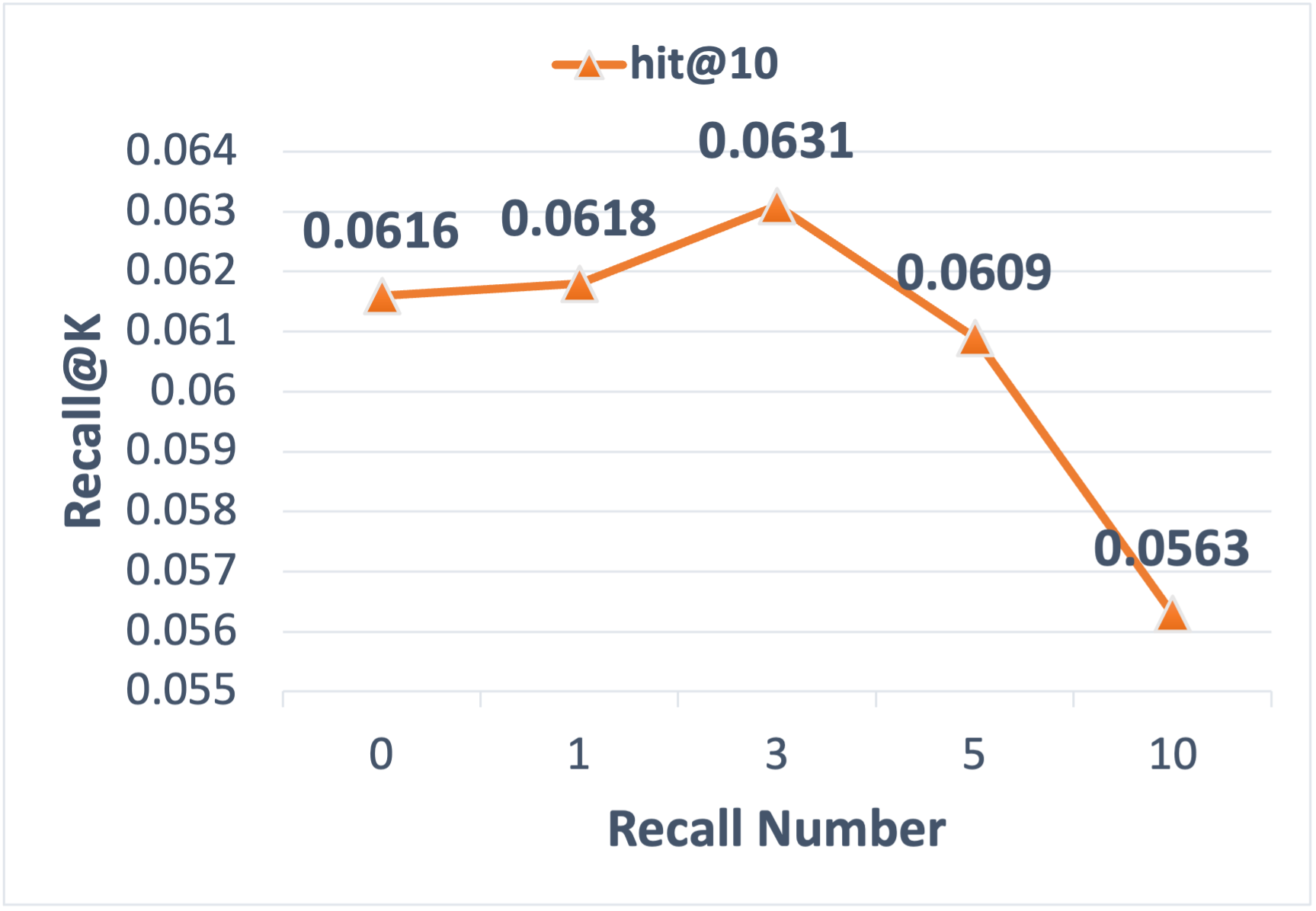
- Recall number (RN): The total count of items retrieved by the recall component in online evaluation. "recall number (RN)"
- Recall@K: The proportion of relevant items found within the top K recommendations. "We define Recall@K as the recall accuracy for the top K items"
- Supervised Fine-Tuning (SFT): Training an LLM on labeled domain data to adapt it for specific tasks. "we adopt the Supervised Fine-Tuning (SFT) technique"
- Swing: An industrial I2I retrieval algorithm computing item similarity via graph-based co-occurrence. "Swing, a widely adopted I2I retrieval method in industrial recommendation systems, computes item similarity using a bipartite graph."
- Top-K: The practice of keeping only the highest-ranked K items for efficiency and serving constraints. "only the top recommendation items are retained and stored in the engine."
- YoutubeDNN: A deep retrieval model widely used for recommendation candidate generation. "We employ YoutubeDNN, a widely-used deep retrieval model, as our backbone."
Collections
Sign up for free to add this paper to one or more collections.