- The paper introduces a unified SDR framework that integrates audio encoding with LLM processing to overcome error propagation in cascaded systems.
- It employs a four-stage training strategy, including ASR and joint fine-tuning with LoRA, to enhance performance across diverse SDR scenarios.
- Experimental results demonstrate superior accuracy on metrics like CER and saCER, validating the model in both in-domain and out-of-domain tests.
Overview
The paper introduces SpeakerLM, an end-to-end model that combines LLMs with audio processing to perform Speaker Diarization and Recognition (SDR). The approach integrates Speaker Diarization (SD) and Automatic Speech Recognition (ASR) into a unified framework using a multimodal LLM (MLLM). This model overcomes the limitations inherent in traditional cascaded systems by enabling simultaneous handling of both audio encoding and speaker attribution.
Model Architecture
SpeakerLM utilizes a sophisticated architectural setup to achieve joint SDR. It consists of an audio encoder from a pre-trained SenseVoice-large model, which is followed by a Transformer-based projector to align audio embeddings with the text embedding space. The audio features are then processed by a linguistic model, Qwen2.5-7B-Instruct, a capable LLM. Speaker registration is handled flexibly by using pre-trained speaker embeddings, which are processed through a linear layer for dimensional compatibility.
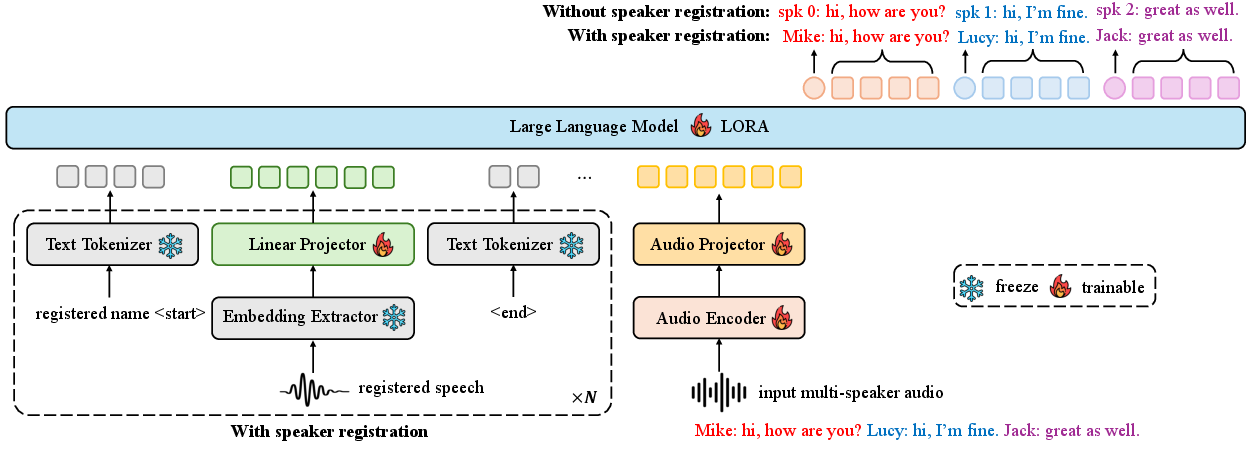
Figure 1: Overall architecture of the proposed SpeakerLM. When speaker registration is not performed, each speaker in the transcript is identified by an anonymous ID. With speaker registration enabled, speakers are labeled by their actual names.
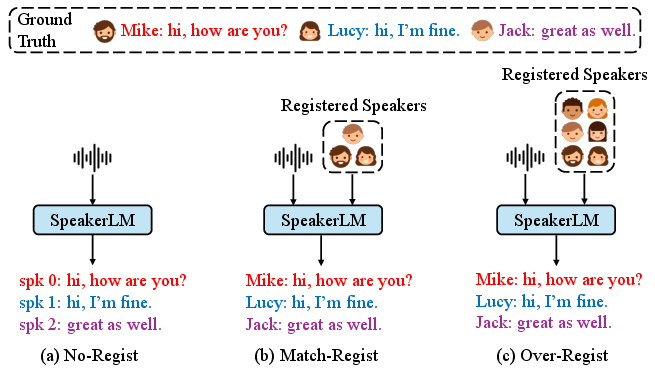
The system architecture supports three speaker registration modes:
Training Strategy
SpeakerLM employs a four-stage training strategy to maximize performance across different SDR scenarios:
- ASR Training Stage: Using ASR data to optimize the model for accurate speech recognition, using a LoRA technique to preserve LLM's linguistic capabilities during adaptation.
- Simulated SDR Training: Using synthetic SDR data to align audio-text modalities quickly and effectively.
- Real Data Training: Fine-tuning with real-world SDR data to capture practical acoustic characteristics.
- Joint Fine-tuning: Comprehensive fine-tuning across all components, leveraging LoRA to enhance joint optimization.
Experimental Results
The model's performance was tested on in-domain and out-of-domain datasets, illustrating its capacity to outperform state-of-the-art SDR systems. Specifically, SpeakerLM demonstrated remarkable improvements in metrics such as Character Error Rate (CER), concatenated minimum permutation CER (cpCER), and speaker-attributed CER (saCER).
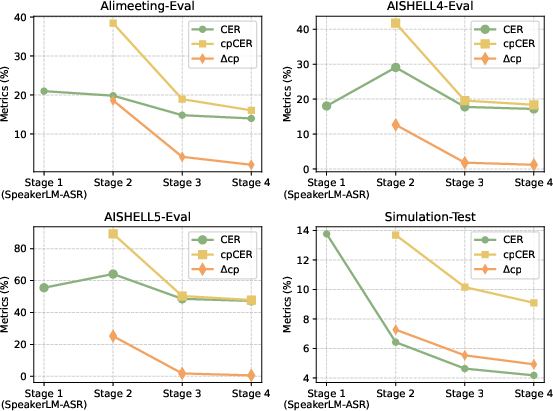
Figure 3: The performance of SpeakerLM on test sets under No-Regist condition across different training stages.
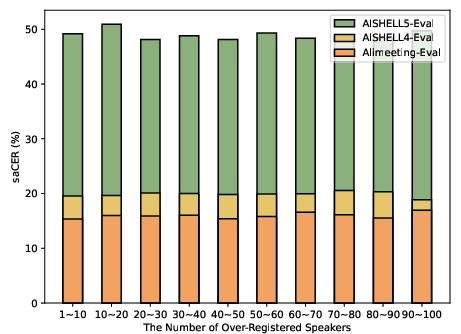
Figure 4: The saCER of SpeakerLM under Over-Regist condition with different numbers of over-registered speakers.
SpeakerLM showed robustness and scalability, with superior results in both scenarios with and without speaker registration. It particularly excels by minimizing error propagation issues that affect traditional cascaded SDR frameworks.
Implications and Future Work
SpeakerLM's application demonstrates the potential of MLLMs in SDR, enabling systems that handle complex multi-speaker environments efficiently. This model's architecture shows promise for future enhancements, such as refining speaker attribution with more advanced registration mechanisms or integrating additional modalities like visual data for richer context recognition.
The system's ability to scale with data suggests potential for expanding its application to various languages and environments, potentially developing more generalized models for global adoption in automatic transcription systems.
Conclusion
SpeakerLM presents a significant advancement in the domain of SDR systems by combining multimodal processing with language modeling. By using an end-to-end approach, it mitigates issues arising from error propagation found in cascaded systems and provides a flexible framework adaptable to diverse speaker settings. The paper sets a benchmark for further exploration into multimodal modeling, highlighting the increasing role of LLMs in audio processing tasks.