DINOv3
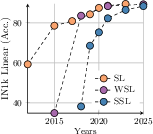
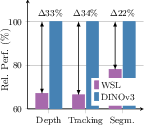
Abstract: Self-supervised learning holds the promise of eliminating the need for manual data annotation, enabling models to scale effortlessly to massive datasets and larger architectures. By not being tailored to specific tasks or domains, this training paradigm has the potential to learn visual representations from diverse sources, ranging from natural to aerial images -- using a single algorithm. This technical report introduces DINOv3, a major milestone toward realizing this vision by leveraging simple yet effective strategies. First, we leverage the benefit of scaling both dataset and model size by careful data preparation, design, and optimization. Second, we introduce a new method called Gram anchoring, which effectively addresses the known yet unsolved issue of dense feature maps degrading during long training schedules. Finally, we apply post-hoc strategies that further enhance our models' flexibility with respect to resolution, model size, and alignment with text. As a result, we present a versatile vision foundation model that outperforms the specialized state of the art across a broad range of settings, without fine-tuning. DINOv3 produces high-quality dense features that achieve outstanding performance on various vision tasks, significantly surpassing previous self- and weakly-supervised foundation models. We also share the DINOv3 suite of vision models, designed to advance the state of the art on a wide spectrum of tasks and data by providing scalable solutions for diverse resource constraints and deployment scenarios.

















































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased to be concrete and actionable for future work.
Data curation, composition, and ethics
- Quantify selection bias from using Instagram-only web data (e.g., geography, demographics, topics) and its downstream impact on fairness and domain generalization; provide bias audits across protected attributes and content types.
- Reproducibility of the data pipeline: the curated 1.689B-image set (LVD-1689M) is not available; specify exact filtering, deduplication, near-duplicate thresholds, and sampling seeds, or release an open substitute and its statistics.
- Ablate the 10% homogeneous ImageNet-1k batch ratio: sweep ratios and assess trade-offs on global vs dense tasks, OOD robustness, and domain transfer; test removal of ImageNet-1k entirely.
- Analyze the effect of clustering vs retrieval curation at scale beyond 200k steps (full 1M schedule), including how each scales with model size, and whether mixture benefits persist for larger backbones.
- Provide a detailed breakdown of data diversity/coverage (object/scene taxonomies), duplication rates, and content moderation categories retained/removed.
- Clarify legal/ethical considerations and privacy safeguards (consent, memorization risk, personal data leakage) and quantify memorization via membership inference or canary exposure tests.
Gram anchoring method
- Formalize the Gram anchoring objective: exact loss definition, normalization, layers/features used, temperature, weighting schedules, and computational cost; provide pseudocode to ensure reproducibility.
- Theoretical explanation: why and when Gram anchoring mitigates patch-level inconsistency; relate to optimization dynamics (eigenspectrum, attention entropy, CLS dominance) and provide causal evidence.
- Sensitivity analysis: sweep Gram loss weight, which layers to anchor (early/mid/late), anchor frequency, and teacher snapshot cadence; measure Pareto frontier between global accuracy and dense quality.
- Teacher choice for anchoring: justify using early snapshots vs EMA teachers vs checkpoints from different training stages; compare single static teacher vs rolling teacher and their compute/latency trade-offs.
- Evaluate potential lock-in of early-teacher biases/errors: does anchoring prevent beneficial representation drift for rare/long-tail concepts?
- Generality across objectives: test Gram anchoring with other SSL families (e.g., MAE/JEPA, VICReg/L) and with supervised/weakly supervised pretraining to assess method universality.
- Robustness to resolution/AR changes under Gram anchoring: verify that anchoring does not overfit to specific crop statistics or harm extreme-resolution behavior.
Architecture and optimization
- Positional embeddings: ablate axial RoPE and box-jittering ranges (e.g., s ∈ [0.25, 3]) and their effect on resolution/AR extrapolation, dense tasks, and metric-sensitive geometry tasks.
- Register tokens: quantify the contribution and optimal number/placement of register tokens for dense features; compare with register-free techniques or learned feature adapters.
- Patch size 16 vs 14: control for token budget and isolate the impact on dense/local detail vs throughput; test mixed patch sizes or hybrid hierarchical tokenization.
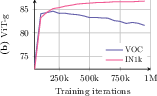
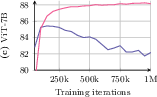
- Constant schedules: provide head-to-head comparisons with cosine schedules and other long-horizon schedulers across total steps, including convergence speed, stability, and compute efficiency.
- Koleo regularizer: ablate weight, batch size (local vs global), and interaction with Gram anchoring; measure its effects on feature isotropy and clustering behavior.
- Training stability at scale: report failure modes, collapse indicators, and monitoring signals; share intervention strategies (e.g., temperature schedules) to avoid late-stage degradation.
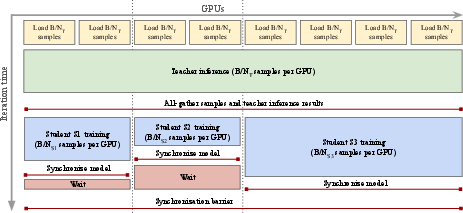
Distillation and model family
- Single-teacher multi-student distillation: specify losses (e.g., cosine, feature matching, logits), temperatures, layer mapping strategies, and training data; release ablations on preserving dense feature quality.
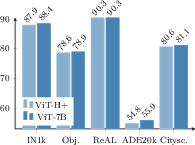
- Measure fidelity: quantify how much dense and global performance is lost from 7B→Small/Base/Large; provide feature-similarity metrics and downstream gaps by task.
- Data for distillation: test in-domain vs out-of-domain and curriculum strategies; evaluate whether student inherits the teacher’s resolution scalability and Gram improvements.
- Architecture diversity: evaluate how well ConvNeXt vs ViT students retain the teacher’s dense properties; test cross-architecture anchoring.
Evaluation breadth and protocols
- Decoder dependence: for “frozen backbone SOTA,” report decoder/head capacity, training budget, and standardized protocols; ablate light vs heavy heads to isolate backbone contributions.
- Dense tasks scope: extend evaluation to optical flow, stereo, depth (indoor/outdoor), pose estimation, SLAM/keypoint matching, and high-res instance/semantic segmentation; quantify small-object/edge-detail performance.
- Cross-domain generalization: systematically assess transfer to medical, histopathology, biology, and remote sensing beyond the single satellite case; report negative transfer and data-mixing strategies for robustness.
- OOD robustness: expand beyond ObjectNet to distributional shifts (ImageNet-C/A/R, synthetic corruptions, weather, viewpoint) and measure calibration and abstention behavior.
- High-resolution consistency: provide quantitative tests for tiling/cropping invariance, patch-boundary artifacts, and multi-scale consistency at 2k–8k resolutions.
- Comparisons with WSL/multimodal baselines: ensure consistent training/evaluation budgets and decoders; include recent PE/SigLIP2/AM-RADIO dense variants under identical protocols.
Robustness, safety, and security
- Adversarial robustness: evaluate Lp-bounded and patch attacks; analyze whether Gram anchoring hardens or weakens robustness relative to DINOv2/CLIP.
- Spurious correlations: test controlled datasets for shortcut reliance; measure subgroup robustness and worst-group accuracy.
- Continual/lifelong learning: substantiate the claim by running streaming or incremental benchmarks; test whether constant schedules and Gram anchoring mitigate catastrophic interference.
Efficiency, scalability, and reproducibility
- Compute/energy reporting: detail GPU hours, training efficiency, memory footprint, and carbon estimates for 7B at 1M steps; provide scaling laws for accuracy vs tokens/model size/steps.
- Inference efficiency: benchmark throughput/latency/memory at high resolutions and with tiling; provide guidance for edge deployment and on-device trade-offs.
- Release artifacts: clarify which weights, code, and recipes (including Gram anchoring and distillation) will be released and under what licenses; include seeds and exact configs to enable replication.
Collections
Sign up for free to add this paper to one or more collections.