- The paper introduces DEIMv2, which leverages DINOv3 backbones and a Spatial Tuning Adapter to enhance multi-scale feature representation.
- It refines the deformable attention decoder with SwiGLUFFN and RMSNorm, achieving superior performance on the COCO benchmark.
- Ultra-lightweight variants like Pico and Atto are developed to maintain efficiency for resource-constrained applications without sacrificing accuracy.
Real-Time Object Detection Meets DINOv3
In recent years, there has been significant progress in real-time object detection, particularly with the introduction of Transformer-based models like DEIM and DINOv3. This paper presents DEIMv2, an advanced real-time object detector that leverages DINOv3 features and integrates a novel Spatial Tuning Adapter (STA) to optimize detection accuracy and efficiency across diverse deployment scenarios.
Architectural Advancements
Backbone Integration with STA
DEIMv2 capitalizes on the pretrained backbones of DINOv3, using Vision Transformer (ViT) variants like ViT-Small and ViT-Tiny. The largest models (DEIMv2-X and DEIMv2-L) utilize strong semantic representations derived from DINOv3 with the aid of the STA, which transforms single-scale outputs into multi-scale features, enriching semantic depth with fine-grained details.
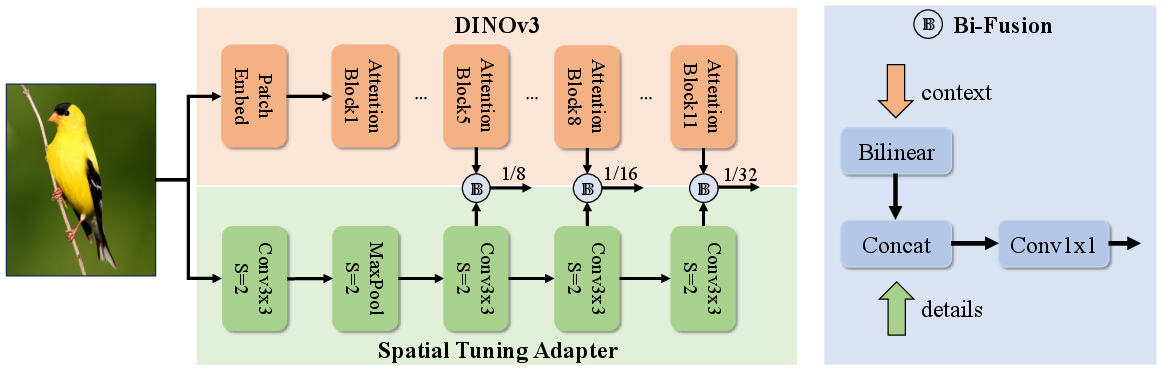
Figure 1: Backbone design of our ViT-based variants. We integrate DINOv3 with the proposed Spatial Tuning Adapter (STA).
This design allows DEIMv2 to effectively handle real-time object detection tasks by enhancing feature representation, critical for accurately detecting objects of varying sizes.
Ultra-Lightweight Variants
For scenarios constrained by computational resources, DEIMv2 introduces ultra-lightweight models such as Pico and Atto, employing HGNetv2 backbones with pruned depth and width. This enables the models to operate efficiently within limited budgets while maintaining competitive performance.
Enhanced Detection Mechanisms
Simplified and Efficient Decoder
The paper improves upon previous DEIM models by refining the standard deformable attention decoder. It incorporates SwiGLUFFN for enhanced nonlinear representation, RMSNorm for stable training, and shares query position embeddings across decoder layers to reduce computational overhead. This contributes to superior efficiency and maintains high performance.
Dense Object-to-Object Augmentation
DEIMv2 expands on Dense O2O augmentation by introducing Copy-Blend object-level augmentation. Unlike Copy-Paste, Copy-Blend merges new objects into images, improving detection convergence and performance without overshadowing existing features.
Extensive experiments demonstrate that DEIMv2 consistently outperforms existing state-of-the-art detectors across all model sizes and resource settings on the COCO benchmark. Specifically, DEIMv2-X achieves 57.8 AP with 50.3M parameters, surpassing predecessors with larger parameter sizes. Similarly, DEIMv2-S breaks the 50 AP milestone with under 10M parameters.
Trade-offs and Efficiency
A key observation is DEIMv2's superior performance on medium-to-large objects, attributed to the strength of DINOv3’s semantic features. However, performance for small objects remains relatively unchanged, presenting an area for future improvement. The consistent enhancements across various scales underscore DEIMv2’s scalability and flexibility for deployment.
Implications and Future Directions
DEIMv2 effectively adapts DINOv3 features for real-time object detection, offering models ranging from high-performance to ultra-lightweight. The scalability and versatility of DEIMv2 provide substantial practical applicability, from edge devices to high-end systems, facilitating broader adoption of efficient real-time detection technologies.
Future research could focus on optimizing small-object detection and further reducing latency through techniques like Flash Attention, enhancing DEIMv2's efficiency. Implementing these models in varied real-world environments could also yield new insights into optimizing detection frameworks for specific application domains.
Conclusion
DEIMv2 represents a significant advancement in real-time object detection by integrating DINOv3 features with the innovative STA. It delivers remarkable performance improvements across a spectrum of model configurations, addressing diverse deployment requirements from mobile to GPU-based environments. This work lays the foundation for future enhancements in object detection, emphasizing the potential for integrating detailed semantic representations from now widely recognized ViT architectures.