RF-DETR: Neural Architecture Search for Real-Time Detection Transformers
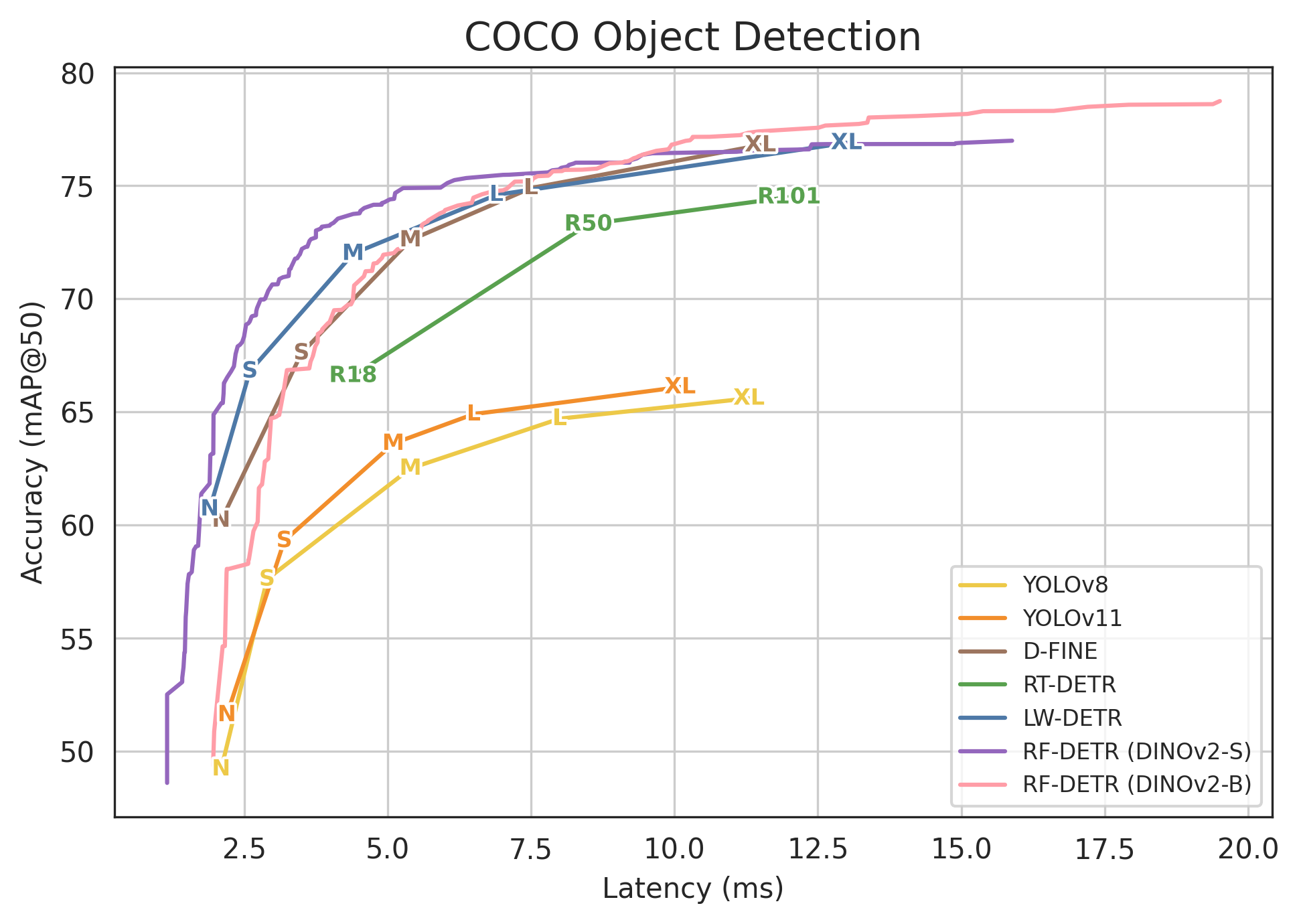
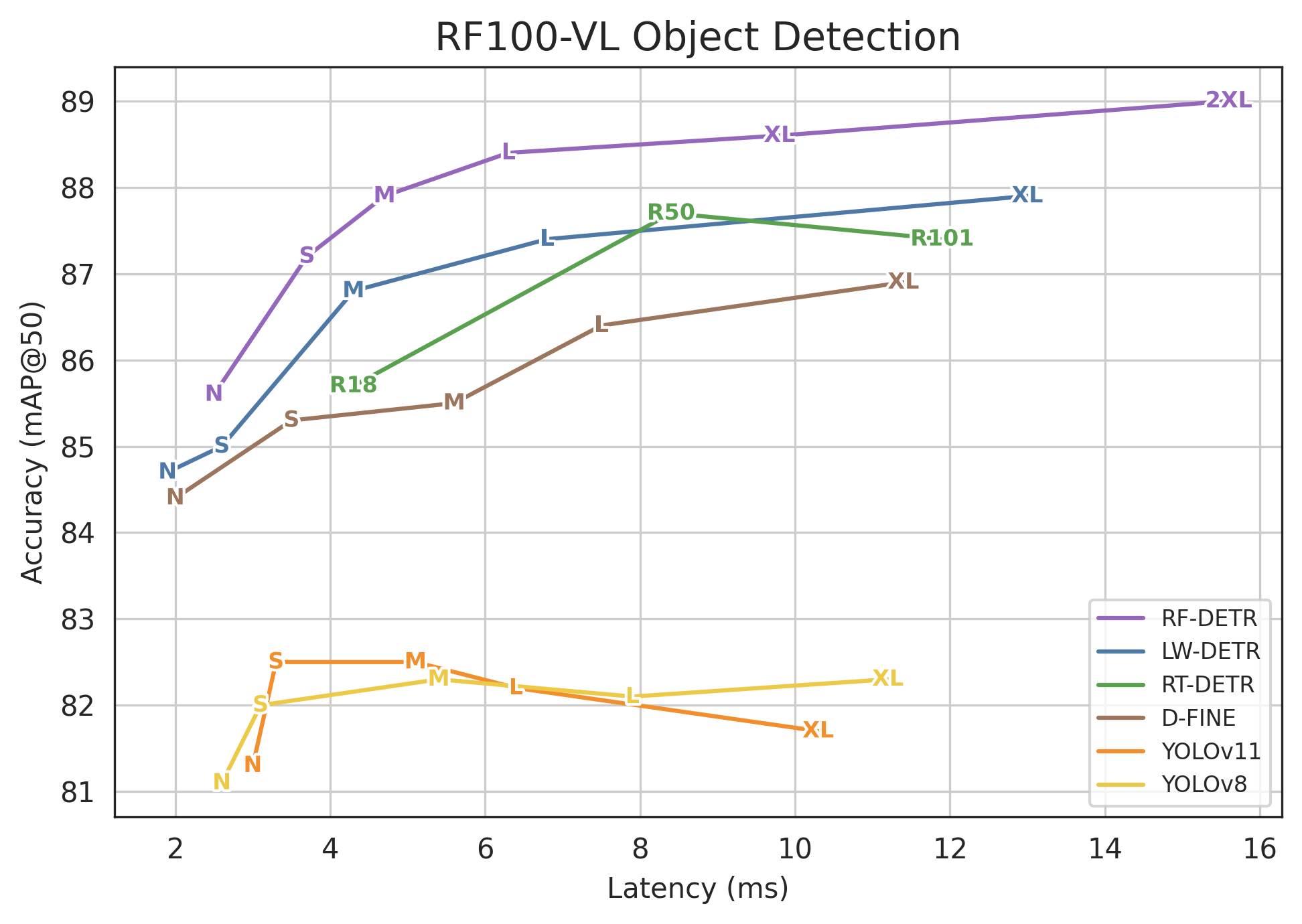
Abstract: Open-vocabulary detectors achieve impressive performance on COCO, but often fail to generalize to real-world datasets with out-of-distribution classes not typically found in their pre-training. Rather than simply fine-tuning a heavy-weight vision-LLM (VLM) for new domains, we introduce RF-DETR, a light-weight specialist detection transformer that discovers accuracy-latency Pareto curves for any target dataset with weight-sharing neural architecture search (NAS). Our approach fine-tunes a pre-trained base network on a target dataset and evaluates thousands of network configurations with different accuracy-latency tradeoffs without re-training. Further, we revisit the "tunable knobs" for NAS to improve the transferability of DETRs to diverse target domains. Notably, RF-DETR significantly improves on prior state-of-the-art real-time methods on COCO and Roboflow100-VL. RF-DETR (nano) achieves 48.0 AP on COCO, beating D-FINE (nano) by 5.3 AP at similar latency, and RF-DETR (2x-large) outperforms GroundingDINO (tiny) by 1.2 AP on Roboflow100-VL while running 20x as fast. To the best of our knowledge, RF-DETR (2x-large) is the first real-time detector to surpass 60 AP on COCO. Our code is at https://github.com/roboflow/rf-detr


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to build fast and accurate computer programs that can find objects in images (like cars, people, or animals). The method is called RF-DETR. It helps pick the best model settings for any dataset and device, so the detector runs in real time (very quickly) without losing much accuracy.
What questions did the researchers ask?
The paper looks at three simple questions:
- Can we make “specialist” object detectors (trained for a fixed set of labels) fast and as accurate as big “open-vocabulary” detectors (which use text and images together)?
- Can we automatically find the best trade-off between accuracy and speed for different datasets and hardware?
- How can we measure speed (latency) fairly and consistently across different models and computers?
How did they do it?
The researchers combined a strong, pre-trained vision model with a flexible detector, then used a technique called “weight-sharing neural architecture search” to explore many design choices quickly.
Building the base detector
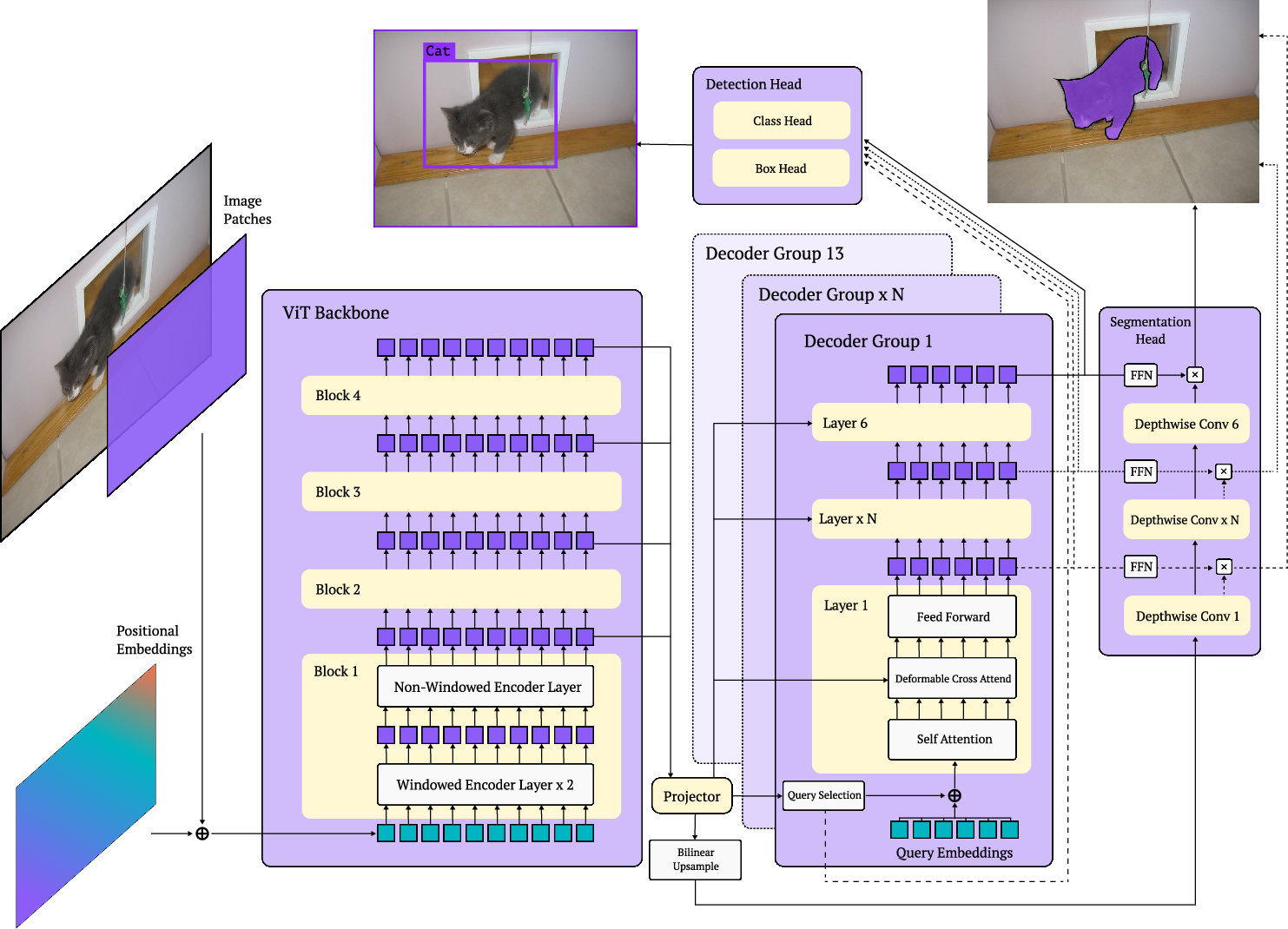
- They start with a powerful pre-trained vision backbone (DINOv2) that already “knows” a lot about images from internet-scale training.
- They use a DETR-style detector (DETR stands for Detection Transformer), which avoids extra steps like non-maximum suppression (NMS) and is easier to make fast.
- They add a simple segmentation head so the model can also draw masks around objects (not just boxes).
Searching with “knobs” (like tuning a game’s settings)
Instead of training a new model every time, they train one flexible model that can work under many settings. Think of it like teaching a single athlete to perform well in different shoes, speeds, and track lengths.
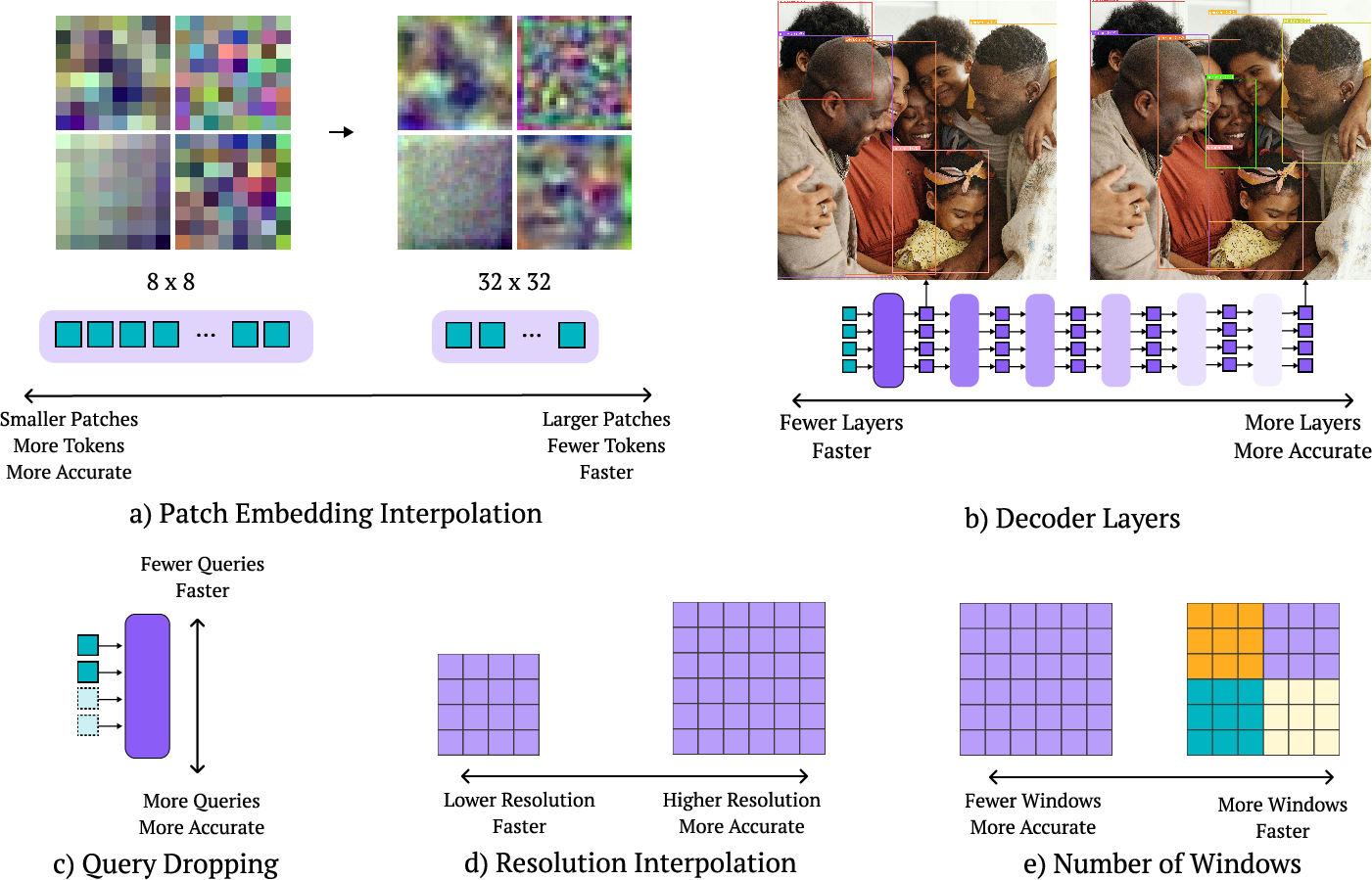
During training, they randomly switch between settings, so the model learns to handle many configurations. Later, they pick the best one for their needs without retraining. The main “knobs” they vary:
- Image resolution: Bigger images help find small objects but take longer.
- Patch size: Like the size of tiles the image is cut into; smaller tiles give more detail but cost more time.
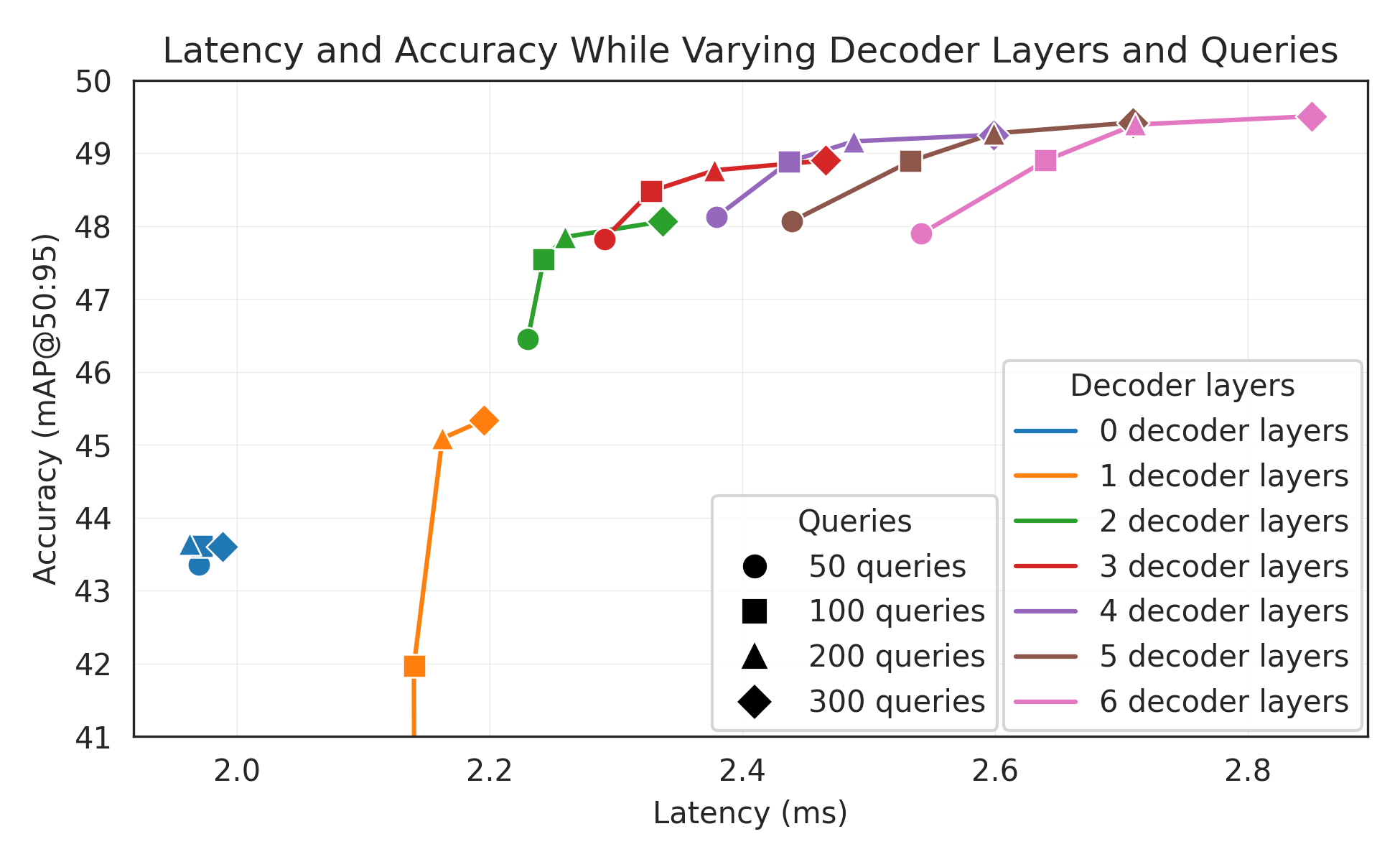
- Decoder layers: More layers can improve accuracy but slow down inference; they can skip layers at test time.
- Number of query tokens: Think of these like “slots” the model uses to propose objects; fewer slots go faster.
- Windowed attention: Limits how much of the image each part “looks” at to save time while keeping useful context.
This approach is called weight-sharing NAS because one set of shared weights supports many model variants. It’s much more efficient than training each variant separately.
Making segmentation fast
- The segmentation head uses a lightweight “pixel embedding map,” so masks are created by simple dot products (like matching patterns), which is fast.
- They pre-train on a big dataset (Objects365) with masks generated by another tool (SAM2) to boost performance.
Measuring speed fairly
Speed numbers can be misleading if measured differently. The authors standardize latency benchmarks by:
- Including all parts of the model that run at inference (for YOLO-like models, they include NMS and converting “prototypes” into masks).
- Using the same model format for accuracy and latency (avoiding mismatches between FP32 and FP16 that can unfairly improve speed or hurt accuracy).
- Adding a short pause (200 ms) between runs to avoid GPU overheating and power throttling, which can make speeds look inconsistent.
What did they find?
The key results (in simple terms):
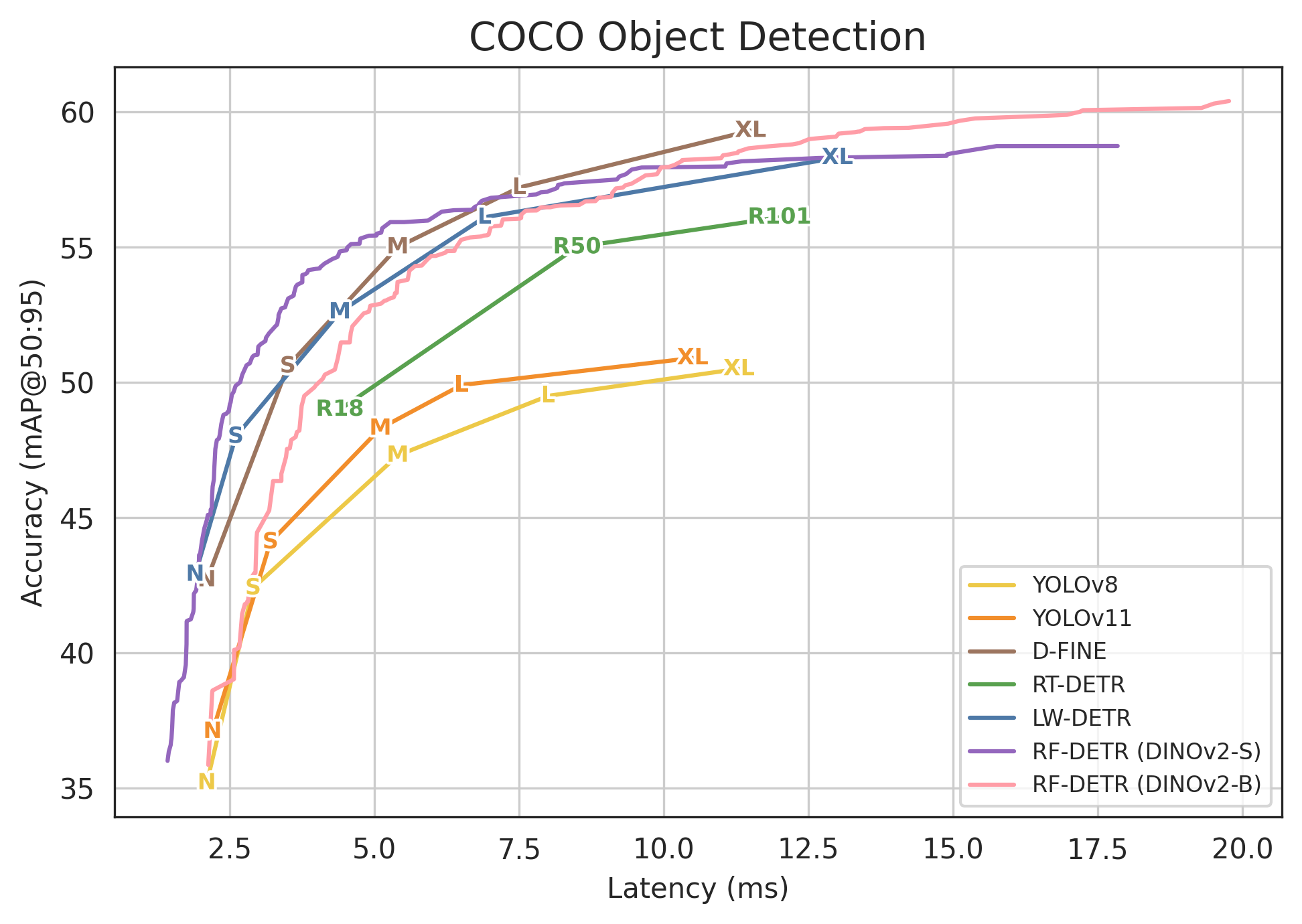
- RF-DETR is very accurate and very fast. On the popular COCO benchmark:
- RF-DETR (nano) gets 48.0 AP, beating other real-time detectors like D-FINE (nano) by 5.3 AP at similar speed.
- RF-DETR (2x-large) is the first real-time detector to surpass 60 AP on COCO.
- On Roboflow100-VL (RF100-VL), a challenging set of 100 diverse, real-world datasets:
- RF-DETR (2x-large) beats GroundingDINO (tiny) while running about 20 times faster.
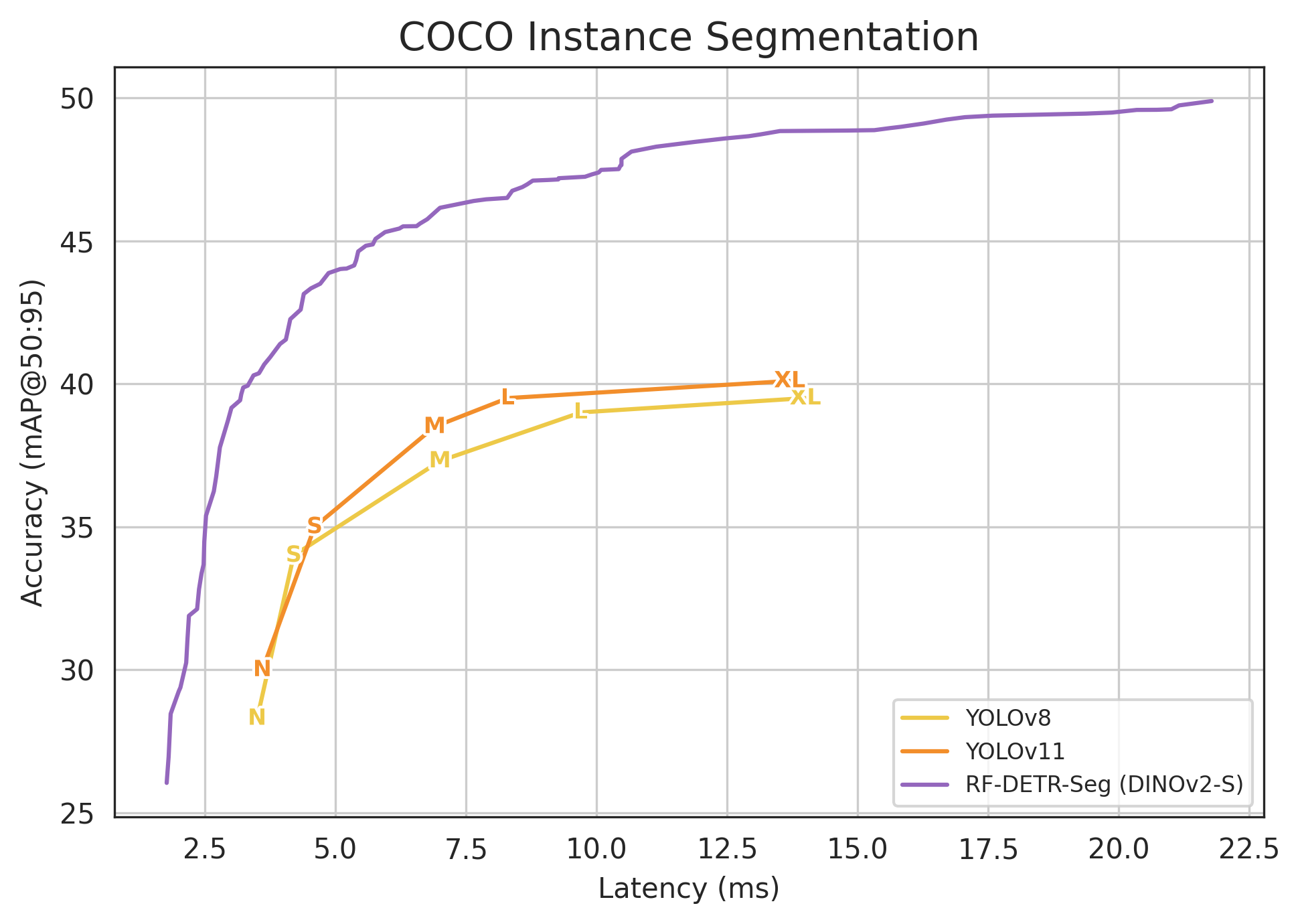
- The segmentation version (RF-DETR-Seg) is also fast and strong:
- RF-DETR-Seg (nano) outperforms YOLOv8-Seg and YOLOv11-Seg while running faster.
- It even beats some heavier non-real-time segmentation models at a fraction of their runtime.
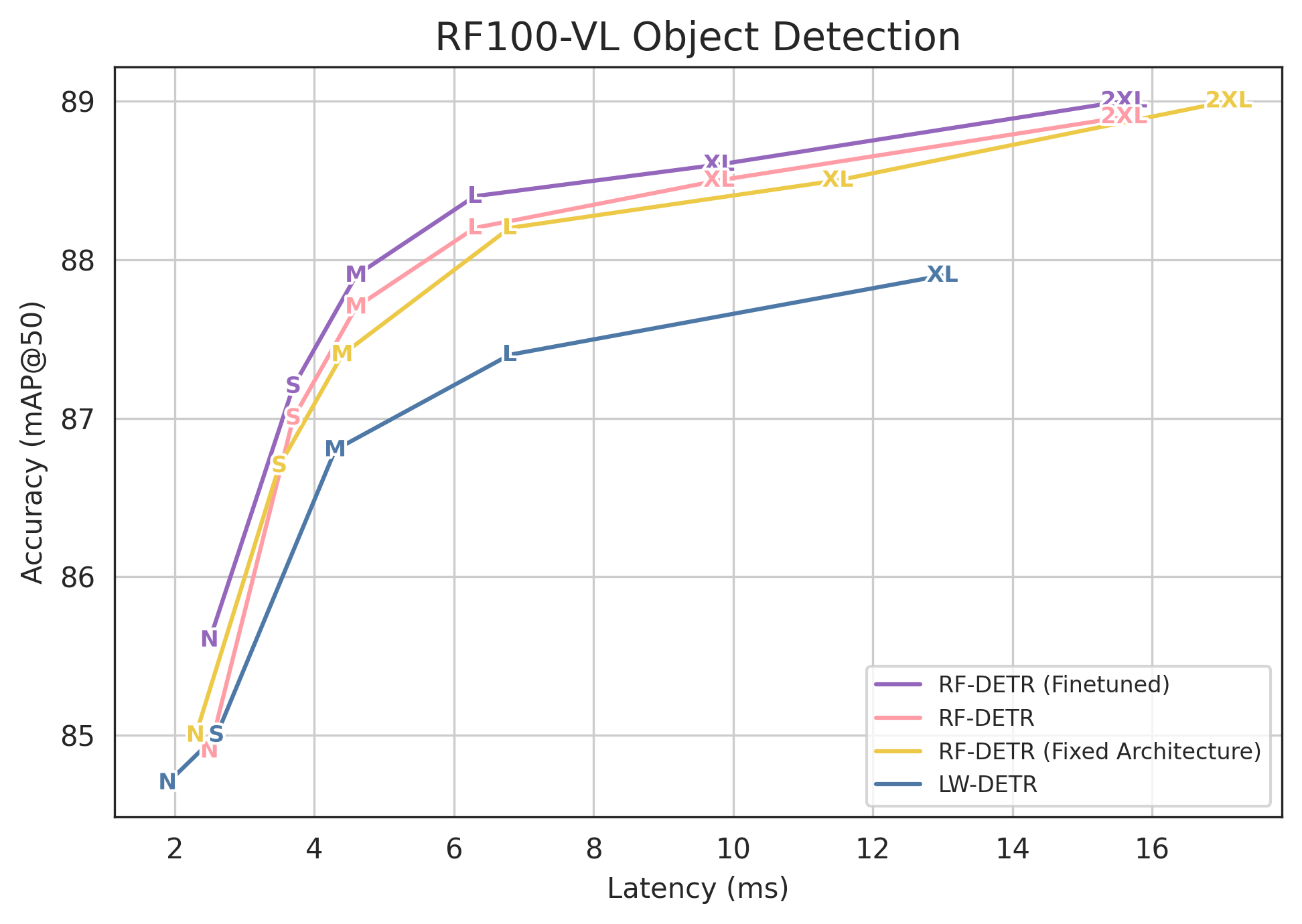
- The weight-sharing NAS approach works: they can pick settings after training to match speed needs without retraining, and many “unseen” combinations still perform well.
Why this is important:
- It shows you don’t need a huge text-image model to get top accuracy. A smart, flexible specialist detector can be both fast and very accurate.
- It proves we can adapt one trained model to different devices and datasets just by choosing the right “knobs.”
Why does this matter?
- Real-world use: Drones, phones, self-driving cars, and robots often need object detection that is fast, reliable, and energy-efficient. RF-DETR makes that easier.
- Tailored to your needs: You can pick high accuracy or low latency depending on your device and task without retraining from scratch.
- Fair comparisons: Their benchmarking method helps the community report speed and accuracy consistently, making future papers easier to compare.
- Better generalization: Because RF-DETR is trained with many settings and uses a strong pre-trained backbone, it handles new, diverse datasets better than detectors tuned just for standard benchmarks.
In short, this research shows a practical path to building object detectors that are both speedy and strong—and easy to tune for different projects—while encouraging fair, trustworthy performance reporting.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what the paper leaves unresolved or insufficiently explored.
- Hardware generalization and sustained throughput:
- Latency and accuracy are primarily benchmarked on NVIDIA T4 with TensorRT; it remains unclear how RF-DETR behaves on other accelerators (A100/L4, mobile NPUs, CPUs), under different drivers, CUDA/TensorRT versions, and with/without CUDA Graphs.
- The proposed 200 ms buffering stabilizes per-inference latency but explicitly does not measure sustained throughput in streaming scenarios; standardized protocols for both latency and throughput under continuous load are missing.
- Energy use, thermal behavior, and power-throttling effects across hardware are not evaluated; a reproducible energy-per-inference metric and thermal stress test protocol are needed.
- Fairness and reproducibility in latency benchmarking:
- Some baselines are reported in PyTorch while others use TensorRT; unified benchmarking (same runtime, same precision, same artifact, identical pre/post-processing) across all baselines is not fully achieved.
- Post-processing inclusions (e.g., NMS for YOLO, mask decoding for segmentation) are not consistently standardized across all compared methods; define and enforce an end-to-end measurement scope.
- Weight-sharing NAS design and search strategy:
- The sampling strategy is uniform over the search space; it is unknown whether importance sampling, progressive shrinking, evolutionary, or RL-based strategies yield better Pareto fronts or faster convergence.
- Sensitivity analyses of the search space boundaries (ranges for patch size, decoder depth, queries, windows, resolutions) are limited; provide full ablations to quantify each knob’s marginal contribution and interactions.
- The paper claims sub-nets not seen during training perform well; quantify this generalization systematically (distribution shift across unseen configurations, distance in configuration space, failure cases).
- Inference-time adaptation policies:
- Decoder-layer truncation and query token dropping are static heuristics; a dynamic, per-image policy (e.g., adaptive early-exit, confidence- and content-aware query budgeting) could improve latency without sacrificing recall—this remains unexplored.
- The ordering criterion for dropping queries (max sigmoid of class logits at encoder output) is not validated across datasets with high object counts or severe class imbalance; analyze recall and miss rates under varying object densities.
- Segmentation head design and mask quality:
- The segmentation head uses single-scale upsampling without multi-scale fusion to minimize latency; quantify the impact on small-object masks (boundary quality, boundary IoU, PQ metrics) and evaluate whether lightweight multi-scale variants can recover accuracy with acceptable latency.
- Loss weighting across decoder layers for segmentation is not detailed; study stability, convergence speed, and performance sensitivity to per-layer loss weights.
- Pre-training with pseudo labels:
- RF-DETR-Seg is pre-trained on O365 with SAM2 pseudo-masks; the effect of pseudo-label noise, domain shift, and class coverage on downstream performance is not ablated. Provide controlled studies on label quality (noise rates, mask boundary fidelity).
- Licensing and reproducibility details for O365 + SAM2 pseudo-labeling pipeline are sparse; release settings (class lists, thresholds, mask refinement) and measure how they affect results.
- Scheduler-free training and augmentation choices:
- The claim that schedulers bias performance is plausible, but the paper lacks a systematic comparison across dataset sizes and optimization horizons (constant LR vs cosine vs step/EMA variants).
- Restricting augmentations (no VerticalFlip, limited to HorizontalFlip and RandomCrop) may underfit in certain domains; propose domain-aware augmentation policies and evaluate across diverse RF100-VL subsets (e.g., aerial, medical, night).
- Positional embeddings and resolution handling:
- Interpolated positional embeddings across resolutions and patch sizes may induce artifacts; measure accuracy and stability at extreme aspect ratios and high/low resolutions, including datasets with unusual image sizes.
- Windowed vs global attention:
- The number of windows per attention block is a search knob, but there is no analysis of how window size and global mixing impact long-range dependencies, small-object detection, and occlusion scenarios. Provide targeted ablations.
- Decoder-free (single-stage) mode:
- The claim that removing the entire decoder yields a single-stage detector is intriguing but not quantitatively evaluated; report accuracy/latency tradeoffs, failure modes, and conditions where decoder-free inference is viable.
- Quantization and export robustness:
- FP16 quantization issues (e.g., D-FINE dropping to 0.5 AP without opset changes) are anecdotal; build and share a generalizable, validated quantization/export recipe (ONNX/TensorRT versions, opset, dynamic shapes) and quantify accuracy drops across models.
- Open-vocabulary capability vs specialist performance:
- RF-DETR is a specialist detector; strategies to retain partial open-vocabulary generalization (e.g., multimodal prompting, distillation from VLMs, hybrid text conditioning) while maintaining real-time performance are not explored.
- Generalization on RF100-VL:
- The RF100-VL results are averaged after per-dataset fine-tuning; zero-shot or few-shot transfer without fine-tuning is not evaluated, nor is the compute cost per dataset (time, GPU-hours) reported.
- Which dataset characteristics (object count, class cardinality, domain) most benefit from specific NAS configurations remains unclear; learn dataset-aware NAS policies or meta-learning for per-dataset specialization.
- End-to-end pipeline considerations:
- Memory footprint, engine build time, and dynamic-shape impacts in TensorRT are not reported; quantify deployment overheads (engine compilation time, RAM/VRAM usage) for practical production scenarios.
- Data I/O, preprocessing/postprocessing overheads, and batch-level resizing effects on throughput/latency are not measured end-to-end.
- Evaluation breadth:
- Robustness to occlusion, crowded scenes, adverse weather/nighttime, and non-RGB modalities (thermal, depth) is not tested; targeted stress tests and cross-modality transfer are needed.
- Additional tasks (panoptic segmentation, keypoints/pose, tracking, video detection) and multi-task extensions are not investigated; assess whether the NAS knobs transfer to these tasks.
- Theory and training dynamics:
- The “architecture augmentation” regularization effect is claimed but not characterized; study its impact on optimization dynamics (loss landscapes, gradient variance), overfitting, and calibration.
- The relationship between dataset size, number of training epochs, and convergence of architecture augmentation is hypothesized (>100 epochs for small datasets) but not empirically substantiated; provide controlled experiments.
- Failure analysis and calibration:
- The paper focuses on mAP; detailed error analysis (false-positive/false-negative breakdowns, calibration curves, per-class performance under imbalance) is missing. Propose methods to calibrate confidence thresholds across domains without NMS.
- Code and implementation specifics:
- Detailed architectural choices (e.g., exact projector architecture, loss terms/weights, normalization placements) for the segmentation head and multi-scale projector are not fully specified; release thorough configuration files and training scripts to ensure exact reproducibility.
Practical Applications
Immediate Applications
Below is a concise set of deployable, real-world use cases that leverage RF-DETR’s findings, methods, and innovations. Each item notes sectors, concrete workflows/products, and key feasibility dependencies.
Industry and Robotics
- Real-time quality inspection on production lines (Sector: robotics/industrial automation)
- Workflow: Fine-tune RF-DETR on plant-specific defects; run weight-sharing NAS post-training to select a sub-net meeting line-speed latency on target hardware (e.g., Jetson, T4); deploy end-to-end DETR (no NMS) for consistent latency.
- Tools/products: “Device-aware model builder” that packages several RF-DETR sub-nets (different decoder depths, query counts, resolutions) for quick A/B testing.
- Dependencies/assumptions: Labeled defect data; TensorRT or equivalent backend availability; closed vocabulary is sufficient; stable thermal conditions close to benchmarking settings.
- Autonomous mobile robots/drones with adaptive perception (Sector: robotics)
- Workflow: Use RF-DETR’s decoder dropout and variable query tokens to dynamically trade accuracy and latency based on power/thermal budget or scene complexity; drop layers/queries when battery low or thermal headroom tight.
- Tools/products: Runtime controller that toggles decoder layers/queries and input resolution on the fly; on-device policy to set target “FPS vs. AP” modes.
- Dependencies/assumptions: Access to runtime telemetry; driver/runtime support for rapid reconfiguration; validation for safety-critical behavior.
Retail and Commerce
- Shelf monitoring and planogram compliance with instance segmentation (Sector: retail)
- Workflow: Train RF-DETR-Seg with store images (optionally pretrain with SAM2 pseudo-masks); run NAS to pick a Pareto-optimal sub-net per camera tier; deploy for restock alerts, misplaced item detection.
- Tools/products: Lightweight segmentation pipeline that converts pixel embeddings to per-object masks in real-time without NMS.
- Dependencies/assumptions: Camera variability across stores; acceptable performance with pseudo-labels; data governance/privacy practices.
- Smart checkout and loss prevention (Sector: retail/point-of-sale)
- Workflow: Closed-vocabulary specialist detector (e.g., known SKUs or categories); RF-DETR replaces NMS-based stacks to reduce post-processing latency spikes; tuned sub-nets for edge devices.
- Tools/products: Pre-packaged “RF-DETR retail models” per latency tier (N/S/M).
- Dependencies/assumptions: SKU/category stability; periodic re-fine-tuning for product churn; lighting domain shifts.
Transportation and Smart Cities
- Traffic analytics and safety monitoring (Sector: transportation/public sector)
- Workflow: Fine-tune on local classes; use query-token scaling to match crowd density (e.g., more queries at stadium exits, fewer off-peak); buffer-based latency benchmarking for procurement and vendor comparisons.
- Tools/products: Model deployment profiles (rush-hour mode vs. off-peak mode); standardized benchmarking reports using the single-artifact tool.
- Dependencies/assumptions: Local dataset availability; alignment with municipal privacy/retention rules; coverage of target classes (closed vocabulary).
Healthcare and Scientific Imaging
- Specialist detectors for domain-specific modalities (Sector: healthcare, life sciences)
- Workflow: Use DINOv2 pretraining + scheduler-free training to reduce hyperparameter burden on small datasets; run weight-sharing NAS to maximize AP within fixed latency budgets on clinical workstations.
- Tools/products: Assisted labeling and pseudo-label bootstrapping (SAM2 for masks), device-calibrated sub-net selector.
- Dependencies/assumptions: Regulatory approval for deployment; data privacy; domain shift from RGB to modality-specific imaging may require additional pretraining.
Software and MLOps
- Fair, reproducible latency benchmarking in model selection (Sector: software/MLOps)
- Workflow: Adopt the paper’s single-artifact benchmark method (same FP precision for accuracy and latency) with 200 ms buffering; report end-to-end latency (including NMS or mask materialization).
- Tools/products: The released benchmarking tool integrated into CI/CD for model releases; procurement-ready benchmarking protocol.
- Dependencies/assumptions: Stakeholder buy-in to standardize metrics; separate throughput testing for full-pipeline performance.
- AutoML/AutoNAS integration for device-specific builds (Sector: software)
- Workflow: Treat NAS knobs (patch size, decoder layers, queries, windows, resolution) as hyperparameters; search post-training without retraining sub-nets; ship a family of sub-nets as a single artifact.
- Tools/products: AutoNAS module exposing accuracy-latency Pareto curves per device.
- Dependencies/assumptions: Validation set for sub-net selection; compute to evaluate many configs; licensing for DINOv2/SAM2.
Academia and Research
- Robust training on small datasets via “architecture augmentation” (Sector: academia)
- Workflow: Use weight-sharing NAS during training as regularization; avoid bespoke schedulers/augmentations that overfit to COCO; evaluate transfer on RF100-VL-like mixtures.
- Tools/products: Teaching labs/libraries that demonstrate generalization without complex schedule tuning.
- Dependencies/assumptions: Acceptance that convergence may require more epochs on very small datasets; reproducible seeds/checkpoints.
Policy and Governance
- Training policy for safety-critical systems (Sector: public policy/compliance)
- Workflow: Codify augmentation constraints (e.g., avoid VerticalFlip for pedestrian detection in ADAS) to prevent bias and spurious detections (reflections).
- Tools/products: Data governance checklist; model cards including augmentation policies and artifact parity (accuracy vs. latency).
- Dependencies/assumptions: Organizational adoption; auditing processes to verify compliance.
Daily Life and Consumer Apps
- On-device camera intelligence with battery-aware modes (Sector: mobile/consumer)
- Workflow: Integrate RF-DETR with switchable modes (battery saver drops decoder layers/reduces queries; high-accuracy increases resolution); use on-device sub-net selection via UI.
- Tools/products: Mobile SDK with dynamic “accuracy vs. speed” slider; home security cameras with adaptive detection fidelity.
- Dependencies/assumptions: Mobile NPU/GPU compatibility; memory constraints; robust export to device runtimes.
Long-Term Applications
The following opportunities are promising but require further research, scaling, or ecosystem development before broad deployment.
Adaptive and Hybrid Perception
- On-device, context-aware architecture adaptation (Sector: robotics/mobile/edge)
- Vision: Continuous selection of sub-nets in response to scene complexity, thermal/battery telemetry, or SLA goals (latency ceilings).
- Potential product: Inference orchestration layer that forecasts load and preemptively adjusts model depth, queries, and resolution.
- Dependencies/assumptions: Stability analysis to guarantee safety; standardized APIs for telemetry and model reconfiguration.
- Hybrid open-vocabulary-to-specialist pipelines (Sector: enterprise/retail/media)
- Vision: Use a VLM for zero-shot discovery, then auto-specialize a closed-vocabulary RF-DETR sub-net via rapid fine-tuning + NAS; deploy the specialist for production real-time use.
- Potential product: “Discover–Specialize–Deploy” toolkit.
- Dependencies/assumptions: Reliable VLM proposals on out-of-distribution classes; balancing generalization vs. specialization; efficient data curation loop.
New Modalities and Tasks
- Multi-modal detectors (thermal, radar, satellite, medical) and domain-shift robustness (Sector: healthcare, defense, energy, geospatial)
- Vision: Extend weight-sharing NAS and DINOv2-style pretraining to non-RGB sensors; leverage architecture augmentation to generalize across modalities.
- Potential product: Cross-modal Pareto-optimized detectors for inspection, aerial monitoring, and diagnostics.
- Dependencies/assumptions: Access to modality-specific pretraining data; adapted backbones; evaluation standards per modality.
- Video detection/tracking and temporal segmentation (Sector: autonomous driving, sports analytics)
- Vision: Incorporate temporal attention while preserving real-time guarantees; NAS across temporal depth and memory length.
- Potential product: Real-time DETR-based MOT/MOTS stack without NMS.
- Dependencies/assumptions: New search knobs, training curricula, and datasets; careful latency budgeting across frames.
Standards, Sustainability, and Governance
- Industry-wide benchmarking standards for latency/accuracy parity (Sector: policy/standards)
- Vision: MLPerf-style track requiring single-artifact parity (accuracy = latency artifact), buffering, inclusion of post-processing costs, and device-agnostic reports.
- Potential product: Certification program for “fair-latency” model reporting.
- Dependencies/assumptions: Cross-vendor agreement; governance body; reproducibility infrastructure.
- Energy-aware NAS and procurement (Sector: sustainability/IT)
- Vision: Extend Pareto optimization to energy per inference (Joules/frame) and carbon footprint; guide hardware selection and fleet management.
- Potential product: Energy-Pareto dashboards for model/hardware co-design.
- Dependencies/assumptions: Reliable energy telemetry APIs; standardized power measurement protocols; multi-objective search tooling.
Privacy-Preserving and Distributed Learning
- Federated architecture selection and specialization (Sector: healthcare/finance/IoT)
- Vision: Share a base model and NAS search policy; sites evaluate sub-nets locally and return performance summaries to choose per-site architectures without sharing data.
- Potential product: Federated NAS controller for per-site “best-fit” sub-nets.
- Dependencies/assumptions: Federated orchestration infrastructure; privacy-preserving metrics; secure aggregation.
Methodological Extensions
- Broader “architecture augmentation” as a robustness principle (Sector: academia/enterprise R&D)
- Vision: Apply architecture variability during training to other domains (NLP, speech) to reduce overfitting to benchmark-specific schedules and augmentations.
- Potential product: Libraries that expose architecture schedules as first-class augmentations.
- Dependencies/assumptions: Empirical validation across tasks; theory on generalization to unseen sub-nets.
Distribution and Ecosystem
- Multi-variant artifacts and edge marketplaces (Sector: software ecosystems)
- Vision: Package a family of sub-nets in a single artifact; app stores/devops systems expose user-selectable or auto-selected modes (ultra-fast vs. high-accuracy).
- Potential product: “Mode-aware” deployment bundles for cameras, kiosks, and mobile apps.
- Dependencies/assumptions: Runtime and packaging standards; monitoring/rollback safety; UX for mode switching.
Glossary
- Anchor boxes: Predefined bounding boxes used in some detectors to propose object regions; DETR removes them in favor of end-to-end set prediction. "In contrast, DETR \citep{carion2020end} removes hand-crafted components like NMS and anchor boxes."
- AP (Average Precision): A precision-recall based metric for object detection; often reported as a single-number summary of detection quality. "To the best of our knowledge, RF-DETR \ (2x-large) is the first real-time detector to surpass 60 AP on COCO."
- Bilinear interpolation: A method to upsample or resample feature maps using linear interpolation in two dimensions. "Notably, the deformable cross-attention layer and segmentation head both bilinearly interpolate the the output of the projector, allowing for consistent spatial organization of features."
- CAEv2: A specific pre-trained vision transformer encoder (from CAE) used as a backbone in prior work. "First, we replace LW-DETR's CAEv2 \citep{zhang2022cae} backbone with DINOv2 \citep{oquab2023dinov2}."
- Cosine schedules: Learning rate schedules that follow a cosine decay, assuming a fixed training horizon. "we observe that cosine schedules assume a known (fixed) optimization horizon, which is impractical for diverse target datasets like those in RF100-VL."
- Deformable cross-attention: An attention mechanism that attends to a sparse set of key locations with learned offsets, improving efficiency and localization. "Notably, the deformable cross-attention layer and segmentation head both bilinearly interpolate the the output of the projector"
- DETR (Detection Transformer): A transformer-based, end-to-end object detector that removes hand-crafted components like anchors and NMS. "In contrast, DETR \citep{carion2020end} removes hand-crafted components like NMS and anchor boxes."
- DINOv2: A strong self-supervised Vision Transformer model used as a pre-trained backbone to improve transfer. "we replace LW-DETR's CAEv2 \citep{zhang2022cae} backbone with DINOv2 \citep{oquab2023dinov2}."
- EMA scheduler: Exponential Moving Average of model parameters maintained during training to stabilize evaluation. "Similar to DINOv3 \citep{simeoni2025dinov3}, we use an EMA scheduler since this is necessary for proper function."
- FFN (Feed-Forward Network): The position-wise multilayer perceptron sub-layer in transformers for feature transformation. "at the output of each decoder layer transformed by a FFN"
- FlexiViT: A training strategy enabling variable patch sizes and resolutions for ViTs to enhance flexibility and transfer. "We adopt a FlexiVIT-style \citep{beyer2023flexivit} transformation to interpolate between patch sizes during training."
- FPN (Feature Pyramid Network): A multi-scale feature aggregation architecture commonly used in detectors. "and FPNs \cite{ghiasi2019fpn}."
- GFLOPs: Giga Floating Point Operations, a measure of computational cost for a model or inference step. "We evaluate efficiency by measuring GFLOPs, number of parameters, and inference latency on an NVIDIA T4 GPU with Tensor-RT 10.4 and CUDA 12.4."
- Grid search: A brute-force hyperparameter or configuration search evaluating all combinations in a predefined set. "We evaluate all model configurations with grid search on a validation set."
- Instance segmentation: The task of detecting objects and predicting a pixel-accurate mask for each instance. "Extending RF-DETR \ for segmentation is also relatively straightforward and only requires adding a lightweight instance segmentation head."
- Internet-scale pre-training: Training on massive web-scale datasets (e.g., image-text pairs) to learn broadly transferable representations. "we present RF-DETR, a scheduler-free approach that leverages internet-scale pre-training to generalize to real-world data distributions."
- Layer normalization: A normalization technique applied across feature channels, often preferred over batch norm for transformers. "we facilitate training on consumer-grade GPUs via gradient accumulation by using layer norm instead of batch norm in the multi-scale projector."
- mAP (mean Average Precision): The mean of AP across IoU thresholds or classes, the primary detection metric on COCO. "We use pycocotools to report standard metrics like mean average precision (mAP)"
- Non-maximum suppression (NMS): A post-processing step that removes overlapping detections to keep only the best ones. "YOLO-based models often omit non-maximal suppression (NMS) when computing latency, leading to unfair comparisons with end-to-end detectors."
- Objects-365: A large-scale object detection dataset used for pre-training to improve downstream performance. "We pre-train RF-DETR-Seg on Objects-365 \citep{objects365} psuedo-labeled with SAM2 \citep{ravi2024sam2} instance masks."
- Open-vocabulary: Models that can detect categories beyond those seen in supervised training by leveraging language or web-scale priors. "Open-vocabulary detectors achieve impressive performance on COCO"
- Out-of-distribution (OOD): Data whose distribution differs from that of the training set, often causing generalization failures. "out-of-distribution classes not typically found in their pre-training"
- Pareto frontier: The set of optimal trade-offs where improving one objective (e.g., latency) would worsen another (e.g., accuracy). "We plot the Pareto accuracy-latency frontier for real-time detectors on the COCO detection val-set"
- Patch size: The spatial resolution of tokens in a ViT; smaller patches yield more tokens and higher compute. "Patch Size. Smaller patches lead to higher accuracy at greater computational cost."
- Positional embeddings: Vectors added to tokens to encode spatial positions for transformers processing images. "We pre-allocate positional embeddings corresponding to the largest image resolution divided by the smallest patch size and interpolate these embeddings for smaller resolutions or larger patch sizes."
- Power throttling: Automatic reduction of GPU power/clock speeds due to thermal or power constraints, impacting latency. "We identify that this lack of reproducibility can be primarily attributed to GPU power throttling during inference."
- Query tokens: Learned embeddings in DETR-like decoders that represent object hypotheses to be decoded into boxes/masks. "Query tokens learn spatial priors for bounding box regression and segmentation."
- RF100-VL (Roboflow100-VL): A benchmark of 100 diverse real-world datasets for evaluating transferability and robustness. "We evaluate our approach on COCO \citep{lin2014coco} and Roboflow100-VL (RF100-VL) \citep{robicheaux2025roboflow100vl}"
- Scheduler-free: Training without bespoke learning rate or augmentation schedules to avoid dataset-specific biases. "we present RF-DETR, a scheduler-free approach"
- Segmentation prototypes: Basis vectors in a prototype-based segmentation head that linearly combine to form instance masks. "we can interpret these pixel embeddings as segmentation prototypes \cite{bolya2019yolact}."
- TensorRT: NVIDIA’s high-performance deep learning inference optimizer and runtime. "inference latency on an NVIDIA T4 GPU with Tensor-RT 10.4 and CUDA 12.4."
- ViT (Vision Transformer): A transformer architecture for images that operates on patch tokens rather than convolutional features. "RF-DETR \ uses a pre-trained ViT backbone to extract multi-scale features of the input image."
- Vision-LLM (VLM): Models trained on image-text data that can align visual content with language semantics. "state-of-the-art vision-LLMs (VLMs) still struggle to generalize to out-of-distribution classes"
- Weight-sharing NAS: A neural architecture search method where many sub-networks share parameters, enabling efficient evaluation of many architectures. "Our weight-sharing NAS evaluates thousands of model configurations with different input image resolutions, patch sizes, window attention blocks, decoder layers, and query tokens."
- Window attention: Attention restricted to local windows in the token grid to reduce computational cost while preserving locality. "Window attention restricts self-attention to only process a fixed number of neighboring tokens."
- Zero-shot performance: The ability to perform a task on novel categories without task-specific supervised training. "Open-vocabulary detectors like GroundingDINO \citep{liu2023grounding} and YOLO-World \citep{Cheng2024YOLOWorld} achieve remarkable zero-shot performance on common categories"
Collections
Sign up for free to add this paper to one or more collections.