- The paper provides a diagnostic analysis showing that mainstream VLMs underperform on spatio-physical reasoning tasks, with proprietary models scoring marginally higher.
- It identifies key error types in visual perception, physical reasoning, and causal reasoning, noting that larger language models tend to improve performance.
- The study demonstrates that a hybrid training approach combining Supervised Fine-Tuning and Reinforcement Learning significantly enhances VLM accuracy on ShapeStacks benchmarks.
Probing Spatio-Physical Reasoning in Vision LLMs
Introduction
The paper "From Diagnosis to Improvement: Probing Spatio-Physical Reasoning in Vision LLMs" (2508.10770) addresses the limitations of current Vision LLMs (VLMs) in performing spatio-physical reasoning. Despite notable advancements in multimodal domains, the capability of VLMs to integrate spatial and physical reasoning remains underexplored. The authors investigate the performance deficits in mainstream VLMs and propose enhancements to bolster their reasoning capabilities using supervised fine-tuning and reinforcement learning.
Diagnostic Analysis of VLMs
The study conducts a thorough diagnostic assessment of VLMs utilizing the ShapeStacks benchmark, which evaluates the ability to reason about the equilibrium of stacked objects. The evaluation of nine mainstream open-source VLMs revealed that none exceeded 0.6 accuracy, with proprietary models achieving marginally better results. A positive correlation is noted between model accuracy and the log size of the LLM component, indicating that scaling up language components correlates with enhanced spatio-physical reasoning performance.
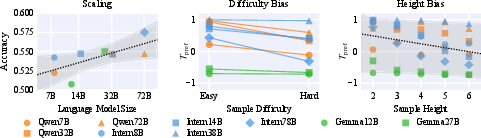
Figure 1: Left: Model accuracy exhibits a positive correlation with the log size of the LLM component. Center: Model bias ($T_{\text{pref}$) shifts towards predicting "False" on hard samples. Right: Models become increasingly biased towards "False" as stack height increases.
Cognitive Biases and Error Types
Through manual examination of Chain-of-Thought (CoT) responses, the paper identifies the key error categories—visual perception, physical reasoning, and causal reasoning errors. Visual perception errors are notably critical, as they propagate downstream logical errors. Additionally, the models displayed human-like cognitive biases, associating greater inter-object displacement and stack height with instability.

Figure 2: Easy and hard samples in the ShapeStacks benchmark. Although both examples shown are in equilibrium, the hard sample exhibits noticeable misalignment between different layers, which can easily lead to misjudgment.
Interface of Cognitive Behaviors
Despite employing advanced cognitive behaviors like verification and backward chaining, the models' reasoning quality remained circumspect. Analysis indicates that high-level cognitive behaviors failed to influence task success, drawing attention to the superficial nature of reasoning in VLMs.
Supervised Fine-Tuning and Reinforcement Learning
The authors refined VLMs using a hybrid training paradigm of Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL), significantly enhancing VLM performance on ShapeStacks. The Qwen2.5-VL-7B model, refined by this methodology, showed a substantial accuracy improvement, surpassing leading proprietary models and confirming the efficacy of the fine-tuning schema in addressing model deficits.

Figure 3: An illustration of the three physics-based generalization tests. Dimensional generalization tests transfer between 2D and 3D data. Height generalization tests transfer between low and high stacks. Dynamics generalization tests transfer from static stability to dynamic scenarios involving external forces (Physion).
Model Generalization
Generalization tests highlight that while VLMs exhibit some capability to generalize across height and dimensional contexts, their ability to adapt to dynamic scenarios remains limited. The study identifies an asymmetry in dimensional generalization: models trained on 3D data generalized more efficiently to 2D contexts than vice-versa.
Conclusion
This paper elucidates crucial limitations in current VLMs concerning spatio-physical reasoning, pinpointing cognitive biases and logical errors as key areas for development. While a combined SFT and RL approach has achieved notable in-domain performance enhancements, significant challenges remain in extending these improvements to novel physical scenarios due to lingering pattern-matching tendencies. Continued research is warranted to develop methods that instill VLMs with robust, generalizable physical reasoning capabilities.