- The paper introduces diffusion models as effective operators for direct code repair via iterative denoising, achieving repair success rates up to 68.1% in Python and Excel.
- It presents a novel method where noisy embedded representations of broken code are realigned in the reverse diffusion process to restore syntactic correctness.
- Synthetic data generation using diffusion models offers diverse training sets that improve repair performance over traditional generative strategies.
Diffusion Models: Operators and Generators for Code Repair
Diffusion models, originally established for continuous domains such as image generation, have shown notable potential in handling discrete tasks, including code generation and repair. The paper "Diffusion is a code repair operator and generator" posits diffusion models as viable tools for code repair, revealing how iterative denoising in diffusion processes can be leveraged for both direct code repairs and synthetic data generation for training repair models.
Diffusion Models in Generative Contexts
Diffusion models operate by constructing a Markov chain with sequential data refinements that introduce Gaussian noise incrementally. This chain can then be reversed to achieve data samples denoised progressively. In discrete areas like text or code, embedding techniques translate the data into continuous spaces, allowing diffusion processes to function effectively. The ability to decode discrete tokens at various diffusion stages is pivotal to the task of code repair, enabling adaptive corrections to incomplete code snippets.
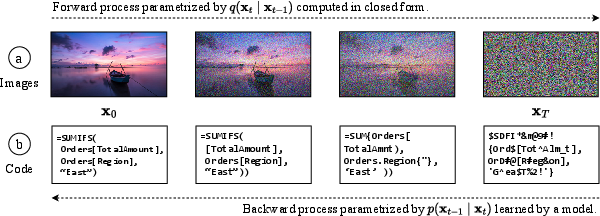
Figure 1: Example of diffusion for code showing how a model progressively denoises an initial noisy latent representation to produce syntactically valid snippets.
Application to Code Repair
This research showcases simple yet potent methods for integrating pre-trained diffusion models into last-mile repair tasks:
Direct Repair through Diffusion
By resuming the reverse diffusion process with noisy embedded representations of broken code, the model can perform repairs by aligning its latent state with functional counterparts. By strategically injecting the broken code into the diffusion chain, the model optimizes minimal changes required to achieve functional code. This technique hinges on a delicate balance of noise levels to ensure effective repairs—a factor further analyzed through experiments showing repair percentages reaching 68.1% for Python and Excel.
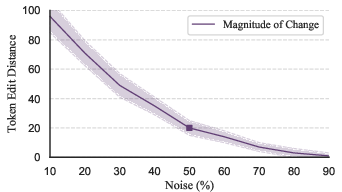
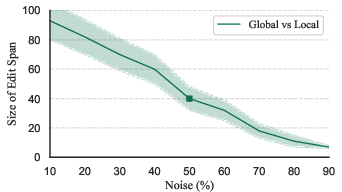
Figure 2: Percentage of tokens changed in each iteration as noise levels vary, influencing repair efficacy.
Synthetic Data Generation
The ability of diffusion models to create high-diversity code snippets presents opportunities to generate expansive datasets. Synthetic data from diffusion processes can enhance models through fine-tuning, allowing them to better handle unseen errors or patterns in live coding environments. Experimentation reveals how diffusion-derived data surpasses other data generation strategies due to its complexity and diversity, supporting fine-tuned models in achieving improved repair rates across various benchmarks.
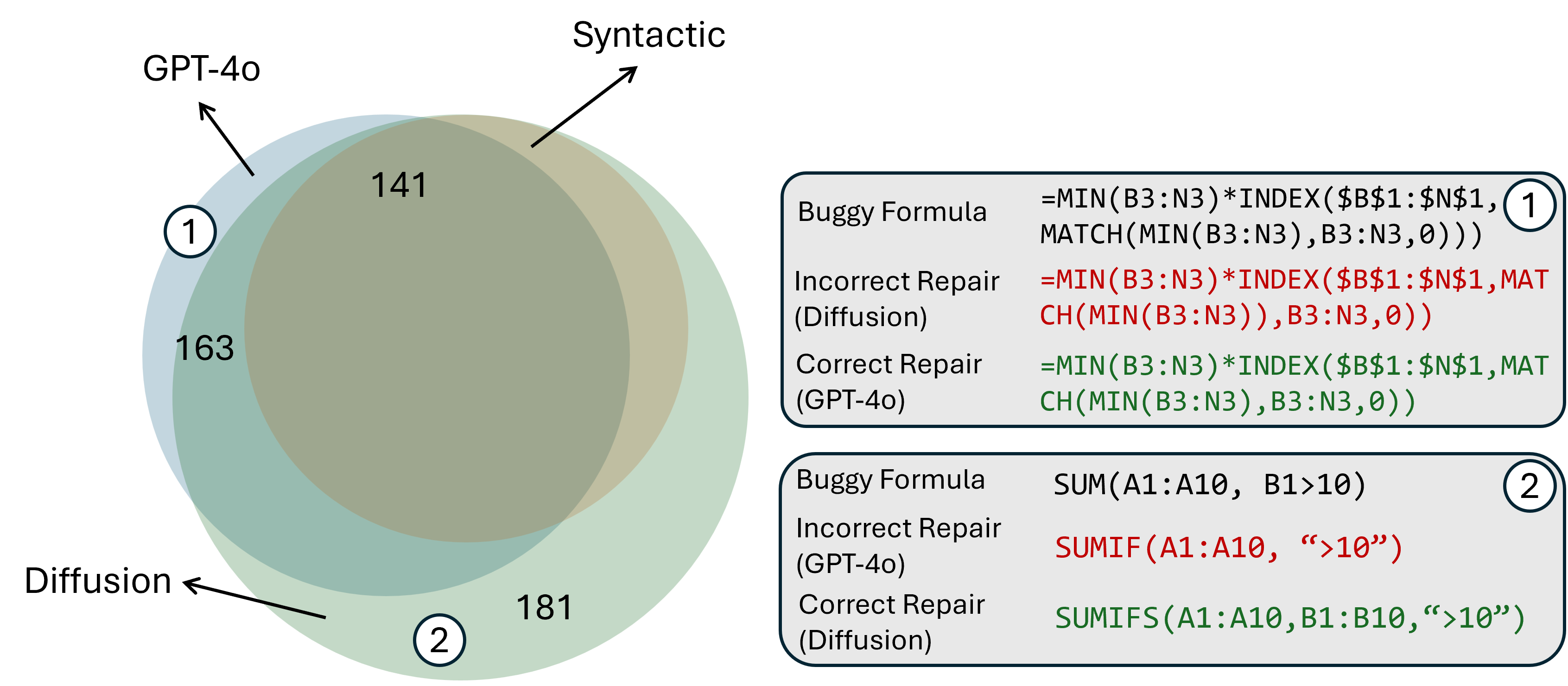
Figure 3: Venn diagram illustrating benchmarks resolved by models trained on datasets from diffusion processes versus other generative methods.
Experimental Results
Extensive evaluations across multiple domains affirm diffusion models as effective operators for code repair. The application of noise varies the performance, reflecting a 21.2% ability to resolve PowerShell errors and broader success in simpler formula-based languages like Excel (Figure 4). The repair model competes closely with fine-tuned and large-scale LLMs, offering comparable or superior benchmarks in execution and sketch match.
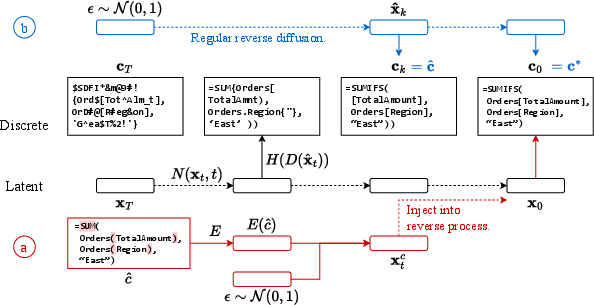
Figure 4: Using a pre-trained diffusion process to facilitate code repair and synthetic training data generation.
Conclusion
This research suggests a promising avenue for employing diffusion models in code repair, particularly as synthetic data generators. While current implementations demonstrate effective repairs and synthetic data capabilities, further advances—particularly involving larger models and more sophisticated noise control mechanisms—could deepen their application in AI-ready coding environments.
Practitioners seeking robust solutions for code repair and data expansion should consider the nuanced advantages of diffusion models as both operators and generators in programming tasks. These methods not only improve syntactic correctness but also facilitate broader data diversity, necessary for modern AI-driven coding paradigms.