- The paper introduces TPLA, which partitions latent representations and attention head dimensions across devices to enhance computational efficiency in tensor-parallel settings.
- TPLA achieves notable speedups (up to 1.93×) by optimizing KV cache distribution during prefill and decode phases while preserving model accuracy.
- The method integrates seamlessly with existing MLA-trained models, enabling scalable inference on memory-constrained devices through efficient distributed attention computations.
TPLA: Tensor Parallel Latent Attention for Efficient Disaggregated Prefill and Decode Inference
Introduction
The paper introduces Tensor Parallel Latent Attention (TPLA), a method designed to optimize the memory and computational efficiency of LLMs during inference, particularly in autoregressive decoding phases. Traditional techniques such as Multi-Head Latent Attention (MLA) and Grouped Latent Attention (GLA) address KV-cache compression and tensor-parallelism, but they fall short under tensor-parallel configurations. TPLA proposes a refined approach that partitions latent representations and attention head dimensions across devices, preserving the compressive benefits of MLA while enhancing throughput efficiency.
Architectures and Methods
Multi-Head Latent Attention: Originally developed in DeepSeek-V2, MLA compresses key-value (KV) states into a low-rank latent vector, requiring fewer memory resources by storing only these vectors. However, in tensor-parallel environments, every device must load the full latent vector, negating MLA's memory benefits.
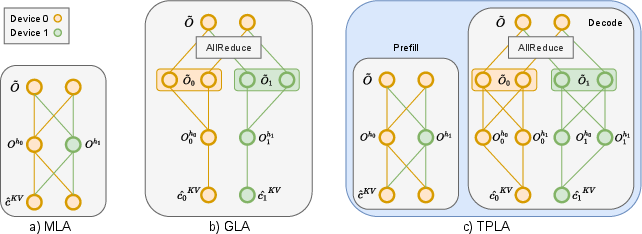
Figure 1: Comparison of MLA, GLA, and TPLA. In MLA, each device must load the entire KV cache. In GLA, each attention head only accesses the portion of the KV cache stored on its own device. In TPLA, the prefilling phase follows MLA for efficiency and accuracy, while during the decoding phase, attention heads are distributed across devices, each relying on the KV cache stored locally on its assigned device.
TPLA Approach: TPLA partitions both the latent representation and input dimensions of each head across devices. Attention computations occur independently for each partition, followed by aggregation through an all-reduce operation. This distribution strategy allows each attention head to still leverage the complete latent representation, maintaining a high representational capacity unlike GLA.
Experiments demonstrate that TPLA achieves significant speedups in context-length scenarios without retraining pre-trained MLA models. For instance, TPLA achieves a 1.79× speedup for DeepSeek-V3 and 1.93× for Kimi-K2 at a 32K-token context length. These results underscore TPLA's ability to reduce per-device KV cache without degrading the overall model performance on commonsense and LongBench benchmarks.
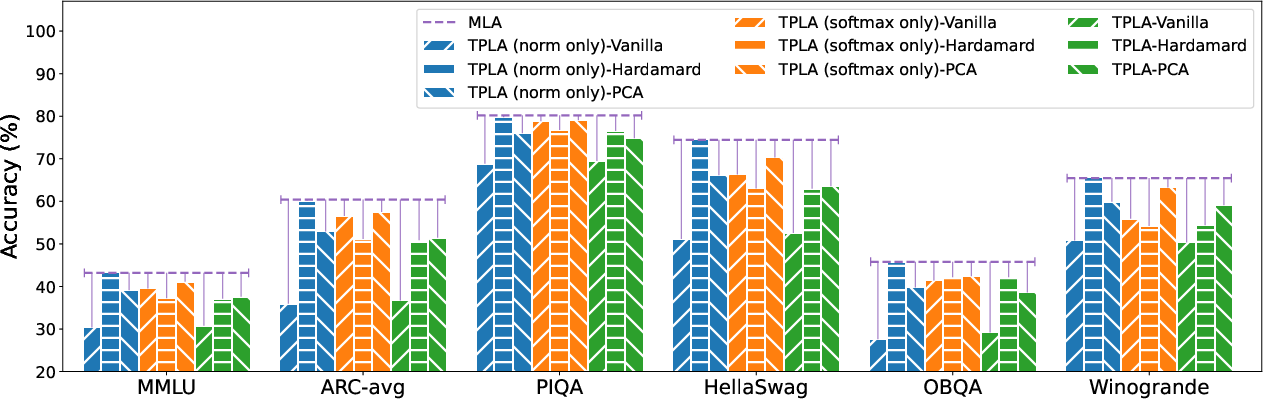
Figure 2: Accuracy across multiple benchmarks under different tensor-parallelism methods (indicated by colors) and reparameterization strategies (indicated by textures). The purple horizontal line marks the original DeepSeek-V2 accuracy.
Practical Applications and Implications
TPLA's ability to adapt existing MLA-trained models without significant performance losses opens new possibilities for deploying LLMs in memory-constrained environments. Applications can leverage FlashAttention-3 for practical end-to-end acceleration. TPLA’s architectural improvements suggest a promising course for future LLM inference processes, especially in scenarios where latencies due to memory bandwidth constraints are a primary concern.
Conclusion
TPLA effectively bridges the memory bandwidth and computational efficiency gap in tensor-parallel LLM inference, retaining high representational capacity without necessitating retraining. Future directions may involve refining TPLA’s integration in diverse LLM architectures and optimizing orthogonal transformations for even greater efficiency. TPLA marks an evolution in handling large-scale models, paving the way for more scalable and efficient AI systems.