Memento: Fine-tuning LLM Agents without Fine-tuning LLMs
Abstract: In this paper, we introduce a novel learning paradigm for Adaptive LLM agents that eliminates the need for fine-tuning the underlying LLMs. Existing approaches are often either rigid, relying on static, handcrafted reflection workflows, or computationally intensive, requiring gradient updates of LLM model parameters. In contrast, our method enables low-cost continual adaptation via memory-based online reinforcement learning. We formalise this as a Memory-augmented Markov Decision Process (M-MDP), equipped with a neural case-selection policy to guide action decisions. Past experiences are stored in an episodic memory, either differentiable or non-parametric. The policy is continually updated based on environmental feedback through a memory rewriting mechanism, whereas policy improvement is achieved through efficient memory reading (retrieval). We instantiate our agent model in the deep research setting, namely \emph{Memento}, which attains top-1 on GAIA validation ($87.88\%$ Pass@$3$) and $79.40\%$ on the test set. It reaches $66.6\%$ F1 and $80.4\%$ PM on the DeepResearcher dataset, outperforming the state-of-the-art training-based method, while case-based memory adds $4.7\%$ to $9.6\%$ absolute points on out-of-distribution tasks. Our approach offers a scalable and efficient pathway for developing generalist LLM agents capable of continuous, real-time learning without gradient updates, advancing machine learning towards open-ended skill acquisition and deep research scenarios. The code is available at https://github.com/Agent-on-the-Fly/Memento.
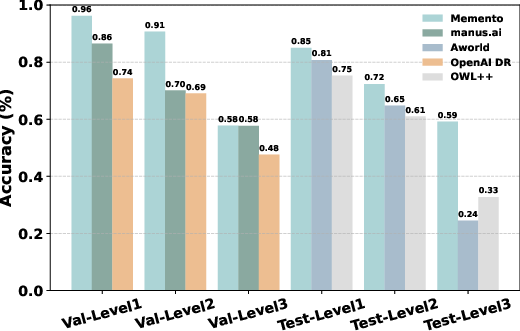
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces Memento, a way to make AI agents (powered by LLMs) get better over time without retraining or changing the AI’s internal brain. Instead of “rewiring” the model, Memento helps the agent learn the way many students do: by keeping a smart notebook of past problems and solutions, and looking up similar cases when facing a new task.
The big questions the paper asks
- How can we build AI agents that keep improving as they work in the real world, without the high cost and delay of retraining big AI models?
- Can an agent learn from its own experiences—both successes and mistakes—by storing and reusing them like a case library?
- Will this memory-first approach work on tough, long tasks that require planning, web browsing, tool use, and combining information from different places?
How the method works, in simple terms
The key idea: Learn from memory, not by retraining
- Traditional methods often “fine-tune” the LLM’s parameters (its internal settings), which is slow, expensive, and risky (it can forget older skills).
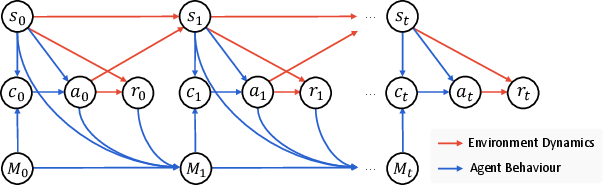
- Memento keeps the LLM frozen. Learning happens outside the model, in a growing memory of past “cases” (problem, plan, outcome).
- When a new problem comes up, the agent searches its memory for similar cases, uses them as examples, and adapts the plan to the new situation.
Think of it like a student’s binder:
- Each past assignment is saved with the question (state), the solution plan (action), and whether it worked (reward).
- For a new assignment, the student flips through the binder to find similar problems and uses them as a guide.
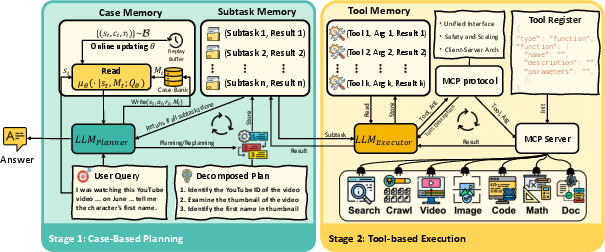
The agent’s two-part design: Planner + Executor
- Planner: Decides what to do next (breaks a big task into subtasks) and consults the memory to find helpful past cases.
- Executor: Carries out each subtask using tools (like web search, code execution, file readers, image/video analysis) through a standard interface (MCP), then reports results back.
They take turns: the planner proposes, the executor tries, the planner reviews, and so on—until the task is done.
The case memory: Write and Read
- Write: After finishing a task, the agent saves a case: what the problem was, what plan it tried, and whether it worked.
- Read: For a new task, the agent fetches the most relevant past cases to guide planning.
There are two ways to Read:
- Non-parametric (simple and fast): Find cases whose problems are textually/semantically similar (like searching by meaning).
- Parametric (smarter ranking): Learn a small scoring function (not the LLM) that predicts which past case will help most now, based on past rewards. This doesn’t retrain the big LLM; it just trains a lightweight scorer to prefer better cases.
How it “learns which memories to trust”
The agent uses a gentle form of reinforcement learning to improve which cases it picks from memory. You can think of it like a music app learning your taste:
- It tries recommending different “songs” (cases),
- Sees if the “song” led to a good result,
- And updates a score so good “songs” are more likely next time. This is done with a method related to “soft Q-learning,” which encourages trying diverse options while still favoring what works.
What the experiments show
The team tested Memento on four kinds of tough benchmarks that need planning, tool use, and real-time web research:
- GAIA: complex, multi-step tasks that often require browsing and multiple tools.
- DeepResearcher: open-domain web research across several QA datasets.
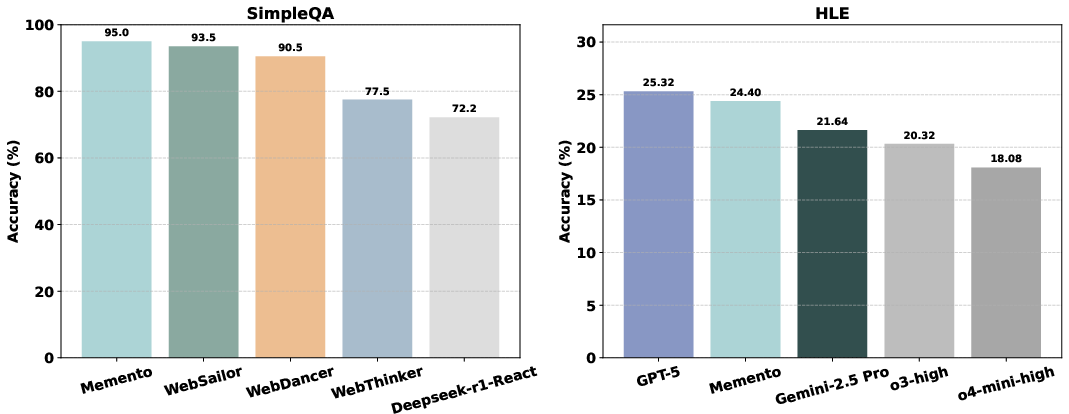
- SimpleQA: concise, factual questions.
- HLE (Humanity’s Last Exam): challenging academic reasoning across many subjects.
Main results (high-level takeaways):
- Top-tier performance on GAIA: Memento ranked at the top of the validation set (about 87.9% Pass@3) and scored 79.4% on the private test set.
- Strong open-web research: On the DeepResearcher suite, Memento reached around 66.6% F1 and 80.4% Partial Match, beating training-heavy systems.
- Very high factual accuracy: About 95% Partial Match on SimpleQA.
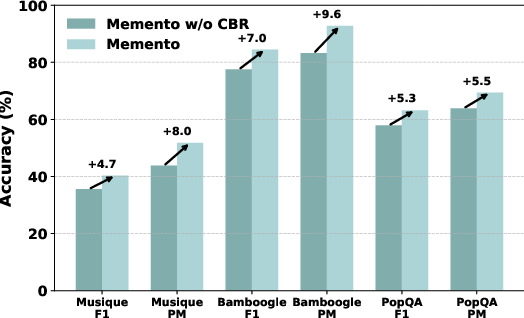
- Better generalization: Adding the case-based memory boosted results by roughly 4.7 to 9.6 percentage points on out-of-distribution tasks (harder, unusual cases).
Why this matters:
- These are long, real-world tasks that need many steps, tool calls, and judgment. Memento shows you can get high performance without retraining the LLM—just by learning how to use memory well.
Why this is important
- Cheaper, faster learning: No need to fine-tune huge models. The agent can improve during use by saving and reusing experiences.
- Human-like strategy: It mirrors how people learn—store examples, recall similar situations, and adapt.
- Safer updates: Because the core model stays fixed, you avoid the risk of “forgetting” old skills or drifting behavior after retraining.
- Scalable and flexible: Works across domains (web research, tools, files, images, videos), and keeps adapting in real time.
- Path to generalist agents: This memory-first design is a practical step toward agents that can keep learning new skills and handle open-ended tasks in the wild.
Key terms made simple
- Case-Based Reasoning (CBR): Solving new problems by recalling and adapting solutions to similar past problems.
- Memory (Case Bank): A growing library of problem–plan–result examples the agent can search.
- Non-parametric vs. Parametric memory:
- Non-parametric: Simple similarity search (like “find the closest match”).
- Parametric: A small learned scorer ranks which cases are likely to help most (no big-model retraining).
- Planner–Executor loop: The planner decides; the executor does; then the planner updates the plan based on results, repeating until done.
In short: Memento shows that giving AI agents a smart, learnable memory can replace expensive retraining, letting them improve on the fly and tackle complex, real-world tasks more like people do.
Collections
Sign up for free to add this paper to one or more collections.