- The paper introduces MemoryBench, a framework that rigorously evaluates memory and continual learning in LLM systems using realistic, feedback-driven user simulations.
- The framework integrates heterogeneous tasks across multiple domains and languages to assess both declarative and procedural memory under varied real-world scenarios.
- Empirical findings reveal that naive retrieval-based approaches can rival advanced memory mechanisms, underscoring the challenges of scalability and effective feedback integration.
MemoryBench: A Benchmark for Memory and Continual Learning in LLM Systems
Motivation and Problem Statement
The MemoryBench framework addresses a critical gap in the evaluation of LLM systems (LLMsys): the lack of comprehensive benchmarks for assessing memory architectures and continual learning capabilities, especially in the context of dynamic user feedback. Existing benchmarks predominantly focus on static, homogeneous reading comprehension tasks with long-form inputs, neglecting the procedural memory and feedback-driven continual learning that are essential for real-world LLMsys deployment. MemoryBench is designed to simulate realistic user interactions and feedback, enabling rigorous evaluation of both declarative and procedural memory utilization across diverse domains, languages, and task formats.
Framework Architecture
MemoryBench comprises three principal modules: Task Provider, User Simulator, and Performance Monitor.
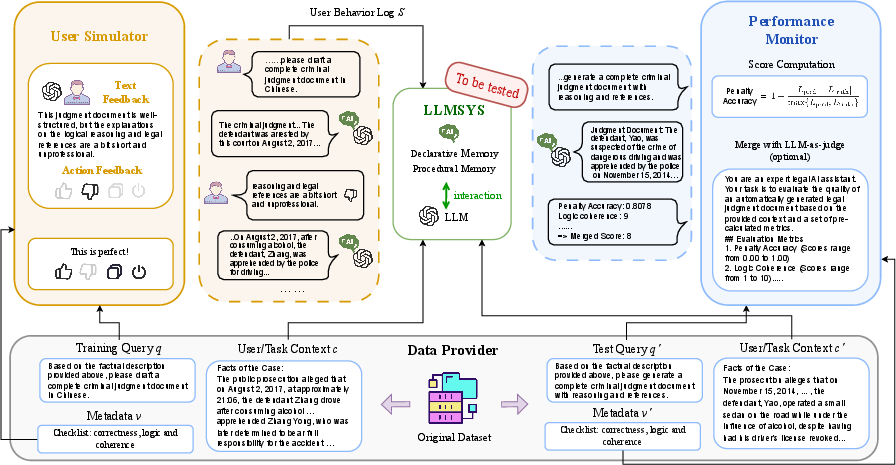
Figure 1: The MemoryBench framework integrates task provisioning, user feedback simulation, and performance monitoring to evaluate LLMsys continual learning.
- Task Provider: Aggregates queries, context, and evaluation metadata for each task case, supporting both training and testing splits. It enables the construction of heterogeneous input/output formats and the integration of domain-specific evaluation criteria.
- User Simulator: Implements a hybrid feedback simulation mechanism, combining LLM-as-user paradigms with programmable action models. It generates both explicit (verbose/action) and implicit feedback, leveraging persona-driven prompting and probabilistic action modeling to mimic realistic user behavior.
- Performance Monitor: Evaluates LLMsys on test data using native and LLM-as-judge metrics, normalizing and aggregating scores across datasets to yield robust performance indicators.
Data Preparation and Task Diversity
MemoryBench integrates 11 public datasets spanning open-domain, legal, and academic contexts, with four task format categories (LiSo, SiLo, LiLo, SiSo) and two languages (English, Chinese). Each dataset is unified into a (q,v,c) tuple, where q is the query, v is evaluation metadata, and c is context. The benchmark supports both short and long input/output formats, enabling evaluation of LLMsys across a spectrum of real-world scenarios.
Feedback Simulation Methodology
The feedback simulation subsystem is a core innovation, supporting both metric-based direct evaluation and LLM-as-user simulation:
- Metric-Based Evaluation: For tasks with objective ground truth (e.g., Locomo, DialSim), feedback is deterministically mapped from F1/accuracy scores to satisfaction levels and user actions.
- LLM-as-User Simulation: For open-ended tasks, a strong LLM is prompted with persona, domain expertise, and evaluation criteria to generate detailed reasoning, behavioral decisions, and natural language responses. Satisfaction scores are assigned via a separate LLM-based module, and user actions (like, dislike, copy) are probabilistically modeled using empirically calibrated sigmoid functions.
Baseline Systems and Experimental Setup
MemoryBench evaluates a spectrum of LLMsys architectures:
- Vanilla: Direct generation without memory augmentation.
- RAG Baselines: BM25 and Qwen3-Embedding-0.6B retrievers, with session/message document granularity.
- Memory Architectures: A-Mem, Mem0, MemoryOS, each with distinct memory management and retrieval strategies.
Experiments are conducted in both off-policy (pre-generated feedback logs) and on-policy (real-time feedback integration) settings, with performance measured via min-max normalization and z-score aggregation across domains and task formats.
Empirical Results and Analysis
Effectiveness of Simulated Feedback
Simulated user feedback demonstrably improves LLMsys performance on most datasets, with feedback-enabled systems outperforming vanilla baselines in both off-policy and on-policy experiments. However, the magnitude of improvement varies by task format and domain, with some cases (e.g., SiLo) showing limited gains or even degradation due to noise in feedback utilization.
Contrary to prior claims, advanced memory-based LLMsys (A-Mem, Mem0, MemoryOS) do not consistently outperform naive RAG baselines. In several domains and task formats, RAG systems achieve comparable or superior results, particularly in handling large-scale, heterogeneous feedback logs. This finding contradicts earlier studies that reported strong performance for memory architectures on homogeneous reading comprehension tasks, highlighting limited generalizability and insufficient procedural memory integration.
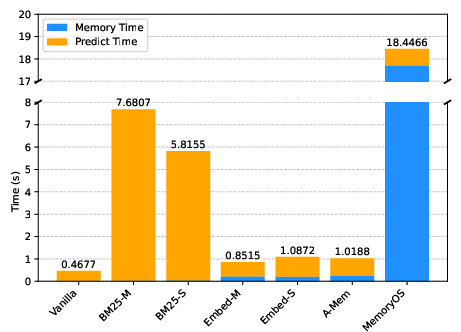
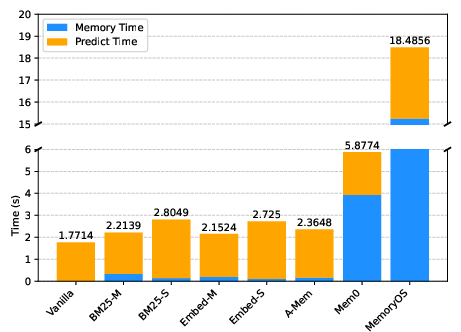
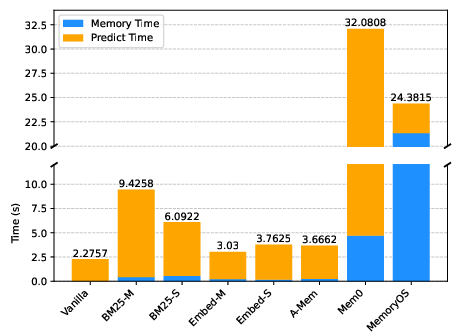
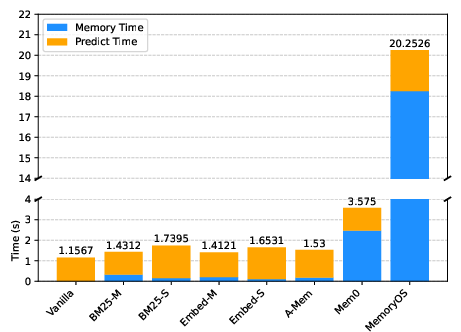
Figure 2: Time consumption per case in LiSo, illustrating significant efficiency disparities among memory architectures.
Efficiency and Scalability
MemoryOS and Mem0 exhibit substantial memory operation latency, with MemoryOS incurring the highest cost and Mem0 suffering from pathological slowdowns on large static knowledge corpora. A-Mem achieves better efficiency but does not surpass RAG baselines in effectiveness. These results underscore the need for scalable, adaptive memory management strategies capable of handling diverse input modalities and feedback types.
Stepwise and On-Policy Learning Dynamics
Stepwise and on-policy experiments reveal fluctuating performance trajectories, especially in academic and legal domains, indicating challenges in filtering and leveraging user feedback for continual learning. The inability of current systems to robustly integrate procedural memory and feedback signals limits their practical utility in dynamic service environments.
Implications and Future Directions
MemoryBench establishes a rigorous foundation for evaluating memory and continual learning in LLMsys, exposing critical limitations in current architectures. The empirical evidence suggests that:
- Procedural Memory Integration: Existing systems lack robust mechanisms for differentiating and utilizing historical feedback logs, leading to noise and inefficiency.
- Scalability: Memory architectures must be redesigned to support efficient storage, retrieval, and adaptation across heterogeneous data and feedback modalities.
- Generalizability: Benchmarks must encompass diverse domains and task formats to ensure that memory and continual learning algorithms are not overfitted to narrow scenarios.
Future research should focus on developing hybrid parametric/non-parametric memory systems, advanced feedback analysis algorithms, and scalable continual learning protocols. The open-sourcing of MemoryBench datasets, scripts, and feedback logs provides a valuable resource for off-policy learning and reproducibility.
Conclusion
MemoryBench represents a significant advancement in benchmarking memory and continual learning for LLMsys. The framework's comprehensive coverage of domains, languages, and feedback types, coupled with rigorous simulation and evaluation protocols, reveals substantial gaps in current memory architectures. The results indicate that naive retrieval-based systems often match or exceed the performance of state-of-the-art memory mechanisms, challenging prevailing assumptions and motivating further research into scalable, adaptive, and feedback-driven continual learning for LLMsys.