- The paper introduces MemoryAgentBench to comprehensively test LLM memory, highlighting accurate retrieval, test-time learning, long-range understanding, and conflict resolution.
- It repurposes existing and novel datasets to simulate multi-turn interactions and evaluate retrieval-augmented generation and external database integration.
- Empirical results reveal limitations in current memory mechanisms, guiding future research towards more robust and dynamic LLM agent memory strategies.
Evaluating Memory in LLM Agents via Incremental Multi-Turn Interactions
Introduction
The paper introduces "MemoryAgentBench," a benchmark designed to assess memory capabilities in LLM agents. Traditional evaluations focus on reasoning, planning, and execution, overlooking memory—specifically memorizing, updating, and retrieving long-term data. The focus here is on memory agents, which leverage memory mechanisms through textual histories or external databases.
The core competencies identified for these memory agents include accurate retrieval, test-time learning, long-range understanding, and conflict resolution. Existing benchmarks fail to evaluate these competencies comprehensively, prompting the introduction of MemoryAgentBench. This new benchmark combines adapted existing datasets with novel datasets to form a robust evaluation testbed.
Memory Agent Competencies

Figure 1: Four complementary competencies that memory agents should have.
The paper identifies these core competencies for memory agents:
- Accurate Retrieval: The ability to extract relevant snippets in response to a query.
- Test-Time Learning: Learning new behaviors or skills during deployment without additional training.
- Long-Range Understanding: Integrating information across extended contexts for global sequence understanding.
- Conflict Resolution: Revising or removing stored information when faced with contradictions, aligning with tasks like model editing and knowledge unlearning.
MemoryAgentBench Description
MemoryAgentBench evaluates memory mechanisms across multi-turn interactions, repurposing existing datasets for traditional long-context tasks into new settings suitable for memory agents. Additionally, new datasets, EventQA and FactConsolidation, assess accurate retrieval and conflict resolution capabilities.
Empirical Evaluation
The study evaluates a diverse set of memory agents ranging from context-based systems to those integrated with external memory modules and tools. Results reveal limitations in current methods, particularly in addressing all core competencies.
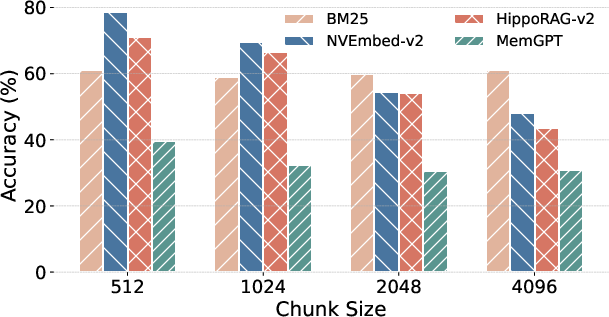
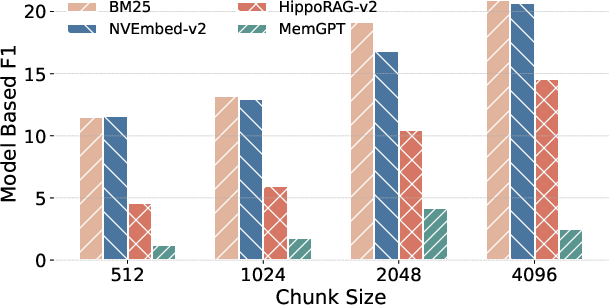
Figure 2: RULER-QA performance.
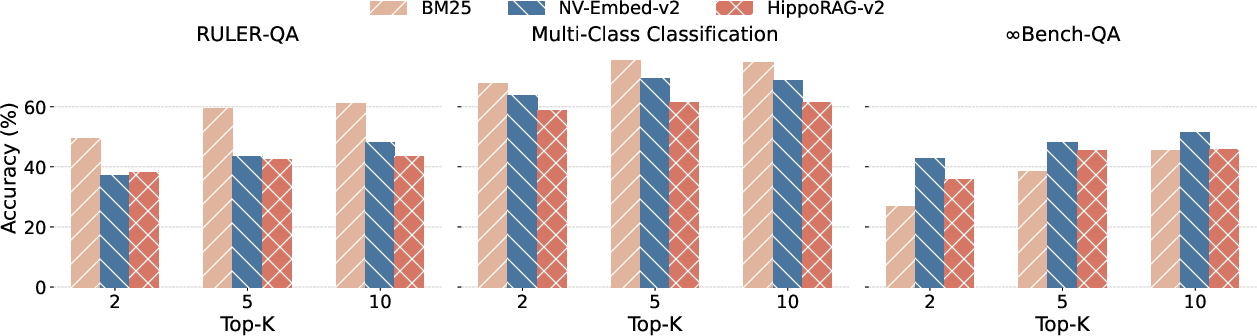
Figure 3: The accuracies on different benchmarks when varying the retrieval top-k to be 2, 5 and 10.
Implementation and Use Cases
Here are the components involved in implementing memory mechanisms in LLMs:
- Textual History Storage: Leveraging existing transformers to store conversation histories and update them based on user interactions.
- External Database Integration: Utilizing databases to extend memory beyond immediate conversational context, enhancing retrieval capabilities through structured data.
- Retrieval-Augmented Generation (RAG): Employing RAG techniques to dynamically retrieve relevant data from long-term memory, facilitating accurate recall even in extended dialogues.
- Agentic Memory Agents: Introducing decision-driven frameworks where agents iteratively refine data retrieval and reasoning through feedback loops.
Despite their potential, current solutions like MemGPT and similar commercial products remain constrained by retrieval accuracy and integration of long-range context. They often fall short in dynamically evolving their memory in response to new information.
Conclusion
MemoryAgentBench fills a crucial gap in evaluating LLM memory capabilities by addressing incrementally accumulated information beyond static context use. While it highlights the advances in memory agent technologies, it also underscores challenges such as integrating comprehensive memory mechanisms and fine-tuning multi-turn interaction models. Future work should expand on realistic datasets that mirror natural conversations to enhance the applicability of memory benchmarks in practical scenarios.
Incorporating these improvements will facilitate in-depth understanding and development of robust memory agents capable of handling diverse, real-world tasks with higher efficacy.