- The paper finds that mixed memory structures yield balanced performance and noise resilience across diverse datasets.
- The paper demonstrates that iterative retrieval refines query context to significantly improve Exact Match and F1 scores.
- The paper compares Memory-Only and Memory-Doc approaches, highlighting their suitability for precision versus context-rich tasks.
On the Structural Memory of LLM Agents
LLMs have positioned themselves at the forefront of natural language processing tasks, largely due to their advanced capabilities in handling complex interactions such as QA and dialogue systems. This paper explores the crucial role of memory modules within LLM-based agents, specifically investigating the influence of various memory structures and retrieval methods on agent performance across different tasks and datasets.
Memory Structures and Retrieval Methods
The study introduces four memory structures: chunks, knowledge triples, atomic facts, and summaries, as well as a mixed memory approach combining these elements. It further evaluates three retrieval methods: single-step retrieval, reranking, and iterative retrieval. The detailed analysis seeks to understand how these different components impact the agents' capability to perform across tasks such as multi-hop and single-hop QA, dialogue understanding, and reading comprehension.
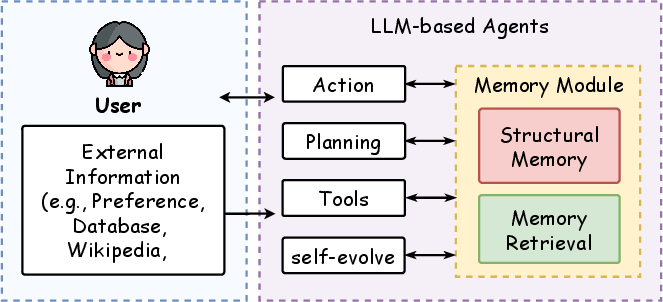
Figure 1: The framework of LLM-based agents, focusing on the study of memory modules, including memory structures and retrieval methods.
Implementation Methodology
The core focus lies in structuring memory effectively and retrieving it for advanced reasoning tasks. Structural memories organize raw document data into organized forms, while retrieval methods aim to efficiently identify and integrate relevant memories with incoming queries. The paper evaluates these methods across six datasets, aligned with varied QA tasks, illustrating their influence on performance metrics like Exact Match (EM) scores and F1 scores.
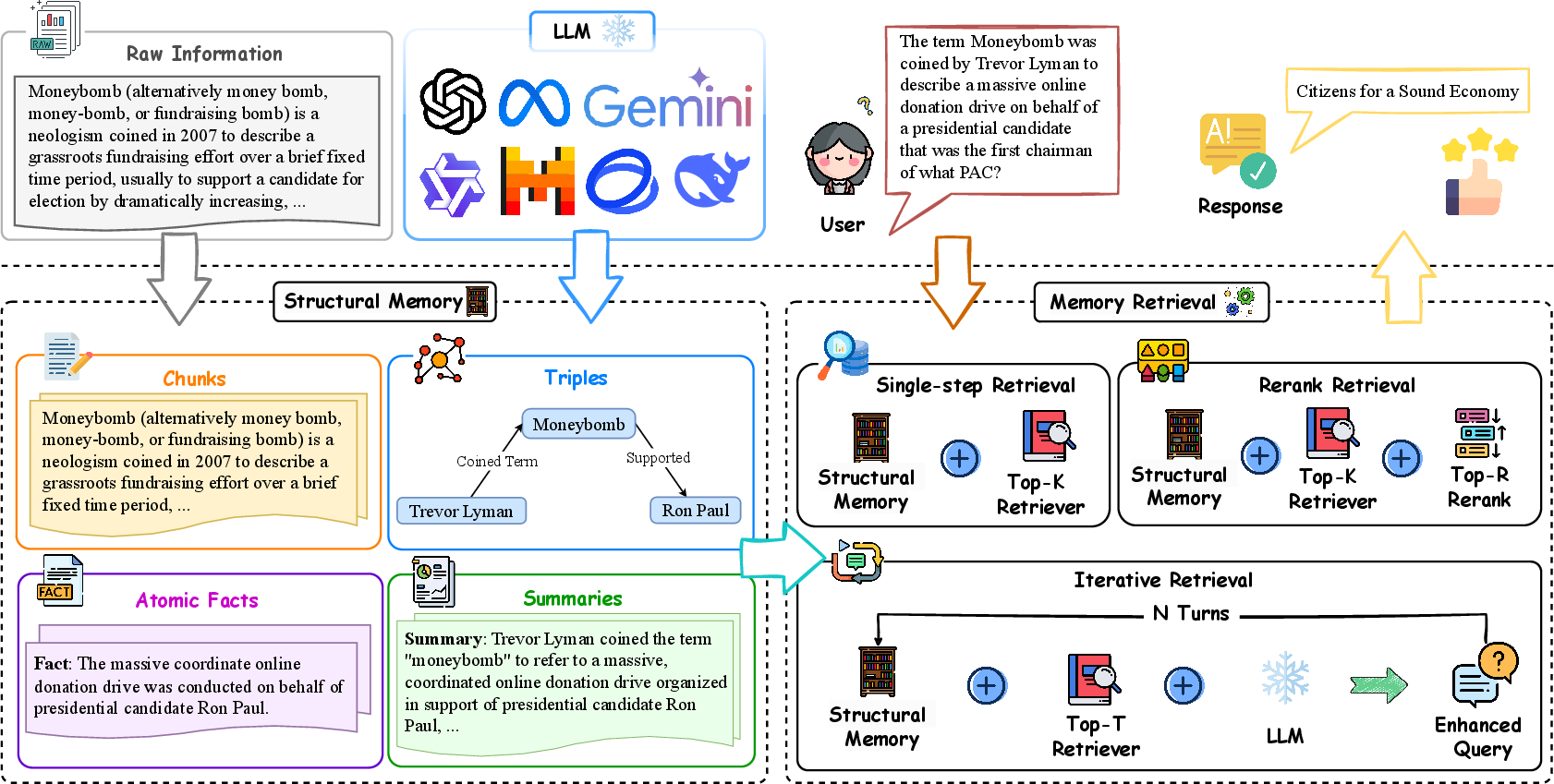
Figure 2: Overview of the memory module workflow in LLM-based agents. Raw information is organized into structural memories, processed through retrieval methods to generate precise and contextually enriched responses.
Experimental Findings
Memory Structure Impact
The research reveals that different memory types serve distinct advantages. Mixed memory structures exhibit balanced performance and noise resilience. Notably, chunks and summaries are well-suited for tasks with lengthy contexts, such as reading comprehension, while knowledge triples and atomic facts are effective in tasks requiring relational understanding and precise reasoning, like multi-hop QA.
Memory Retrieval Methods
Iterative retrieval emerges as the superior method across multiple scenarios, demonstrating robust performance improvements by refining queries for higher accuracy in memory retrieval. This method consistently outperforms single-step retrieval and reranking by adapting query refinements to dynamically include crucial context.
Answer Generation Approaches
Evaluation of Memory-Only versus Memory-Doc approaches in answer generation highlights that tasks dependent on extensive context benefit from Memory-Doc, while precision-oriented tasks favor Memory-Only approaches. This differentiation underscores the necessity of chosen method alignment with task objectives for optimal performance.
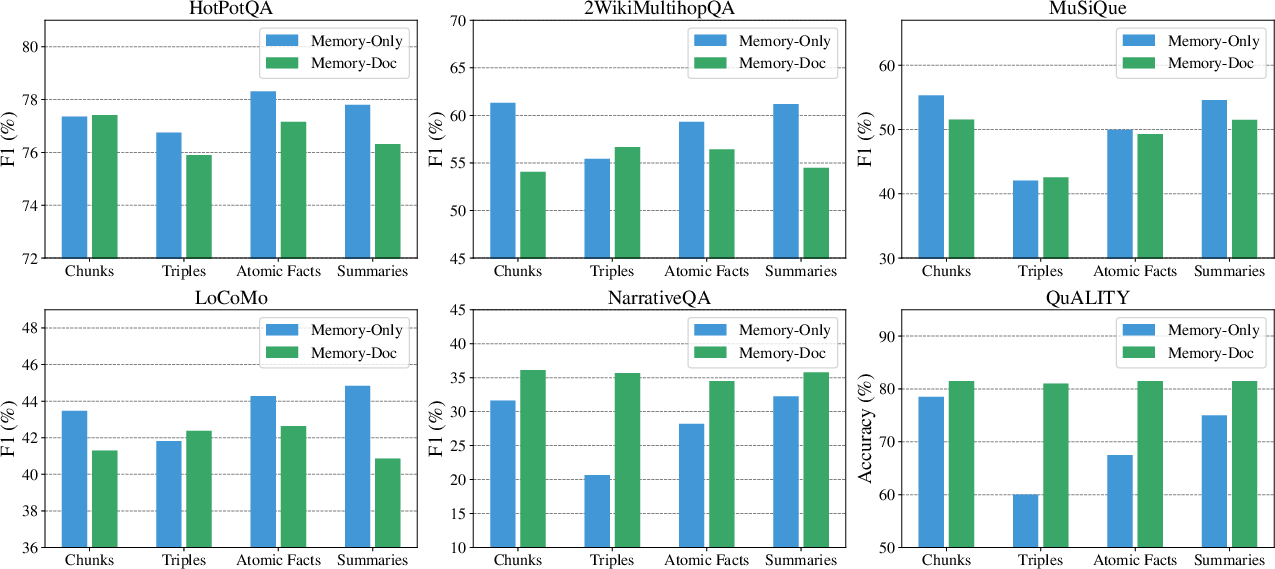
Figure 3: Performance across six datasets using two answer generation approaches: Memory-Only and Memory-Doc.
Hyperparameter Sensitivity and Noise Robustness
The study also examines the retrieval hyperparameter sensitivity, where moderate values often yield optimal performance, preventing noise-induced degradation. Additionally, mixed memories consistently showcase robustness against increased noise levels, maintaining superior retrieval accuracy.
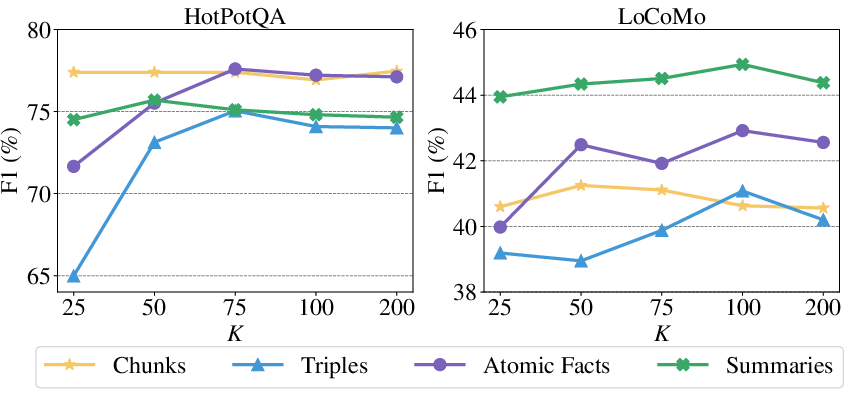
Figure 4: Performance of different numbers of retrieved memories K on HotPotQA and LoCoMo using single-step retrieval.
Conclusion
This paper provides an in-depth examination of memory structures and retrieval methods in LLM-based agents, emphasizing their critical impact on agent performance across diverse tasks. The insights support strategic selection and combination of memory types and retrieval techniques to enhance task-specific outcomes. Future explorations may consider expanding this work to investigate memory mechanisms in self-evolving agents and simulate social behaviors, further broadening the applicability and robustness of LLM applications.