- The paper introduces a novel Factual Robustness Score (FRS) combining entropy and temperature scaling to evaluate the stability of LLM factual knowledge.
- Experimental results reveal that larger models achieve higher FRS scores (up to 0.93) and suffer less accuracy degradation under increased uncertainty.
- Findings indicate that while numerical facts remain robust, queries involving names show significant accuracy loss, emphasizing model sensitivity.
From Confidence to Collapse in LLM Factual Robustness
Introduction
The reliability and stability of factual knowledge embedded in LLMs remain critical challenges for applications in fields such as question answering and reasoning. Traditional evaluation methods primarily focus on performance-based metrics under fixed conditions, often overlooking internal factors like entropy and temperature, which significantly affect factual robustness. The paper "From Confidence to Collapse in LLM Factual Robustness" addresses this gap by introducing the Factual Robustness Score (FRS), a novel metric designed to quantify the resilience of factual knowledge against perturbations in generation conditions.
Factual Robustness Score (FRS)
The FRS emerges from the combination of entropy and temperature scaling sensitivity to evaluate robustness. Entropy measures the internal uncertainty of token distributions during fact generation, while temperature scaling influences the probability distribution's diversity. By analyzing these dimensions, FRS provides a comprehensive assessment of how robustly factual knowledge is embedded within LLMs, going beyond superficial accuracy metrics to capture inherent stability in knowledge retention.
The metric integrates initial entropy and the breaking temperature, which denotes the threshold where increased temperature results in incorrect answers. This approach offers deeper insights into the model's ability to maintain factual accuracy under varying uncertainty levels.
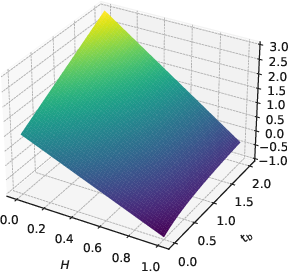
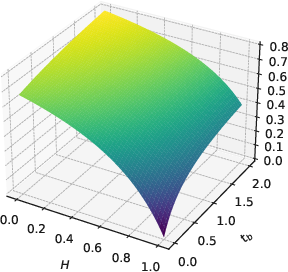
Figure 1: 3D plot of f(H,1,tb) and f01(H,1,tb) over H∈[0,1] and tb∈[0,2], visualizing the FRS.
Experimental Findings
Extensive experiments conducted on five different LLMs across three closed-book question answering datasets—SQuAD, TriviaQA, and HotpotQA—reveal significant variances in factual robustness. Smaller models typically exhibit a FRS of 0.76, while larger ones score around 0.93, underscoring the impact of model size and architecture on robustness. Accuracy degradation by approximately 60% under increased uncertainty highlights the sensitive role of temperature in factual retention, with entropy providing additional metrics on intrinsic model confidence.
The correlation between model size, factual robustness, and the nature of knowledge types is particularly revealing. Numerical and location-based factual queries tend to demonstrate higher robustness compared to those involving names or entities. This trend provides nuanced understanding of how probabilistic token selection influences factual robustness across different knowledge domains.
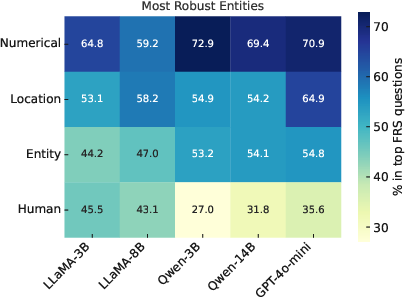
Figure 2: Numerical facts are most robust across all models, while questions about names lead to least robust answers.
Temperature's Impact on Token Distribution
The impact of temperature t on token probability distribution is clearly demonstrated. As temperature increases, the flattened distribution results in lower certainty and increases the likelihood of selecting less probable tokens. This dynamic interaction underscores the need to factor temperature variability into evaluations of factual robustness.
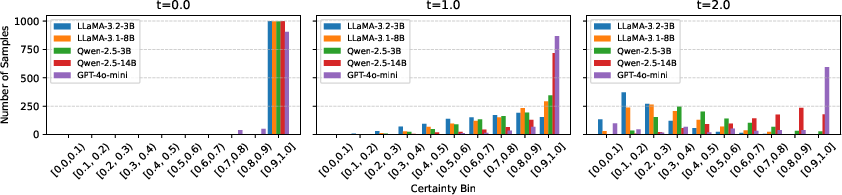
Figure 3: Impact of temperature t on token probability distribution in TriviaQA.
Challenges and Implications
While model size plays a crucial role in factual robustness, architectural variations and training methodologies significantly affect knowledge stability. This variability suggests that advancements in model design and training protocols could dramatically enhance factual retention. Future research should focus on methods to improve entropy metrics and refine FRS calculations under varied conditions, such as higher temperatures beyond the scope of current evaluations.
Practically, the FRS could inform the development of enhanced pre-training methodologies targeting specific weaknesses identified in models, thereby iterating models towards more resilient factual retention capabilities.
Conclusion
This paper introduces a critical shift in evaluating LLMs by considering both accuracy and robustness through the lens of FRS. The insights derived from analyzing entropy and temperature effects on factual knowledge retention serve as a foundation for future explorations in model development, aiming at supreme factual consistency across diverse applications. As LLMs continue to expand their influence in AI-driven tasks, ensuring factual robustness will remain an imperative focus for researchers seeking to deepen model reliability and accuracy.
