- The paper presents a unified framework combining spherical vision transformers with audio-visual fusion for saliency prediction in 360° videos.
- It introduces the YT360-EyeTracking dataset and employs a novel VSTA mechanism along with gnomonic projection to address spatial distortions.
- Empirical results show that integrating spatial audio improves prediction accuracy while maintaining efficient model scalability with minimal extra parameters.
Introduction and Motivation
The paper addresses the challenge of predicting visual saliency in omnidirectional (360∘) videos, a critical task for VR and immersive media applications. Unlike conventional 2D video, ODVs introduce severe spatial distortions due to their spherical geometry and require models to account for both visual and auditory cues, especially spatial audio, which strongly modulates human attention in immersive environments. The authors identify the lack of comprehensive datasets and models that jointly consider these modalities and propose a unified framework for audio-visual saliency prediction in 360∘ videos.

Figure 1: Audio-visual saliency in 360∘ videos, illustrating how spatial audio cues direct attention to salient regions such as a passing car and birds, motivating multimodal integration.
YT360-EyeTracking Dataset
A major contribution is the YT360-EyeTracking dataset, comprising 81 high-resolution ODV clips sampled from YouTube-360, annotated with eye-tracking data from 102 participants under three audio conditions (mute, mono, ambisonics) and two color conditions (colored, grayscale). The dataset is balanced across semantic categories (speech, music, vehicle) and scene types (indoors, outdoors-natural, outdoors-human-made), enabling systematic analysis of cross-modal attention mechanisms.

Figure 2: Sample input frames from YT360-EyeTracking, covering diverse audio and visual categories.
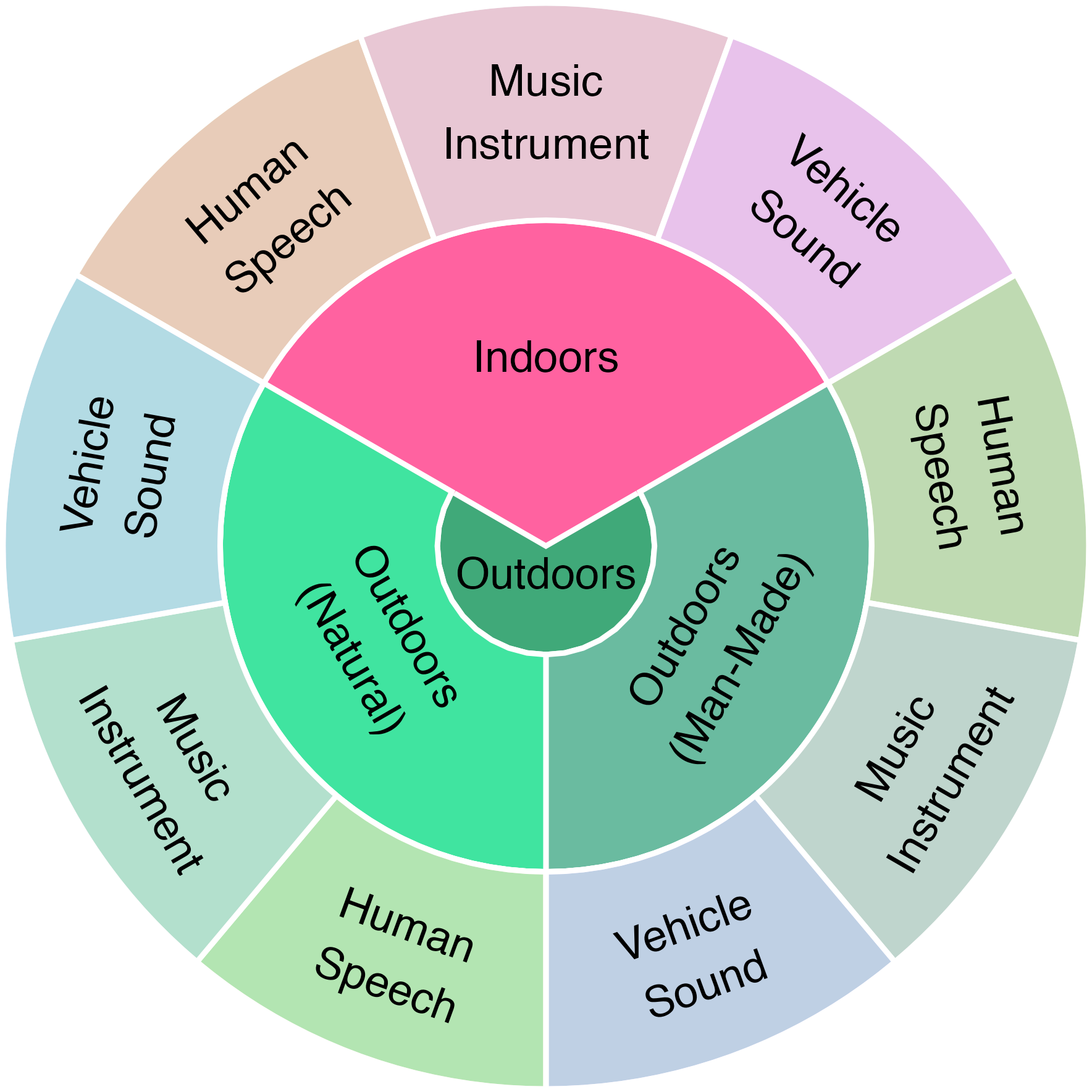
Figure 3: Distribution of observation sessions by category and format, showing robust participant coverage per clip.
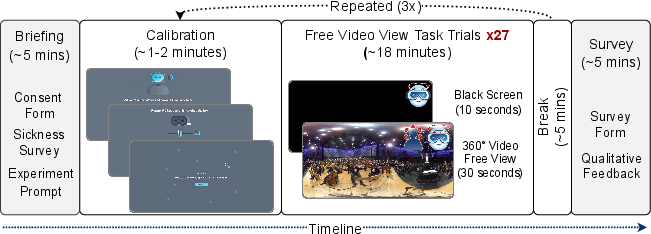
Figure 4: Data collection protocol, detailing session structure, calibration, and randomized stimulus presentation.
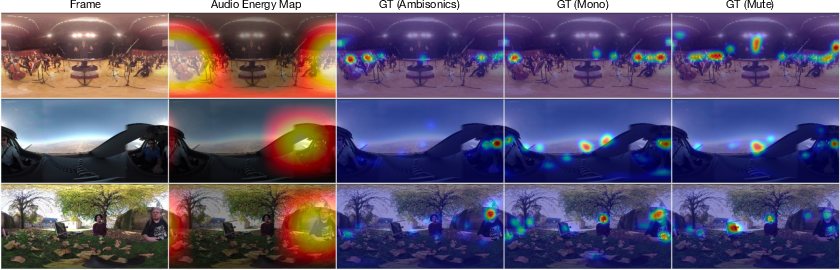
Figure 5: Fixation density maps under mute, mono, and ambisonic audio, demonstrating the progressive influence of spatial audio on attention alignment.
SalViT360 is a vision transformer-based model tailored for ODV saliency prediction. The pipeline projects ERP frames to locally undistorted tangent images via gnomonic projection, encodes each viewport with a CNN, and fuses features with spherical geometry-aware position embeddings. The core innovation is the Viewport Spatio-Temporal Attention (VSTA) mechanism, which aggregates information across both spatial and temporal dimensions, enabling the model to reason globally while maintaining local distortion-aware representations.
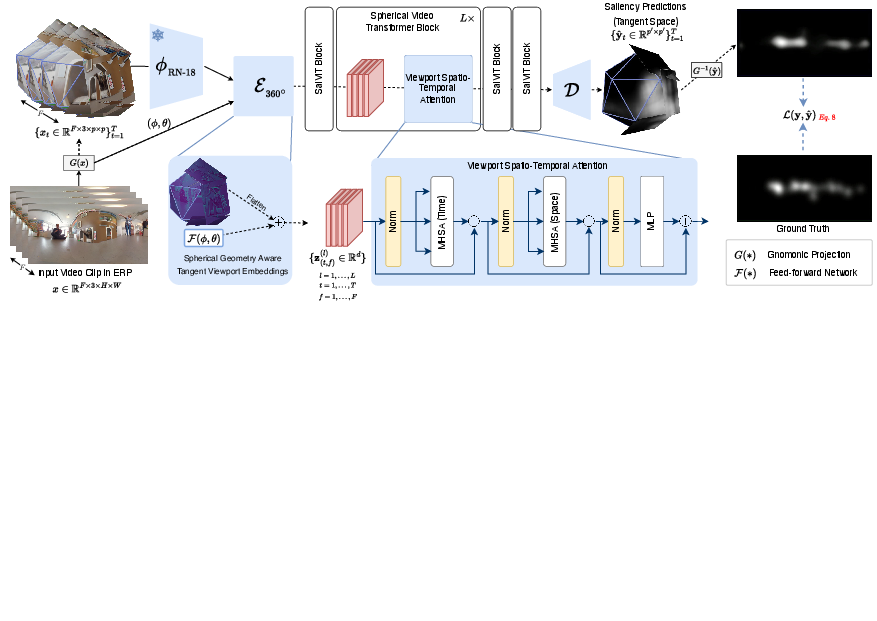
Figure 6: SalViT360 architecture overview, showing tangent image projection, encoding, spherical position embedding, VSTA aggregation, and ERP saliency map reconstruction.

Figure 7: VSTA mechanism, contrasting spatial-only, joint spatio-temporal, and the proposed two-stage attention scheme.
The model is trained with a supervised loss combining KLD, CC, and selective MSE, and an unsupervised Viewport Augmentation Consistency (VAC) loss to enforce consistency across tangent projections. Ablation studies confirm that spherical position embeddings, VSTA, and VAC masking each contribute to improved performance.
SalViT360-AV: Audio-Visual Adapter Integration
SalViT360-AV extends SalViT360 by incorporating spatial audio via transformer adapters. The audio stream processes first-order ambisonics, rotating and decoding them per tangent viewport to generate mono directional waveforms aligned with the viewer's gaze. Features are extracted using a pre-trained audio backbone (PaSST, EZ-VSL, or AVSA), and concatenated with visual tokens at each transformer block. Audio-Visual MLP Adapters fuse modalities in a parameter-efficient manner, enabling fine-grained cross-modal interaction without retraining the visual backbone.
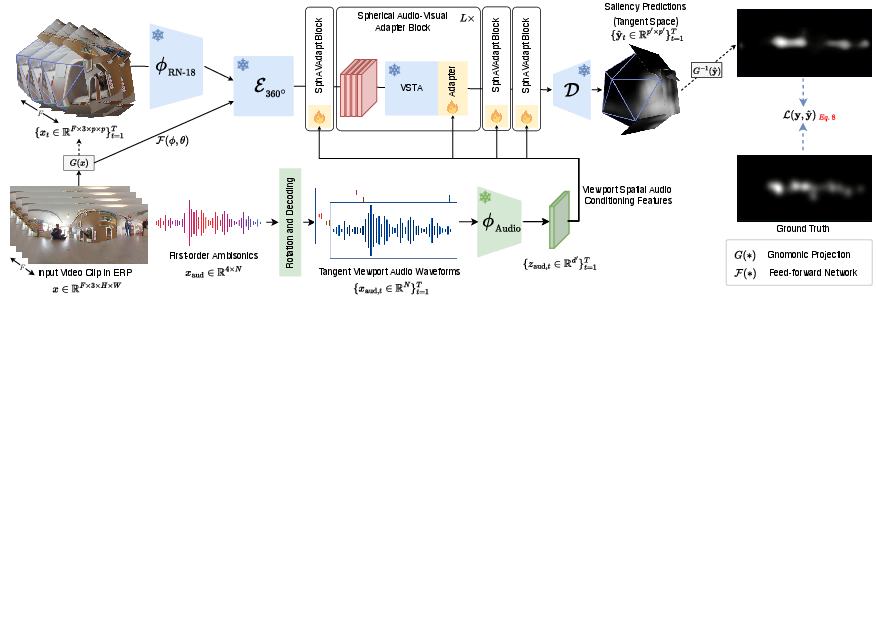
Figure 8: SalViT360-AV pipeline, showing integration of spatial audio encoding and adapter-based fusion with the visual transformer.
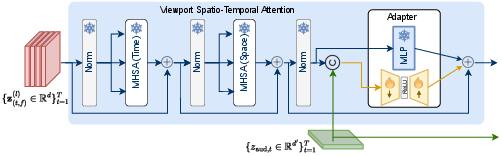
Figure 9: Audio-visual adapter fine-tuning, illustrating token concatenation and bottleneck fusion at each transformer block.
Empirical Evaluation
The models are evaluated on four benchmarks: VR-EyeTracking, PVS-HMEM, 360AV-HM, and the new YT360-EyeTracking. SalViT360 achieves state-of-the-art results in visual-only settings, outperforming prior CNN and transformer-based approaches. SalViT360-AV further improves accuracy in audio-visual contexts, consistently surpassing both 2D and 360∘ baselines, especially in scenarios where spatial audio cues dominate attention.
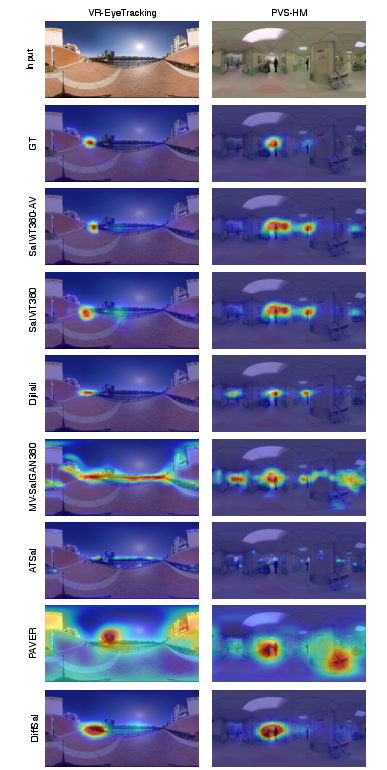
Figure 10: Qualitative comparison of predicted saliency maps, showing SalViT360(-AV) accurately localizing human gaze in complex scenes.
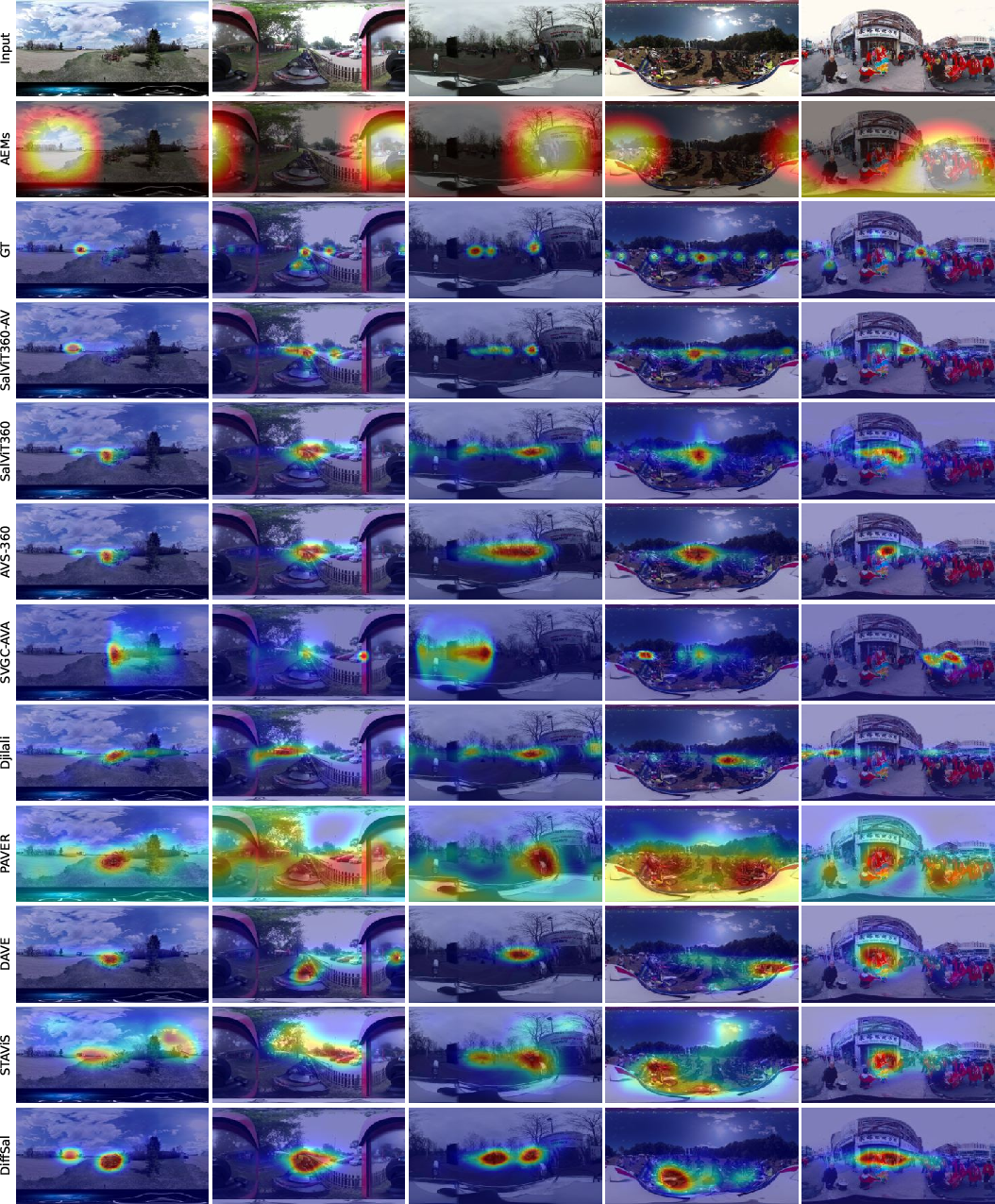
Figure 11: SalViT360-AV predictions on YT360-EyeTracking, demonstrating precise alignment with audio-driven salient events.
Figure 12: Cross-dataset generalization on 360AV-HM, AVS-ODV, and SVGC-AVA, with SalViT360-AV robustly localizing audio-influenced salient regions.
Ablation studies reveal that VSTA outperforms 2+1D CNN and offline aggregation strategies, and that VAC loss with masking yields the best consistency. The effect of audio modality is quantified: saliency prediction accuracy increases with richer audio conditions, even for models trained without audio, underscoring the importance of spatial audio in guiding collective attention.
Implementation and Deployment Considerations
The architecture is designed for scalability and efficient training. SalViT360 uses 25.56M parameters, while SalViT360-AV adds only 600k parameters via adapters. Training is performed on a single Tesla V100 GPU with 32GB memory, using AdamW and a cosine learning rate schedule. The pipeline supports flexible audio backbones and can operate in visual-only mode without retraining. The use of tangent images and spherical embeddings enables transfer learning from large-scale 2D models, while the adapter strategy allows rapid fine-tuning for new audio modalities.
Implications and Future Directions
The integration of spatial audio into transformer-based saliency prediction sets a new standard for multimodal modeling in immersive media. The dataset and models facilitate downstream tasks such as perceptual video quality assessment, foveated rendering, and adaptive streaming. The findings highlight the necessity of geometry-aware and cross-modal fusion for accurate attention modeling in VR. Future work may explore higher-order ambisonics, real-time deployment, and extension to other multimodal tasks such as navigation path generation and semantic scene understanding.
Conclusion
The paper presents a comprehensive solution for audio-visual saliency prediction in 360∘ videos, combining a novel dataset, spherical transformer architecture, and parameter-efficient audio-visual adapters. The empirical results demonstrate robust generalization and strong alignment with human attention, particularly in the presence of spatial audio. The approach provides a foundation for further research in multimodal perception and immersive media systems.