- The paper introduces a MoE gating network that dynamically weights three surrogate models to enhance aerodynamic predictions.
- The methodology integrates DoMINO, X-MeshGraphNet, and FigConvNet, with adaptive spatial weighting and entropy regularization to prevent expert collapse.
- Experiments on the DrivAerML dataset show a significant reduction in L-2 prediction errors, validating the effectiveness of this composite modeling approach.
Mixture of Experts Gating Network for Enhanced Surrogate Modeling in External Aerodynamics
This essay provides a detailed examination of the paper titled "A Mixture of Experts Gating Network for Enhanced Surrogate Modeling in External Aerodynamics" (2508.21249). It explores the innovative use of Mixture of Experts (MoE) architecture to improve surrogate modeling in automotive aerodynamics and discusses the methodological advancements, experimental validations, and implications for future AI-based modeling strategies.
Introduction and Context
The paper addresses the significant computational expense involved in high-fidelity CFD simulations required for automotive aerodynamics, presenting a novel MoE framework as a solution. The challenge in this domain arises from the necessity of accurately capturing complex, multi-scale turbulent phenomena, which traditional CFD methods achieve at considerable time and resource costs. Surrogate models offer a potential reduction in this computational burden but lack universal performance due to varying model biases and architecture-specific strengths.
The MoE model proposed herein leverages these architectural diversities, combining three distinct surrogate models: DoMINO, X-MeshGraphNet, and FigConvNet. Each model reflects different inductive biases suited for specific aerodynamics facets, such as handling geometric intricacies, capturing global flow dynamics, or efficiently extracting features from grid-based inputs.
Methodology and Proposed Framework
The MoE framework encompasses a gating network that dynamically optimizes the combination of expert predictions based on localized performance in predicting pressure and wall shear stress fields. The gating network assigns spatially-variant weights to the predictions from the three heterogeneous surrogate models. This weighting strategy is aimed at exploiting the complementary strengths of specialized architectures and is complemented by entropy regularization to avoid expert collapse.
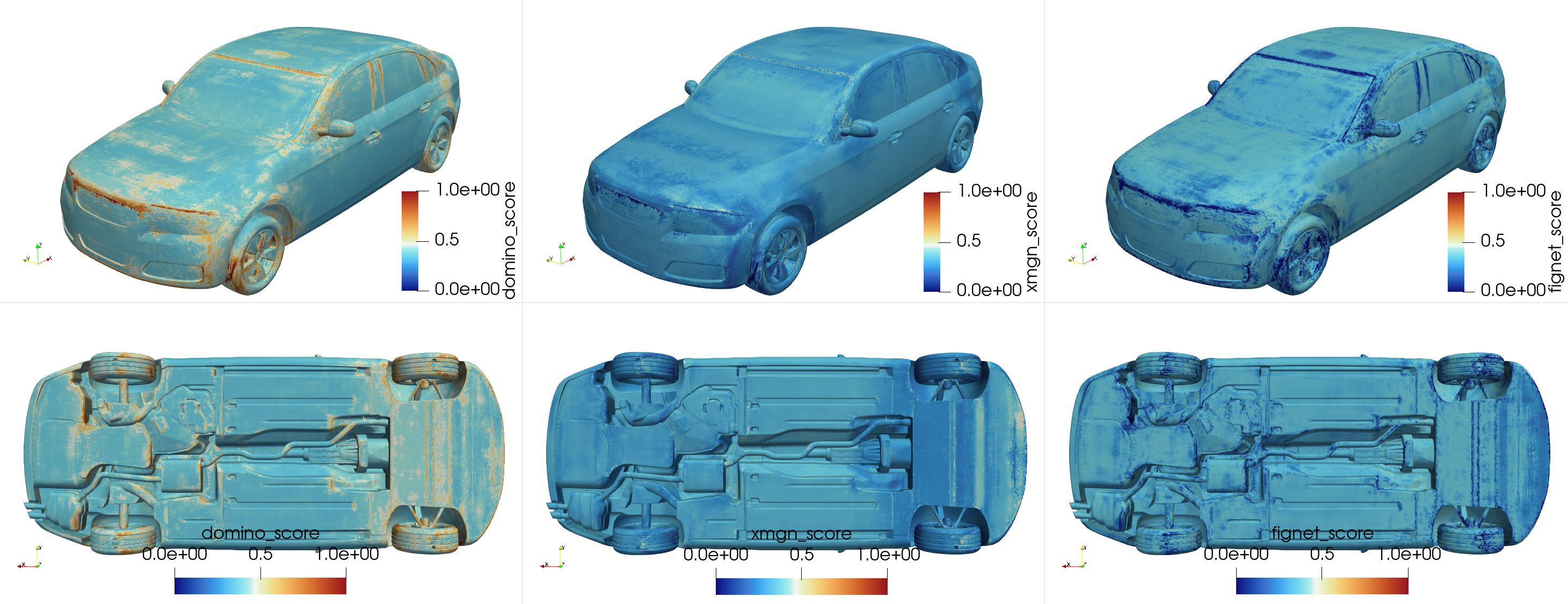
Figure 1: Pointwise MoE gating weights for pressure prediction on a sample from the DrivAerML dataset. The visualization reveals a physically meaningful, spatially-variant weighting strategy learned by the gating network.
Entropy Regularization
A critical innovation of this study is the use of entropy regularization in the loss function to prevent the gating network from degeneratively favoring one expert. This regularization induces a balance in the contribution from each model, maintaining diversity and utilizing the full spectrum of expert knowledge.

Figure 2: Demonstration of model collapse when training without entropy regularization. For pressure prediction on a DrivAerML sample, the gating network assigns nearly all weight to a single expert (DoMINO, shown in blue) across the entire vehicle surface. This "winner-take-all" behavior fails to leverage the strengths of the other experts.
Experimental Design and Validation
The efficacy of the proposed MoE model is validated using the DrivAerML dataset, which provides high-quality CFD simulations necessary for training surrogate models. This validation explores the performance improvements over standalone experts, demonstrating consistent reductions in L-2 prediction error across diverse test input configurations.
Quantitative Analysis
Quantitative evaluation showcases the MoE framework's superior performance relative to individual models. For instance, the MoE model achieves a significant reduction in pressure prediction errors, proving its ability to outperform even the most accurate standalone expert models.
Qualitative Analysis
In qualitative terms, the spatially-variant gating weights reinforce the notion of learned model specialization, exploiting the distinct strengths of each architecture based on geometric and physical input characteristics. These insights underline the gating network's capability in conditional model selection that effectively enriches predictive accuracy.
Results and Discussion
The results affirm the MoE framework's robust ability to create more accurate composite surrogate models by synergistically combining the complementary strengths of heterogeneous architectures. The empirical validation underscores the improvement in predictive performance through the use of entropy regularization and adaptive expert selection.

Figure 3: Unreliable expert scoring without entropy regularization. Duplicating DoMINO predictions as a second input reveals that the gating network assigns inconsistent and arbitrary weights to these identical experts, indicating a failure to provide robust scores.

Figure 4: Demonstration of robust scoring with entropy regularization. When presented with two identical DoMINO expert inputs, the gating network correctly assigns them equal weight, validating the consistency of the regularized model.
Conclusion
This paper's contributions signify a strategic advancement in combining expert models for aerodynamic prediction tasks. The elaborated MoE approach, underpinned by entropy regularization, establishes a powerful mechanism for harnessing the accuracy and robustness needed in industrial-scale CFD applications. The principles demonstrated here extend beyond aerodynamics, offering a transferrable framework to other fields requiring precise surrogate model blending.
Future directions include expanding the expert pool to integrate additional surrogate models, refining the gating mechanisms, and exploring applications in full 3D volumetric flow predictions and uncertainty quantification across broader domains. As AI-driven methodologies continue to evolve, frameworks such as the MoE will play a pivotal role in advancing the precision and reliability of surrogate modeling in scientific and engineering applications.

Figure 5: Gating weights learned when minimizing entropy. This objective function causes the model to become over-confident in a single expert (DoMINO), effectively ignoring X-MeshGraphNet and FigConvNet. This demonstrates the expected inverse behavior to entropy maximization.