RL's Razor: Why Online Reinforcement Learning Forgets Less
Abstract: Comparison of fine-tuning models with reinforcement learning (RL) and supervised fine-tuning (SFT) reveals that, despite similar performance at a new task, RL preserves prior knowledge and capabilities significantly better. We find that the degree of forgetting is determined by the distributional shift, measured as the KL-divergence between the fine-tuned and base policy evaluated on the new task. Our analysis reveals that on-policy RL is implicitly biased towards KL-minimal solutions among the many that solve the new task, whereas SFT can converge to distributions arbitrarily far from the base model. We validate these findings through experiments with LLMs and robotic foundation models and further provide theoretical justification for why on-policy RL updates lead to a smaller KL change. We term this principle $\textit{RL's Razor}$: among all ways to solve a new task, RL prefers those closest in KL to the original model.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
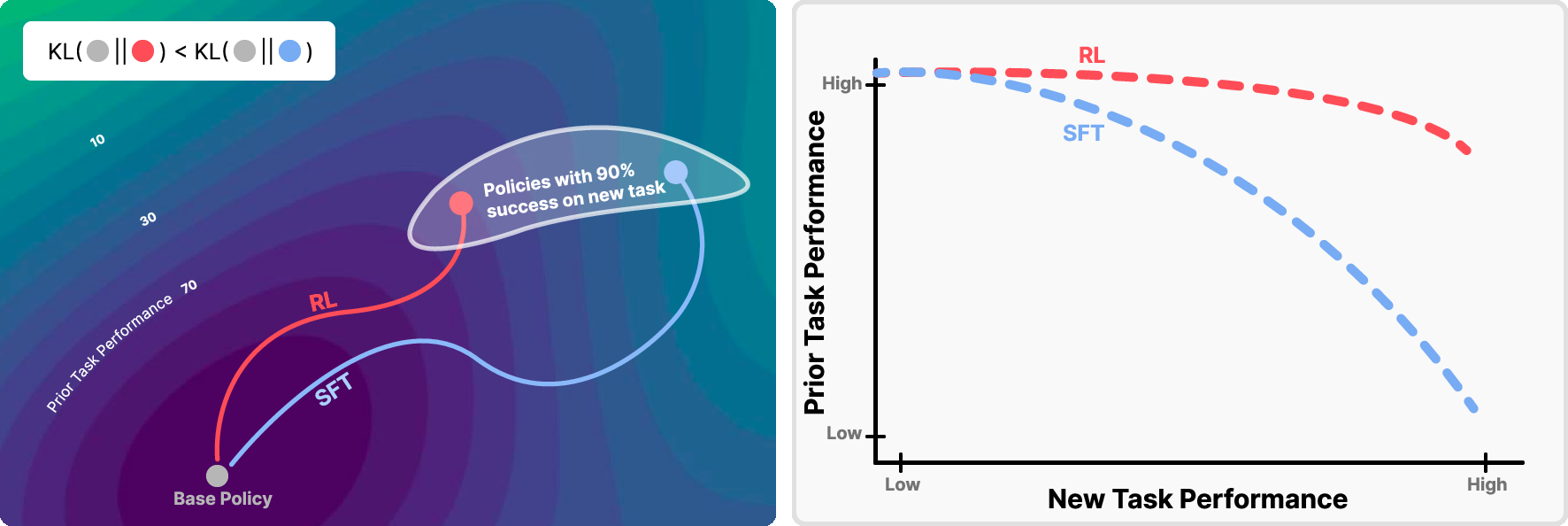
This paper asks a simple question with a big impact: when we teach an AI a new skill, why does it sometimes forget what it already knew? The authors compare two common ways to fine-tune big AI models—Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL)—and discover a clear pattern: RL tends to forget less. They also uncover a simple rule, which they call “RL’s Razor”: among all the ways to solve a new task, RL naturally prefers solutions that stay closest to the original model’s behavior.
What questions does the paper ask?
The paper focuses on three easy-to-understand questions:
- When we update a model to do a new task, which method makes it forget less—SFT or RL?
- Can we predict how much a model will forget without checking every old task one by one?
- Why does RL seem to preserve old knowledge better than SFT?
How did they study it?
To answer these, the authors ran experiments on both LLMs and robot control models, and also created a simple toy example to test ideas thoroughly.
- LLM tasks included math reasoning, science Q&A, and tool use.
- Robotics involved a pick-and-place task in a simulator.
- They measured two things for each trained model: 1) How well it learned the new task. 2) How much it forgot on a variety of older, unrelated benchmarks (like general knowledge, logic, and coding).
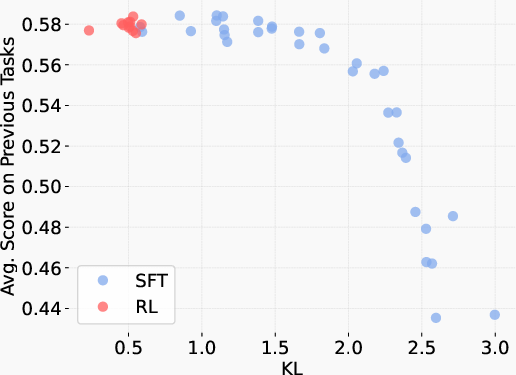
They trained many versions of each model with different settings to see the best possible trade-offs between learning new stuff and keeping old skills (this set of “best trade-offs” is called a Pareto frontier).
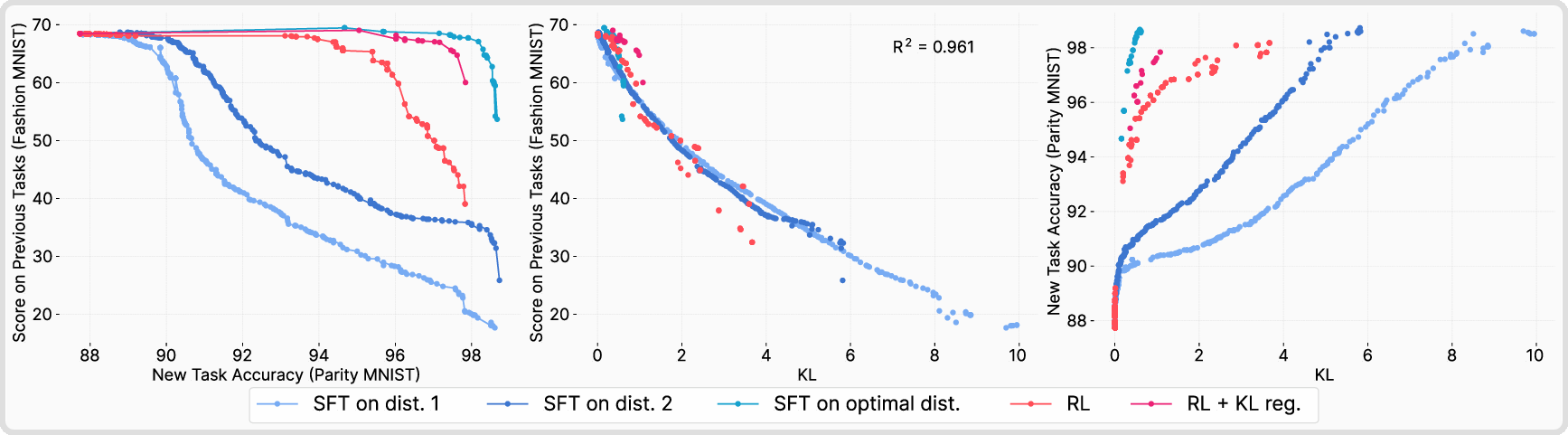
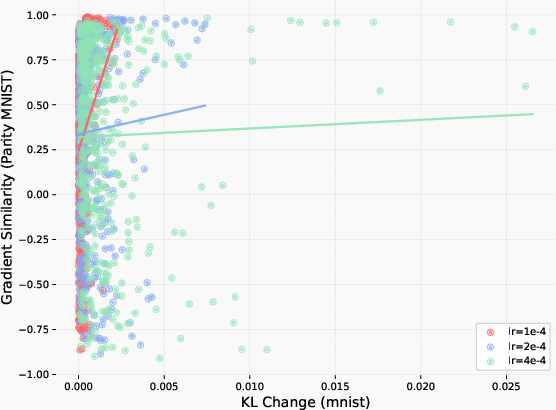
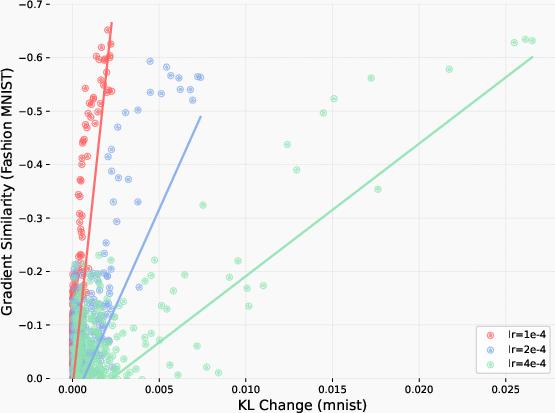
They also built a simple toy setup called ParityMNIST, where an image is correct if the model says any even digit for even images and any odd digit for odd images. This is important because, like many real-world tasks, there are many different correct ways to give a right answer. This toy setting let them run clean, repeatable tests and prove their ideas more clearly.
Key ideas explained in everyday language
- Supervised Fine-Tuning (SFT): The model learns by copying answers from labeled examples. Think of it like studying by repeatedly looking at a teacher’s answer key and trying to match it exactly.
- Reinforcement Learning (RL): The model tries answers, gets a reward if it’s right, and adjusts itself to get more rewards next time. Think of it like practicing a sport: you try, see if you scored, and tweak your moves—but you’re mostly building on what you already do.
- On-policy vs. offline: On-policy methods (like RL here) learn from the model’s own attempts. Offline methods (like SFT) learn from a fixed set of examples created by others. On-policy learning keeps you close to what you already do; offline learning can yank you toward a new style that may not match your old habits.
- KL divergence: A measure of “how much your behavior changed.” Imagine your favorite ice cream flavors: before training, maybe you choose vanilla 70%, chocolate 20%, strawberry 10%. After training, if these percentages barely change, KL divergence is small. If they change a lot, KL is big. In this paper, smaller KL means the new model acts more like the old one.
What did they find?
Here are the main results:
- RL forgets less than SFT at the same new-task performance. In other words, if both methods reach 90% on the new task, the RL-trained model usually keeps more of its old skills than the SFT-trained model.
- “Forgetting follows KL”: How much a model forgets can be predicted by a single number—the KL divergence between the new model and the original model, measured on the new task. Bigger KL means more forgetting.
- Why RL helps: RL is “on-policy,” meaning it learns from its own outputs. That naturally keeps updates small and closer to the original model (small KL). SFT can pull the model toward whatever labels it’s given, even if that makes it drift far from how it used to behave (large KL).
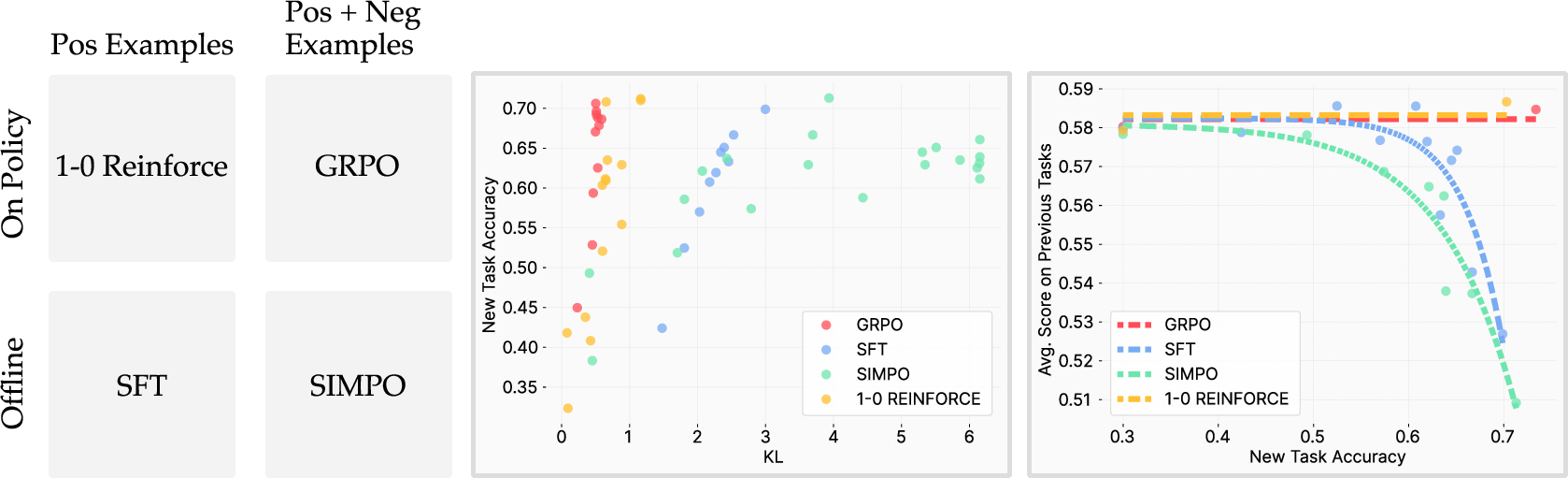
- It’s not about “negative examples” alone: The authors tested several algorithms and found that the key factor is whether the method is on-policy (learning from your own tries), not whether it uses negative feedback.
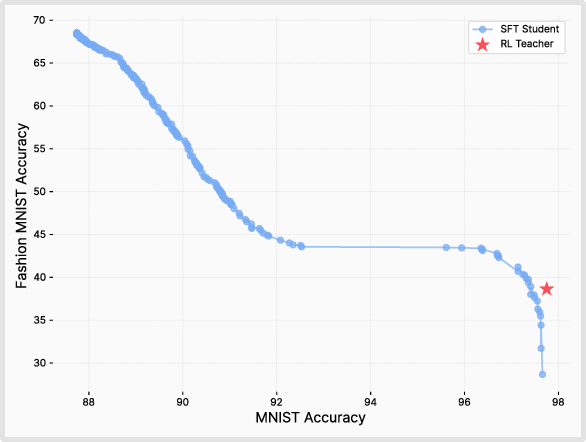
- An “oracle SFT” proves the point: When they carefully designed SFT labels to minimize KL while still being perfectly correct, SFT forgot even less than RL. This shows the secret sauce is staying close in KL, not the RL algorithm itself.
Why is this important?
- Practical prediction: You don’t need old-task data to guess whether you’re causing forgetting. Just measure how much your model’s behavior changes (KL) on the new task. If KL is small, you’re probably safe.
- Safer fine-tuning: If you want models that learn new things without losing old abilities (like chatbots that learn a new tool without getting worse at reasoning), aim to minimize KL change during training.
- Better design choices: Use on-policy approaches (like RL) or guide SFT to prefer solutions that stay close to the original model. This helps build “long-lived” AI systems that keep improving over time without wiping their previous knowledge.
Final takeaway and impact
The paper’s simple rule—RL’s Razor—says that among all the ways to solve a new task, the best are the ones that change the model the least (small KL). RL naturally leans in that direction because it learns from its own behavior. This insight helps researchers and engineers design training methods that let AI models grow new skills while protecting old ones, pushing us closer to reliable, continually learning AI assistants.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Empirical scope is narrow: results are shown for a single mid-sized LLM family (Qwen 2.5 3B) and one robotic foundation model (OpenVLA 7B) on a few tasks; it is unknown whether the KL–forgetting law and RL’s Razor hold for frontier-scale models, multilingual/vision-LLMs, long-context tasks, code, dialog safety, or real-world robotics.
- Real-world robotics not tested: findings are validated in simulation; sim-to-real transfer and physical deployment constraints (latency, safety, nonstationarity) are unaddressed.
- Sequential continual learning: the study considers adaptation to one new task; it is unknown how KL accumulation behaves over long sequences of tasks, whether the “KL budget” composes additively, and how retention scales across many updates.
- Off-policy RL is not studied: the paper explicitly omits off-policy algorithms; it is unclear whether methods with importance sampling, behavior cloning regularizers, or replay buffers maintain the same KL-minimal bias and forgetting behavior.
- Algorithm coverage is limited: only GRPO, 1–0 REINFORCE, SFT, and SimPO are compared; behavior under PPO/TRPO, AWR/AWAC, online DPO/KTO variants, conservative policy iteration, or trust-region policy optimization remains unknown.
- Role of explicit KL regularization in RL: experiments use RL without explicit KL penalties; the interaction between implicit on-policy KL minimization and explicit KL regularizers (coefficient choice, scheduling, trust-region radius) is unquantified.
- Mechanistic cause of forgetting remains unclear: why larger forward KL on the new-task distribution causes prior-task degradation (e.g., representational interference, capacity constraints, layer-wise drift) is not mechanistically established.
- Correlation vs causation: the work demonstrates strong correlations between forward KL and forgetting, but does not perform interventions that hold new-task performance constant while directly manipulating KL to establish causal effects in large models.
- Estimating KL at scale: the paper uses approximate forward KL measured on the new-task distribution; the bias/variance of the estimator, sensitivity to prompt distribution, sequence length, decoding temperature, and token-level vs sequence-level KL are not analyzed.
- Which divergence matters when: forward KL outperforms reverse KL/TV in their settings, but conditions under which reverse KL or other f-divergences better predict forgetting are not characterized.
- New-task distribution dependence: the predictor relies on ; it is unknown how sensitive conclusions are to coverage/shift of , dataset curation, or nonstationary new-task distributions.
- Oracle SFT in practice: while an oracle KL-minimal SFT distribution beats RL in the toy setting, the paper does not provide practical methods to approximate or collect such oracle distributions for complex LLM tasks.
- On-policy supervised data collection: beyond 1–0 REINFORCE, it is unclear whether DAgger-style on-policy relabeling or active data selection for SFT can replicate RL’s KL-minimal path and retention at scale.
- Negative examples conclusion may be underdetermined: SimPO uses externally sampled negatives; it remains open whether on-policy negatives with offline updates, or calibrated preference data, would meaningfully affect KL and forgetting.
- Effect of exploration and entropy bonuses: how entropy regularization, temperature schedules, or diversified sampling impact KL movement and forgetting is not explored.
- Reward design beyond binary success: the study uses binary rewards; it is unknown whether dense/graded rewards, step-level credit assignment, or preference-based rewards change the KL–forgetting relationship.
- Hyperparameter confounds: while many configurations are tried, a controlled analysis of optimizer choice, learning-rate schedules, batch size, and early stopping on KL/retention trade-offs is missing.
- Numeric precision effects: bfloat16-induced apparent sparsity is identified, but the broader impact of numeric precision and quantization on update magnitudes, KL movement, and forgetting is not systematically studied.
- Capability-locality of forgetting: prior-task evaluation aggregates diverse benchmarks; it is unclear which capability clusters (e.g., commonsense, factual recall, coding) are most sensitive to KL shifts or which layers/submodules mediate the effect.
- Function class and nonconvexity gaps: theory assumes finite Y, convex policy families, and binary rewards; extensions to nonconvex neural nets, autoregressive sequence models, continuous actions, partial-credit rewards, and practical optimization noise are unproven.
- Autoregressive structure: the paper does not analyze how per-token vs per-sequence KL, exposure bias, or credit assignment in long sequences affect the KL–forgetting law.
- Safety and alignment implications: minimizing forward KL preserves prior behavior, which may include harmful biases; how to trade off retention against necessary distributional shifts for safety/alignment is not addressed.
- Compute/sample efficiency: RL is typically more expensive; the paper does not quantify compute/sample cost per unit of new-task gain at fixed forgetting, or whether KL-constrained SFT can match RL’s retention more efficiently.
- Task multiplicity assumption: RL’s Razor relies on multiple equally good solutions; for tasks with near-unique targets, does the advantage persist, and how can solution multiplicity be measured or induced?
- Continual pretraining vs post-training: interactions between pretraining strategies (e.g., continual pretraining) and post-training KL control are not investigated.
- Practical KL control mechanisms: beyond the high-level prescription to minimize forward KL, concrete, scalable training recipes (e.g., mirror descent with forward-KL trust regions, constrained decoding, base-distribution reweighting) are not developed or tested.
- Robustness to data overlap/contamination: the impact of overlap between new-task data and prior benchmarks on measured forgetting and KL is not examined.
- Generalization of the quadratic fit: the approximate quadratic relationship between forward KL and forgetting is empirical; its functional form, scaling with model size, and theoretical derivation remain open.
- Capability recovery strategies: the paper does not test post-hoc recovery (e.g., small replay, distillation from base, LoRA merges) under matched KL to assess whether forgetting can be reversed without violating the KL constraint.
- Public resources and reproducibility: detailed KL estimation code, on-policy data collection pipelines, and full hyperparameter sweeps are not described in sufficient detail to assess reproducibility across labs and hardware.
Practical Applications
Immediate Applications
The following applications can be deployed now by integrating on-policy RL and KL-aware procedures into existing post-training and MLOps workflows. Each item notes sectors, concrete tools/workflows, and feasibility assumptions.
- Bold: KL-budgeted post-training for new features without forgetting
- Sectors: software, consumer AI, enterprise AI
- What: Prefer on-policy RL (e.g., GRPO, simple 1–0 Reinforce) over SFT when adding capabilities to LLMs or VLMs to maintain prior skills at matched new-task performance. Track forward KL on new-task prompts during training and early-stop when a KL budget is exceeded.
- Tools/workflows: on-policy sampling trainer, forward-KL monitor E_{x~τ}[KL(π0||π)], “KL budget” early stopping
- Assumptions/dependencies: access to base model logits/tokenizer; representative prompt set for the new task; RL training stability and compute budget
- Bold: MLOps governance with KL drift gates
- Sectors: software, platform/MLOps, regulated industries
- What: Integrate forward-KL drift as a release gate for post-training updates. Treat E_{x~τ}[KL(π0||π)] as a proxy for forgetting when past-task data is unavailable.
- Tools/workflows: CI/CD hooks to compute forward KL on holdout new-task prompts; dashboards; alerting and rollback on KL breaches
- Assumptions/dependencies: retained base snapshot; standardized KL estimation protocol; agreed KL thresholds per product risk profile
- Bold: KL-aware SFT data curation
- Sectors: data labeling, education content, customer-support bots
- What: When multiple correct outputs exist, choose/author labels closest in distribution to the base model’s outputs to reduce forgetting (e.g., select paraphrases consistent with base style, formatting, and reasoning steps).
- Tools/workflows: base-model candidate generation; annotator UI that surfaces base outputs; selection heuristics minimizing token-level forward KL
- Assumptions/dependencies: ability to generate base outputs; clear correctness criteria; may increase labeling effort
- Bold: Reward-light RLHF via binary success signals
- Sectors: software, agents, tool-use automation
- What: Replace complex reward models with binary success/failure indicators (as used in the paper) to drive on-policy RL while retaining prior capabilities.
- Tools/workflows: programmatic checks for tool success, unit-test-style harnesses, pass/fail rubric for reasoning tasks
- Assumptions/dependencies: well-defined success criteria; coverage across tasks; limited reward hacking risk
- Bold: Continual personalization with KL safety rails
- Sectors: consumer assistants, customer support, productivity tools
- What: Adapt models to user/org preferences using on-policy feedback (thumbs up/down, accept/overwrite), enforcing a per-user KL budget to avoid overfitting and global skill loss.
- Tools/workflows: per-tenant LoRA heads trained on-policy; KL per-tenant monitoring; safe rollout/rollback
- Assumptions/dependencies: storage for per-tenant baselines; privacy and consent for learning from interactions
- Bold: RL-to-SFT distillation for cost-effective deployment
- Sectors: software, edge AI
- What: Train with on-policy RL to reach a KL-minimal solution, then distill the learned distribution into an SFT model to reduce serving cost while retaining the low-forgetting behavior.
- Tools/workflows: self-play data generation; teacher-student distillation; regression to teacher logits or samples
- Assumptions/dependencies: teacher access; sufficient synthetic data; careful temperature control to preserve distribution
- Bold: Robotics skill adaptation without erasing prior skills
- Sectors: robotics, manufacturing, logistics, home robotics
- What: Use on-policy RL to teach new tasks (e.g., novel pick-and-place variants) while tracking forward KL versus the base robotic policy to preserve a library of existing skills.
- Tools/workflows: sim-first on-policy data collection; KL monitoring on task observations; safety shields for real-world trials
- Assumptions/dependencies: safe on-policy experience collection; sim-to-real alignment; sensor/action compatibility across tasks
- Bold: Forgetting risk scoring when prior-task data is unavailable
- Sectors: academia, industry R&D
- What: Use E_{x~τ}[KL(π0||π)] as a practical, task-local predictor of forgetting to prioritize experiments, set early stopping, and compare methods at matched new-task accuracy.
- Tools/workflows: standardized prompt suites per new task; Pareto frontier plotting of new-task accuracy vs forward KL vs prior-skill proxy benchmarks (when available)
- Assumptions/dependencies: empirical relationship holds best for generative tasks with multiple valid solutions; calibration needed by domain
- Bold: Federated and edge personalization with KL anchoring
- Sectors: mobile, IoT, enterprise devices
- What: Run small on-policy updates locally and enforce a KL cap relative to a global base to prevent catastrophic drift while achieving personalization.
- Tools/workflows: local RL w/ binary reward; periodic KL audits against cached base logits; server-side policy review
- Assumptions/dependencies: device compute; secure storage of base reference; privacy-preserving telemetry of KL metrics
Long-Term Applications
These applications require additional research, standardization, or scaling to diverse domains, but are directly motivated by the paper’s KL–forgetting law and the RL’s Razor principle.
- Bold: Constrained training algorithms that explicitly implement RL’s Razor
- Sectors: software, robotics, academia
- What: New optimizers that minimize forward KL to the base subject to achieving a target reward/accuracy (solve: minimize E[KL(π0||π)] s.t. E[R] ≥ r*), generalizing policy gradient behavior.
- Tools/products: trust-region–like solvers for forward KL; differentiable constraint handling; open-source libraries
- Assumptions/dependencies: efficient estimators; stability for large models; compatibility with PEFT
- Bold: Automated “oracle SFT” labelers
- Sectors: data platforms, education, enterprise QA
- What: Systems that automatically select or rewrite labels to be correct and closest in forward KL to the base model (approximating the oracle SFT distribution shown to forget less than RL).
- Tools/products: base-model proposal generation; correctness validators; KL-based reranking; active learning
- Assumptions/dependencies: reliable correctness checks; scalable reranking; risk of style lock-in if overconstrained
- Bold: KL-drift reporting standards for AI governance
- Sectors: policy/regulation, high-risk AI (healthcare, finance, critical infrastructure)
- What: Require reporting of forward KL drift from base when post-training models used in safety-critical contexts are updated, with context-dependent KL budgets and audit trails.
- Tools/products: compliance APIs; third-party KL audits; certification programs
- Assumptions/dependencies: consensus on measurement protocols; cross-vendor comparability; legal frameworks
- Bold: Continual-learning “operating systems” for long-lived agents
- Sectors: consumer agents, enterprise copilots, research agents
- What: Always-on on-policy learning with dynamic KL budgets per capability, automatic early stopping, and rollback; multi-objective controllers trading new-task reward vs KL vs safety constraints.
- Tools/products: agent training control planes; KL-aware schedulers; capability-specific baselines
- Assumptions/dependencies: reliable online reward signals; robust drift detection; cost management
- Bold: Fleet-scale robotic adaptation under KL budgets
- Sectors: logistics, manufacturing, agriculture, service robotics
- What: Deploy a shared base policy across a fleet and allow local on-policy updates within KL limits so units adapt to local variation without losing shared skills.
- Tools/products: fleet orchestration with KL policy constraints; shared skill libraries; cross-site evaluation
- Assumptions/dependencies: safe exploration; heterogeneity in hardware; real-time monitoring infrastructure
- Bold: Enterprise multi-tenant model hosting with safe per-tenant adaptation
- Sectors: SaaS, customer support, legal/finance advisory
- What: Provide per-tenant on-policy adaptation with strict KL budgets to base and reversible snapshots so global model quality and safety baselines are preserved.
- Tools/products: tenant isolation; versioned base snapshots; KL-gated deployment; audit logs
- Assumptions/dependencies: storage/compute cost; access control; SLAs for drift incidents
- Bold: Lifelong tutoring systems that adapt without losing curriculum coverage
- Sectors: education
- What: Student-specific adaptation via on-policy feedback (problem attempts, hints accepted) with KL budgets to preserve general pedagogical competence and standards alignment.
- Tools/products: adaptive curricula with correctness signals; KL-aware personalization controllers
- Assumptions/dependencies: robust scoring of learning gains; fairness and privacy safeguards
- Bold: Clinical decision support tuned to local protocols without eroding general knowledge
- Sectors: healthcare
- What: On-policy RL with binary protocol adherence signals and tight KL budgets to the base (evidence-based medicine) to localize to hospital workflows.
- Tools/products: clinical simulators/checklists; KL governance panels; post-update validation suites
- Assumptions/dependencies: regulatory approval; rigorous validation; bias and safety monitoring
- Bold: Compliance-centered assistants that adapt to firm policies yet retain conservative defaults
- Sectors: finance, legal, risk
- What: On-policy RL from compliance officer feedback with KL caps to base safety behaviors; automatic forgetting risk alerts from KL spikes.
- Tools/products: review consoles; KL-based risk scoring; change management workflows
- Assumptions/dependencies: curated policy corpora; human-in-the-loop oversight; auditability
- Bold: Auto-early stopping and rollback driven by forgetting forecasts
- Sectors: MLOps, platform
- What: Predict catastrophic forgetting from real-time forward KL growth on new-task data and pause/rollback training automatically before prior-task regressions manifest.
- Tools/products: online KL estimators; forecast models; policy engines for training control
- Assumptions/dependencies: stable KL–forgetting correlation in the target domain; low-latency training control hooks
Cross-cutting assumptions and dependencies
- On-policy sampling access: Training pipelines must sample from the current model and retain a compatible base model for KL reference (same tokenizer/logit space).
- KL estimation quality: Forward KL is estimated on a representative new-task input distribution; mis-specified prompt sets can distort forgetting risk.
- Compute and stability: On-policy RL typically costs more than SFT; binary rewards and lightweight policy-gradient variants can mitigate overhead but still require careful tuning.
- Domain limits: Empirical law validated on moderate-scale LLMs and robotic models; behavior at frontier scales and in other modalities may require additional evidence and calibration.
- Safety and oversight: Especially in robotics and safety-critical sectors, on-policy data collection and updates need guardrails, simulators, and human review.
Collections
Sign up for free to add this paper to one or more collections.

