Why Language Models Hallucinate
Abstract: Like students facing hard exam questions, LLMs sometimes guess when uncertain, producing plausible yet incorrect statements instead of admitting uncertainty. Such "hallucinations" persist even in state-of-the-art systems and undermine trust. We argue that LLMs hallucinate because the training and evaluation procedures reward guessing over acknowledging uncertainty, and we analyze the statistical causes of hallucinations in the modern training pipeline. Hallucinations need not be mysterious -- they originate simply as errors in binary classification. If incorrect statements cannot be distinguished from facts, then hallucinations in pretrained LLMs will arise through natural statistical pressures. We then argue that hallucinations persist due to the way most evaluations are graded -- LLMs are optimized to be good test-takers, and guessing when uncertain improves test performance. This "epidemic" of penalizing uncertain responses can only be addressed through a socio-technical mitigation: modifying the scoring of existing benchmarks that are misaligned but dominate leaderboards, rather than introducing additional hallucination evaluations. This change may steer the field toward more trustworthy AI systems.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple question: Why do AI LLMs sometimes make up confident, believable answers that are wrong (often called “hallucinations”)? The authors argue that these mistakes aren’t mysterious. They mostly come from how we train and score models today, which quietly encourages guessing instead of saying “I don’t know.”
What questions do the authors ask?
- Why do LLMs produce believable false answers, even when they “should” say they’re unsure?
- Does this happen because of how we first train models on massive text (pretraining), or because of the later tuning to be helpful and safe (post‑training), or both?
- How do current tests and leaderboards push models to bluff?
- What practical changes would make models more honest and trustworthy?
How do they study the problem?
The paper uses math and simple analogies rather than big experiments. Here’s the core idea in everyday terms.
A simple test: “Is-It-Valid?” (IIV)
Imagine you could turn any LLM into a yes/no tester that answers: “Is this response valid or not?” The authors show that:
- If a model can’t perfectly pass this simple yes/no test, then when it has to generate full answers, it will make mistakes.
- In fact, the model’s rate of making wrong generations is closely tied to how often it would fail the yes/no test. Roughly, if the model mislabels some percentage of cases in the simple test, it will make at least about twice that percentage of errors when producing full answers.
This connects “generation” (writing answers) to “classification” (yes/no decisions). Errors that are common in basic classification show up as hallucinations when the model writes.
Why pretraining alone still causes mistakes
Pretraining teaches a model to match the overall patterns of language (what words and sentences look like). Even if the training text were perfect and error‑free, that objective still leads to some wrong outputs because:
- Some facts just don’t have a learnable pattern (for example, random details like a lesser‑known person’s birthday). If the data doesn’t provide enough signal, the model can’t reliably learn them.
- The authors show a lower bound: if certain facts appear only once in the training data (so the model never sees them again), the model will often guess. In other words, the “hallucination rate” on those facts is at least as big as the fraction of such “one‑off” facts. Example: If 20% of birthday facts appeared only once in the data, expect at least about 20% wrong answers when asked those kinds of birthday questions.
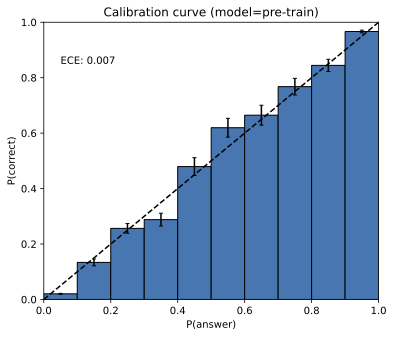
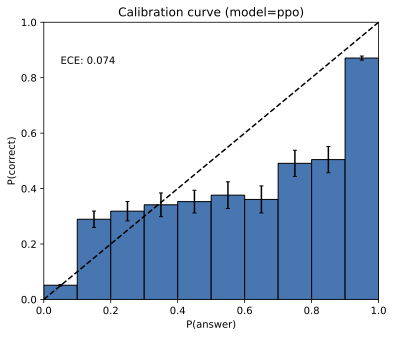
They also explain “calibration”: a calibrated model’s confidence should match reality (e.g., things it says with 70% confidence should be right about 70% of the time). The common pretraining objective (cross‑entropy) tends to push models toward calibration. Ironically, being well‑calibrated while trying to cover broad language patterns makes some mistakes unavoidable.
Why post‑training and exams can make things worse
After pretraining, we fine‑tune models to be helpful and pass benchmarks. But most benchmarks score like school tests: 1 point for correct, 0 for incorrect, and 0 for “I don’t know.” That grading makes guessing strictly better than admitting uncertainty. So:
- Models learn to bluff when unsure, because that wins more points.
- This keeps hallucinations alive, even if the model internally “knows” it’s not confident.
What did they find?
Here are the main takeaways, in plain language:
- Hallucinations naturally arise from the statistics of learning:
- If a model sometimes can’t tell valid from invalid answers in a simple yes/no check, it will make mistakes when generating full answers.
- For “arbitrary facts” (like random birthdays) that don’t repeat in the data, models will often guess. The more one‑off facts in the training set, the more hallucinations you should expect on that type of question.
- Being a “good test‑taker” under today’s binary grading (right/wrong only) rewards guessing over honesty. That’s a big reason hallucinations persist after post‑training.
- Some errors come from limited model designs (for example, old‑style models that only look at a couple of words at a time can’t capture long‑range grammar rules), from hard problems (some questions are computationally tough), from out‑of‑distribution prompts (weird questions the model rarely saw), and from bad data (garbage in, garbage out).
- It’s not that hallucinations are inevitable for every possible system. A tool‑using or lookup‑based system could say “I don’t know” for anything it can’t verify. But a general LLM trained to match broad language patterns—and graded like a multiple‑choice test—will produce some confident mistakes.
Why this matters:
- It explains a stubborn real‑world problem in a clear, general way.
- It shows that simply adding more training data or tinkering with decoding may not fix the core issue.
- It points to the evaluation rules (how we score models) as a major driver of overconfident mistakes.
What do they propose to fix it?
The authors suggest a socio‑technical change: don’t just invent more “hallucination tests.” Instead, change the scoring of existing, popular benchmarks so they stop punishing uncertainty.
- Add explicit confidence targets to prompts on mainstream benchmarks:
- Tell the model: “Only answer if you’re more than t‑percent confident. A wrong answer loses t/(1−t) points. ‘I don’t know’ is 0 points.”
- Examples: t = 0.5 (penalty 1), t = 0.75 (penalty 2), t = 0.9 (penalty 9).
- With this rule, it’s better to say “I don’t know” when you’re not confident, and better to answer only when you are.
- Make these rules part of the instructions so behavior is unambiguous and fairly graded.
- Use these confidence‑aware rules in the big leaderboards that everyone already cares about. That way, models will be rewarded for honest uncertainty, not punished for it.
The authors also introduce “behavioral calibration”: instead of reporting a number like “72% confident,” the model should simply choose to answer or abstain in a way that matches the stated confidence threshold. This is easier to evaluate fairly and encourages the right behavior.
Key terms in simple words
- Hallucination: A confident, believable answer that’s wrong.
- Pretraining: The first phase of training on huge amounts of text to learn language patterns.
- Post‑training: Extra training to make the model helpful, safe, and better at tests.
- Calibration: Matching confidence to reality (e.g., when you say “I’m 80% sure,” you’re right about 80% of the time).
- Benchmark/Leaderboard: Standard tests and rankings used to compare models.
- “Is‑It‑Valid?” (IIV): A simple yes/no check—does a response look valid or not?
- Singleton rate: How often a specific fact appears only once in the training data; a signal that the model can’t learn that fact reliably.
- Distribution shift: When test questions look different from the training data.
- Garbage in, garbage out (GIGO): If training data contains errors, models can learn and repeat them.
Limitations and what’s next
- This is a theory‑heavy paper: it builds a careful argument rather than running lots of new experiments. Real systems can have extra tricks (like search tools) that change behavior.
- Fixing hallucinations isn’t just about one new metric; it needs community adoption—changing how popular tests score answers.
- Still, the plan is practical: clearly state confidence rules in benchmark prompts and adjust scoring so “I don’t know” is sometimes the best, most honest choice.
Bottom line
LLMs often “hallucinate” because:
- Pretraining makes some errors unavoidable, especially for rare or random facts.
- Post‑training benchmarks reward guessing under right/wrong scoring.
The fix isn’t only better models—it’s better scoring. If we change today’s popular evaluations to reward honest uncertainty, we can steer models toward being more trustworthy, careful, and aligned with how we actually want them to behave.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to guide concrete follow-up research.
- Empirical validation of theory-to-practice: The reduction from generation to IIV classification and the derived lower bounds (e.g., err ≥ 2·IIV error − terms) lack large-scale empirical validation across modern LLM families, datasets, and decoding regimes.
- Realism of the “uniform error” assumption: The IIV construction samples errors uniformly from the error set E (and uses 50/50 mixes), which is unlikely to reflect real error distributions; quantify how non-uniform or structured error distributions alter the bounds or the reduction.
- Finite plausibility set assumption: The analysis relies on a finite plausible string set X and known |E_c|; operationalizing X and estimating |E_c| for open-ended, long-form text remains undefined and may be infeasible in practice.
- Calibration term δ scope: The δ measure is defined at a single threshold t = 1/|E|, weaker than ECE; develop theoretically principled and practically auditable multi-threshold or sequence-level calibration criteria that retain the reduction’s guarantees.
- Cross-entropy ⇒ calibration claim: The argument that cross-entropy optimization yields small δ is heuristic; formalize conditions (model class properties, optimization behavior, early stopping, label smoothing) under which δ is provably small, and test empirically.
- Impact of token-level vs sequence-level training: The analysis abstracts away next-token training; quantify how token-level teacher forcing, exposure bias, and decoding compose to sequence-level generative error rates predicted by the reduction.
- Decoding effects: The role of temperature, top-k/p sampling, nucleus sampling, and beam search on hallucination rates and calibration is not modeled; characterize how decoding strategies modulate the derived lower bounds and abstention behavior.
- Post-training calibration drift: The paper highlights calibration changes post-RL (e.g., GPT-4 PPO) but lacks a systematic study; measure when, how, and why post-training breaks or restores calibration across tasks and models.
- Noisy and partially wrong training data (GIGO): The theoretical results assume p(V) = 1; extend the framework to explicit noise models (random/class-conditional/correlated label noise, partial truths) and derive tight bounds on generative errors under noise.
- Retrieval-augmented and tool-using systems: Although claimed to apply broadly, there is no formal treatment of RAG/tools; model retrieval noise, document trustworthiness, tool error, and time-varying knowledge, and extend theorems to these pipelines.
- Multi-turn interaction: The analysis treats single-turn prompt–response; extend to multi-turn dialogues where uncertainty can be reduced via clarification questions, and study incentives under benchmarks that price/penalize clarification.
- Open-ended evaluation scoring: The proposal focuses on binary-to-penalized abstention; develop principled scoring for open-ended, LM-graded or rubric-based tasks that avoid rewarding bluffs and allow abstentions without collapsing coverage.
- Confidence-target adoption: The socio-technical recommendation (explicit confidence thresholds t) lacks empirical studies on adoption barriers, user acceptance, and leaderboard impacts; run controlled trials with organizers to measure feasibility and side effects.
- Choosing and calibrating t: Provide normative and domain-specific guidance for setting threshold t (e.g., risk-based, stakeholder-driven), including per-task heterogeneity and fairness across languages and domains.
- Behavioral calibration auditing: Define robust, reproducible audits for “behavioral calibration” (coverage–accuracy curves vs t) and specify pass/fail criteria that are hard to game with templated IDK strategies.
- Preventing gaming under LM graders: LM-based graders can be fooled by confident bluffs; design verifiable graders (symbolic checkers, reference-based equivalence, adversarial rubric stress tests) resistant to stylistic overconfidence.
- Selective prediction theory bridge: Connect the results explicitly to selective classification/conformal prediction; develop actionable selective-generation training objectives with coverage guarantees and abstention calibration.
- Trade-offs with breadth/diversity: The paper cites inherent breadth–consistency trade-offs but does not quantify how explicit abstention scoring shifts this frontier; characterize Pareto curves among breadth, abstention rate, and hallucinations under different t.
- Measuring singleton rates in-the-wild: Theorem-driven claims about singleton rates (sr) need measurement across fact types (biographies, science, code APIs) in modern corpora; build pipelines to estimate sr and correlate with hallucination rates.
- Tokenization-induced failures: The letter-counting example hints at tokenization issues; systematically analyze how tokenization schemes influence hallucination classes (character-level, morphology, numeracy) and propose mitigations.
- Distribution shift formalization: Provide distribution-shift-aware bounds (covariate, label, concept shift) for generative errors, and practical OOD detectors tied to abstention policies that preserve coverage–accuracy guarantees.
- Complexity barriers and refusal policy: For computationally hard queries, specify principled refusal/IDK policies and tool fallback strategies; analyze user experience trade-offs and how benchmarks should grade such refusals.
- Defining plausibility in practice: The boundary between “plausible” and “nonsense” outputs is assumed but not operationalized; propose practical criteria or detectors (fluency, syntax, semantics) to construct X and evaluate sensitivity to this choice.
- Multiple correct answers and equivalence classes: Extend the analysis and scoring to prompts with many semantically equivalent correct answers; specify matching/equivalence mechanisms that don’t penalize cautious under-specification.
- Confidence communication beyond IDK: The paper references graded uncertainty language but does not integrate it into scoring; design and validate rubrics that reward calibrated hedging and evidence-citing without incentivizing verbosity.
- Interaction with safety alignment: Analyze conflicts between abstention incentives and safety refusals (e.g., over-refusal); propose joint objectives and evaluations that separate safety-driven refusals from uncertainty-driven abstentions.
- Accessibility and multilinguality: Investigate how confidence-target instructions and abstention lexicons transfer across languages/cultures, and how graders reliably recognize IDK/hedges multilingualy.
- Practical computation of p̂(r|c): The reduction assumes access to sequence-level probabilities for thresholding; detail how to approximate or proxy p̂(r|c) for long generations and how approximation error affects bounds and audits.
- Effects of continual/online learning: Study how ongoing fine-tuning, retrieval updates, and tool improvements shift calibration, singleton rates, and hallucination incidence over time.
- Benchmark coverage and representativeness: The meta-evaluation of benchmark scoring policies is limited; conduct a comprehensive survey across domains (STEM, legal, medical, coding, multilingual) and publish a standardized taxonomy and scoring recommendations.
- User-centered thresholding: Explore adaptive thresholds t conditioned on user-stated risk tolerance or task criticality; design interfaces and scoring that faithfully elicit and enforce such preferences.
- Cost of clarification and abstention: Quantify utility trade-offs when models abstain or ask clarifying questions (latency, user effort), and design benchmarks that incorporate these costs transparently.
- Verification-first pipelines: Examine whether integrating verification (self-check, external search, tool use) before answering can reduce hallucinations without sacrificing calibration; compare against abstention-only strategies under confidence targets.
- Formal integration of prompts with IDK sets: The framework assumes known abstention sets A_c; specify practical corpora or schema for standardizing abstention phrases and preventing false positives in grading.
Collections
Sign up for free to add this paper to one or more collections.