A Unified Definition of Hallucination, Or: It's the World Model, Stupid
Abstract: Despite numerous attempts to solve the issue of hallucination since the inception of neural LLMs, it remains a problem in even frontier LLMs today. Why is this the case? We walk through definitions of hallucination used in the literature from a historical perspective up to the current day, and fold them into a single definition of hallucination, wherein different prior definitions focus on different aspects of our definition. At its core, we argue that hallucination is simply inaccurate (internal) world modeling, in a form where it is observable to the user (e.g., stating a fact which contradicts a knowledge base, or producing a summary which contradicts a known source). By varying the reference world model as well as the knowledge conflict policy (e.g., knowledge base vs. in-context), we arrive at the different existing definitions of hallucination present in the literature. We argue that this unified view is useful because it forces evaluations to make clear their assumed "world" or source of truth, clarifies what should and should not be called hallucination (as opposed to planning or reward/incentive-related errors), and provides a common language to compare benchmarks and mitigation techniques. Building on this definition, we outline plans for a family of benchmarks in which hallucinations are defined as mismatches with synthetic but fully specified world models in different environments, and sketch out how these benchmarks can use such settings to stress-test and improve the world modeling components of LLMs.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at a common problem in AI called “hallucination.” That’s when an AI confidently says or does something that isn’t true. The authors argue that, at heart, hallucination happens because the AI’s “world model” (its internal mental map of how things work) is wrong. They propose one clear, unified way to define and measure hallucinations across many kinds of AI tasks (like answering questions, summarizing, using a web browser, or understanding images).
Key Questions
The paper asks three main questions in simple terms:
- What exactly should we mean when we say an AI “hallucinates”?
- How can we test hallucinations fairly across very different tasks?
- How can this help us compare fixes and make better benchmarks (tests) for AIs?
Methods and Approach
The authors do two things:
- They review the history of how different research fields have defined hallucination:
- In translation and summarization: “unfaithful to the source document.”
- In open-domain question answering: “factually wrong according to the real world.”
- In agent tasks (like web browsing): “acting as if the world has things that aren’t there.”
- In multimodal AI (text + images/audio): “language beliefs conflict with what the picture/sound shows.”
- They offer one unified framework using everyday ideas:
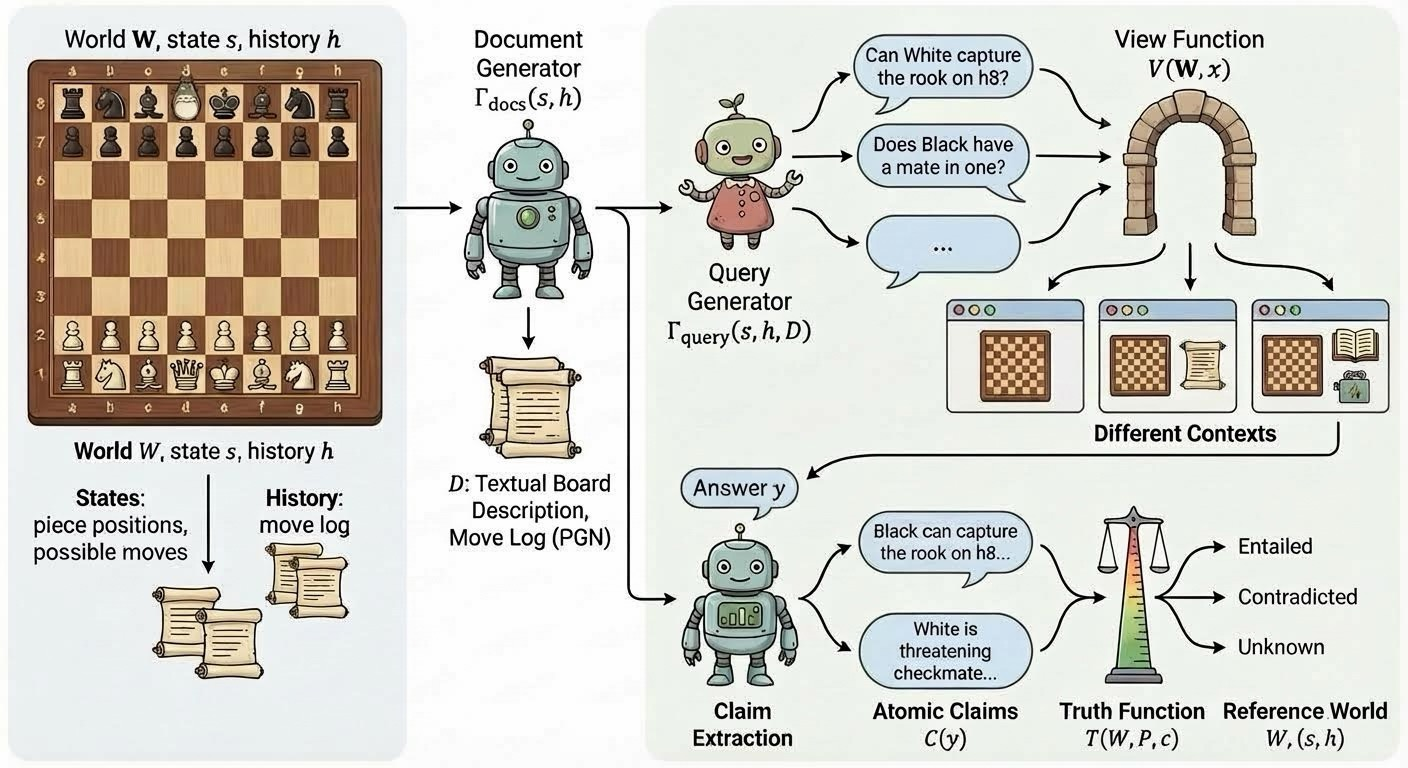
- World model: Think of this as the “reference map” of what’s true. It can be a source document, a database, a picture, or the actual state of a website or game.
- View: This is the part of the world the AI is allowed to see for the task (for example, the article to summarize or the webpage’s layout).
- Conflict policy: A simple “who’s the boss” rule that says which source wins when there’s a disagreement (for example, “the document overrides the AI’s memory”).
- Truth function: A judge that checks each small statement (an “atomic claim,” like “The capital is X”) and labels it true, false, or unknown.
In their definition, an AI hallucinates if its output contains at least one atomic claim that is false according to the chosen world model and conflict policy.
They also show how to build practical benchmarks:
- Generate a world with known facts (like a chess position).
- Produce documents from that world (like a board description or move list).
- Ask questions or tasks.
- Limit what the AI can see (its view).
- Automatically check the AI’s claims against the world to flag hallucinations.
Main Findings
- A single, simple definition works across many tasks: hallucination is an “inaccurate internal world model” made visible through the AI’s output.
- This definition forces researchers to state what counts as “truth” for each test, what the AI is allowed to see, and how conflicts are resolved. That makes evaluations clearer and fairer.
- Not all mistakes are hallucinations. The paper separates:
- Hallucinations: incorrect beliefs about the world.
- Planning errors: the AI understands the world but chooses bad steps.
- Incentive errors: the AI sounds confident even when unsure because of how it’s trained or rewarded.
- They show examples:
- Summarization: saying the company “beat expectations” when the article says it missed them.
- Open Q&A: naming the wrong Nobel Prize winner.
- RAG (retrieval-augmented generation): contradicting retrieved evidence.
- Agent tasks: clicking a button that doesn’t exist.
- They outline a recipe for scalable benchmarks where truth is known and labels can be computed automatically. Chess is a clear example: the board state and rules tell us exactly whether a claim (like “White can capture the queen in one move”) is true or false.
Why It’s Important
This unified view has practical impact:
- Clearer testing: Researchers must say what counts as “truth,” what the AI sees, and which source wins in conflicts. That reduces confusion across papers and tasks.
- Better benchmarks: Using fully specified worlds (games, simulators, databases) allows automatic, large-scale tests of hallucinations without needing lots of human labels.
- Smarter fixes: It becomes easier to match solutions to problems:
- Improve the view: give the AI better, more relevant context.
- Set better policies: teach the AI which source to trust when things disagree.
- Upgrade the world model: train the AI to build more accurate internal maps.
- Real-world safety: In areas like healthcare, law, or coding, making sure the AI’s claims match a known source of truth is essential to avoid dangerous false statements.
Conclusion and Future Directions
The paper proposes a unified, simple idea: hallucination is when an AI’s internal picture of the world conflicts with a chosen reference world and that conflict shows up in its output. This helps everyone compare tests and fixes using the same language, and it opens the door to large, automatic benchmarks.
Two important next steps the authors suggest are:
- Testing different conflict policies: for example, does retrieved text beat the AI’s memory, or does the environment snapshot beat instructions? Can we train AIs to follow these policies reliably?
- Handling changing worlds: in real life, what’s true can change. Benchmarks should test whether AIs can adapt their world model as new information arrives over time.
Overall, focusing on the AI’s world model makes the problem clearer and helps build better tools to measure and reduce hallucinations.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concrete list of gaps and unresolved questions that emerge from the paper’s unified definition of hallucination and its proposed benchmark direction. These are intended to guide actionable future research.
- Operationalizing the truth function across domains: How to implement the truth function
T_{W,P}for diverse tasks (open-domain QA, RAG, multimodal perception, agentic actions) with reliable, reproducible verifiers, especially when sources are noisy, conflicting, or probabilistic. - Defining and extracting atomic claims consistently: Robust methods to decompose outputs into atomic claims
C(y)across text, code, math, and actions (e.g., clicks, API calls). Address coreference, quantifiers, hedging, uncertainty markers, temporal references, and multimodal bindings. - Automating claim verification without LLM bias: Standardized, transparent verification pipelines that minimize dependencies on LLM-as-judge and provide error bounds; reference implementations for common domains and modalities.
- Conflict policy specification and adherence: Practical protocols for declaring, enforcing, and measuring adherence to conflict policies
P(e.g., “retrieved docs override parametric memory”) under adversarial or corrupted contexts; methods to train models to respect statedP. - Inferring or negotiating conflict policies: Techniques for models to understand, request, or infer
Pwhen it is underspecified or ambiguous in user tasks; guidelines for user–model interactions to makePexplicit. - Handling dynamic, non-stationary reference worlds: Benchmarks and methods for changing
W(streaming updates, long-horizon interactions) including consistency under evolving knowledge, temporal validity windows, and rollback/rescission operations. - Labeling “unknown” rigorously: Clear criteria and tools for assigning
unknowninT_{W,P}(epistemic vs. aleatory uncertainty), and evaluation protocols that reward abstention/calibration rather than confident guesses. - Distinguishing hallucinations from planning and incentive errors: Diagnostic methodologies and instrumentation (especially in agentic settings) to separate incorrect beliefs (hallucination) from correct-belief poor planning or reward-driven overclaiming.
- Severity- and risk-weighted metrics: Beyond counting false atomic claims, develop impact-aware scoring that weights claims by downstream harm, criticality, or scope (e.g., clinical vs. trivial mistakes).
- Transferability from synthetic to real-world tasks: Empirical validation that hallucination behavior measured in synthetic environments (e.g., chess) correlates with real-world performance; criteria to select environments with high ecological validity.
- Building scalable, trustworthy reference worlds: Processes and tooling to construct
Wat scale for real domains (logs, KBs, simulators), track provenance, and reconcile inconsistent or contested facts. - View function fidelity and robustness: Systematic study of how
V(W,x)choices (partial observation, retrieval errors, context truncation) affect hallucinations; methods to control or adaptVat test time. - Multimodal truth evaluation: Frameworks to verify claims from images/audio/video under perception uncertainty, occlusion, or illusions; standardized datasets for cross-modal claim grounding.
- Agentic observation accuracy and staleness: In interactive environments, how to guarantee the agent’s observations (e.g., DOM snapshots) reflect current ground truth; protocols for dealing with stale views or race conditions.
- Action claim extraction and verification: Defining atomic action claims (e.g., “clicked button#submit-btn”) and verifying them against environment state/history; handling side effects and multi-step dependencies.
- Contested or normative truth in
W: Guidance for tasks involving legal, ethical, or culturally contingent facts; methods to encode normativity, jurisdiction, or community standards withinWandP. - Cross-lingual and cross-cultural coverage: Extending
W, verifiers, and claim extraction to multilingual contexts; handling differing world knowledge and ontologies across languages. - Benchmarks for policy co-variation: Experimental suites that co-vary both
WandP(e.g., temporally evolvingWwith partial override policies), with clear ground-truth labels and expected model behaviors. - Standard documentation for
W,V, andP: Dataset cards and evaluation manifests that precisely specify assumptions, sources of truth, access patterns, and conflict rules to aid reproducibility and comparability. - Measuring internal world-model quality: Methods to relate observable hallucinations to internal representations (e.g., probing, mechanistic interpretability), and evaluate whether interventions actually improve the model’s latent world model.
- Training interventions targeted at world modeling: Concrete curricula, data selection, representation learning, and objective designs (beyond generic pretraining/RLHF) that directly improve alignment with
Wand reduceT_{W,P} = false. - Calibration and abstention integration: Joint evaluation of hallucination, uncertainty calibration, and abstention behavior; training to prefer “unknown” when
V(W,x)is insufficient. - Cost and scalability of verification: Practical strategies to reduce computational overhead for claim extraction and truth checking at scale; batching, caching, incremental verification, and verifier optimization.
- Chain-of-thought and intermediate outputs: Policies for whether and how to score hallucinations in reasoning traces vs. final answers; mechanisms to prevent penalizing exploratory thoughts that are later corrected.
- Reliance on LM-generated artifacts in
D: Risks and controls when paraphrasing or generating documents fromWvia LMs (potentially introducing spurious errors); safeguards to prevent label leakage or contamination. - Benchmark completeness for agentic and multimodal cases: The framework outlines agentic and multimodal considerations but lacks concrete, implemented benchmark suites with public tools, verifiers, and baselines in these settings.
- Empirical validation of the unified definition: No large-scale experiments demonstrating that the proposed definition better predicts downstream failures or unifies disparate benchmarks compared to existing framings; design and execution of such studies remain open.
Practical Applications
Immediate Applications
Below are practical uses that can be deployed now, grounded in the paper’s unified world-model framing of hallucination. Each item indicates sectors, candidate tools/products/workflows, and key dependencies or assumptions.
- Explicit truth-contracts in LLM deployments
- Description: Require every evaluation or production task to declare its reference world model W, visible inputs V, and conflict policy P; implement a per-claim truth function T for outputs.
- Sectors: software, healthcare, finance, legal, education, public sector.
- Tools/Products/Workflows: “World Model Contract” schema (JSON/YAML), “Truth Function API,” policy-aware prompting templates, evaluation checklists.
- Assumptions/Dependencies: Availability of authoritative sources (KBs, documents, logs); organizational agreement on conflict policies.
- Claim-level verification pipelines for RAG and reporting
- Description: Decompose LLM outputs into atomic claims, verify each against W under P, and tag as supported/contradicted/unknown; refuse or revise when contradictions exist.
- Sectors: software, healthcare (guidelines, EHR), finance (earnings summaries), legal (citations), journalism.
- Tools/Products/Workflows: Claim extraction microservice, retrieval/verifier orchestrator, “Generate → Decompose → Verify → Decide” pipeline, abstention/calibration modules.
- Assumptions/Dependencies: Reliable claim extraction, high-quality retrieval/verifiers, latency/compute budgets, curated domain KBs.
- Agent runtime monitors that distinguish hallucination vs. planning errors
- Description: For browser/coder agents, continuously compare proposed actions and stated beliefs to environment state (DOM, filesystem, repository) to flag observation hallucinations separately from poor planning.
- Sectors: software engineering, web automation, IT operations.
- Tools/Products/Workflows: DOM/FS “action verifiers,” environment snapshots, agent logs annotated with W/V/P, guardrails that gate actions on truth checks.
- Assumptions/Dependencies: Accurate environment instrumentation, deterministic snapshots, action-verifier coverage.
- Multimodal knowledge-conflict checking
- Description: In VLMs, enforce conflict policies that prioritize visual/audio evidence over language priors where specified; auto-detect “language hallucination” vs. “visual illusion.”
- Sectors: robotics, manufacturing QA, medical imaging, assistive tech.
- Tools/Products/Workflows: Modality-priority policies, cross-modal entailment checkers, scenario-specific verifiers.
- Assumptions/Dependencies: Quality and calibration of perception models; clear policy on modality precedence.
- Compliance-grade summarization and synthesis
- Description: Summarizers that treat source documents as W and mark extrinsic/intrinsic hallucinations; produce evidence-linked summaries with claim tags.
- Sectors: finance (regulatory filings), legal (contracts), healthcare (clinical notes).
- Tools/Products/Workflows: Source-faithful summarization templates, claim/evidence links, “unknown” labeling with abstention.
- Assumptions/Dependencies: Access to canonical source of truth, auditors’ acceptance of “unknown” tags.
- Policy-aware documentation and academic benchmarking checklists
- Description: Journals, conferences, and vendors adopt submission/benchmark templates that require explicit W, V, P, T disclosures.
- Sectors: academia, standards bodies, procurement.
- Tools/Products/Workflows: Reviewer checklists; benchmark “cards” with W/V/P/T; procurement RFP clauses.
- Assumptions/Dependencies: Community buy-in; minimal friction added to workflows.
- Domain KB–centric assistants
- Description: Assistants that default to guideline/KB truth (P: KB overrides parametric memory) and return “unknown” rather than speculating.
- Sectors: healthcare, tax/compliance, enterprise IT.
- Tools/Products/Workflows: KB-priority policies, per-claim certainty scores, refusal training.
- Assumptions/Dependencies: Up-to-date KBs; organizational tolerance for refusals/unknowns.
- Developer tooling for code assistants
- Description: Integrate repository, filesystem, test results, and call stacks into V; verify claims about files, functions, and build state before suggesting actions.
- Sectors: software.
- Tools/Products/Workflows: Repo/world-state adapters, build/test verifiers, “hallucination firewall” for unsafe edits.
- Assumptions/Dependencies: Accurate project context ingestion, CI integration.
- Consumer fact-check overlays
- Description: Browser extensions that highlight supported/unsupported/unknown claims in AI answers by retrieving evidence under declared P.
- Sectors: daily life, education, media literacy.
- Tools/Products/Workflows: Lightweight claim extraction, web retrieval/evidence linking UI, user-selectable conflict policies.
- Assumptions/Dependencies: Public evidence availability; acceptable latency; UX for “unknown” without frustration.
- Chess-based and similar simulator evaluations for model QA
- Description: Use chess/Nethack/etc. as explicit W to stress-test claim-level consistency under controlled V/P; auto-generate instances for regression testing.
- Sectors: software QA, academia.
- Tools/Products/Workflows: Environment-backed test suites, synthetic instance generators, claim checkers tied to rules/engine APIs.
- Assumptions/Dependencies: Simulator APIs; mapping from outputs to atomic claims; coverage across difficulty/observability.
Long-Term Applications
These uses require further research, scaling, or ecosystem development to fully realize, but are directly suggested by the paper’s methodology and unifying lens.
- Standardized “world-model alignment” certifications
- Description: Industry-wide metrics for “hallucination rate under specified W/V/P/T,” used in regulatory filings, model cards, and procurement.
- Sectors: policy/regulation, enterprise software, healthcare, finance.
- Tools/Products/Workflows: ISO-style standards, third-party auditing frameworks, public leaderboards with policy-stratified scores.
- Assumptions/Dependencies: Consensus on definitions and metrics; accredited auditors; domain-specific W catalogs.
- Policy-aware training objectives and architectures
- Description: Train LLMs to internalize and follow declared conflict policies, separate world-modeling from planning/reward behaviors, and prefer abstention when T=unknown.
- Sectors: AI model development across industries.
- Tools/Products/Workflows: Multi-objective losses for claim truthfulness, uncertainty calibration, modular agents separating belief/planning components.
- Assumptions/Dependencies: Datasets labeled with W/V/P/T; robust uncertainty estimation; reliable abstention incentives.
- Dynamic W handling (knowledge updates and non-stationary worlds)
- Description: Systems that track and adapt to changing reference worlds during long-horizon interactions; maintain “versioned” W and temporal conflict policies.
- Sectors: news, healthcare guidelines, legal/regulatory changes, operations.
- Tools/Products/Workflows: World-state versioning, temporal conflict-policy engines, incremental knowledge updating with consistency checks.
- Assumptions/Dependencies: Streaming data pipelines; change detection; safe migration paths when facts flip.
- Large-scale environment-backed benchmark suites
- Description: “WorldBench” libraries covering many domains (games, enterprise logs, synthetic org workflows) with programmatic T and controllable V/P to study hallucinations at scale.
- Sectors: academia, model evaluation vendors, enterprise QA.
- Tools/Products/Workflows: Environment generators, document/query synthesizers, claim extraction standards, automated scoring.
- Assumptions/Dependencies: Open-source ecosystems; reproducible environment APIs; coverage of realistic tasks.
- Hallucination firewalls for agentic systems
- Description: Runtime gates that block actions when the agent’s stated world conflicts with W; enforce “evidence-first” behavior before effecting changes.
- Sectors: software automation, robotics, industrial control, fintech ops.
- Tools/Products/Workflows: Action gating policies, safety monitors, rollback/containment routines tied to truth checks.
- Assumptions/Dependencies: Low-latency verifiers; robust sensor/state fidelity; clear escalation paths.
- Multimodal world-model arbitration in embodied AI
- Description: Formal conflict policies across sensors (vision, audio, proprioception) to reduce perception-driven hallucinations; unified cross-modal truth functions.
- Sectors: robotics, autonomous systems, assistive devices.
- Tools/Products/Workflows: Sensor-priority schemas, cross-modal entailment modules, simulation-to-reality transfer benchmarks.
- Assumptions/Dependencies: High-fidelity sensor fusion; domain-specific verifiers; safety cases.
- Evidence-first LLM products with provenance guarantees
- Description: Tools that only emit claims with attached evidence and explicit truth status; “unknown-first” UX for responsible AI answers.
- Sectors: healthcare, law, finance, government services, education.
- Tools/Products/Workflows: Provenance tracking, citation scoring, selective generation conditioned on T, evidence-aware UI components.
- Assumptions/Dependencies: User acceptance of more conservative outputs; mature evidence infrastructures.
- Research tools for science and data-centric domains
- Description: Systems that generate hypotheses with claim-level validation against lab data or literature W, track unknowns, and plan evidence acquisition.
- Sectors: scientific research, pharmaceuticals, engineering.
- Tools/Products/Workflows: Lab-data truth functions, literature KBs with conflict policies, experiment planning integrated with uncertainty.
- Assumptions/Dependencies: Structured scientific KBs; data access; robust mapping from text to atomic scientific claims.
- Educational platforms teaching world-model reasoning
- Description: Curriculum and interactive environments (chess, coding, simulated labs) that train students to specify W/V/P and reason about unknowns/contradictions.
- Sectors: education.
- Tools/Products/Workflows: Instructor dashboards, “policy-aware assignments,” automated feedback on claim consistency.
- Assumptions/Dependencies: Accessible simulators; pedagogical content; assessment alignment.
- Regulatory frameworks mandating W/V/P disclosure and evaluation
- Description: Policies requiring AI providers to disclose reference worlds and conflict policies and to report model behavior under those conditions; used in risk assessments.
- Sectors: public policy, procurement, safety-critical industries.
- Tools/Products/Workflows: Compliance reporting standards, enforcement audits, sector-specific W catalogs (e.g., clinical guidelines, regulatory codes).
- Assumptions/Dependencies: Legislative momentum; workable enforcement; sector consensus on authoritative sources.
Glossary
- Agentic hallucinations: Hallucinations arising in multi-step agent settings where actions contradict instructions, history, or observations. "MIRAGE-Bench proposes a three-part taxonomy of agentic hallucinations: actions that are unfaithful to (i) task instructions, (ii) execution history, or (iii) environment observations."
- Atomic claims: Smallest explicit assertions in an output that can be individually judged true/false/unknown. "Let C(y) denote the set of atomic claims expressed in y (e.g., factual assertions about entities, events, or states of the world) that are observable to the user."
- Atomic units: Minimal verifiable factual statements extracted from a response for checking. "which decompose model responses into meaningful atomic units - i.e., the smallest independently verifiable factual statements -"
- BALROG: A collection of challenging simulated environments for evaluation. "Crafter in the BALROG collection \citep{paglieri2024benchmarking}"
- Claim-extraction model: A model used to split free-form outputs into atomic claims for evaluation. "we can use a lightweight claim-extraction model to decompose y into atomic claims C(y)"
- Conflict resolution policy: A specified rule for reconciling conflicting sources of information. "a conflict resolution policy P that specifies how to reconcile multiple sources of information within V(W,x) (e.g., ``KB overrides in-context text''), and"
- Deterministic snapshot decision points: Fixed environment states used to evaluate agent actions consistently. "They construct deterministic ``snapshot'' decision points and use an LLM-as-a-judge framework to label actions as faithful or unfaithful."
- DOM (Document Object Model): Structured representation of a webpage used as ground-truth in browser tasks. "The DOM is ground truth; instructions cannot override reality."
- Entailment classifier: A tool/model that determines whether a claim is entailed by evidence. "or LLM-based entailment classifiers."
- Extrinsic hallucinations: Statements not contradicted by the source but not verifiable from it. "intrinsic hallucinations are those that directly contradict the source, while extrinsic hallucinations are statements that cannot be verified from the source but are not necessarily false."
- FAVA: A retrieval-augmented detector/editor model for fine-grained hallucination correction. "The associated FAVA model is trained as a retrieval-augmented detector and editor for these fine-grained hallucinations."
- FavaBench: A benchmark with span-level annotations and a detailed hallucination taxonomy. "FavaBench~\citep{mishra2024fine} introduces a detailed taxonomy of hallucination types (entity errors, relation errors, unverifiable statements, among others), and a benchmark of span-level human annotations over model outputs in information-seeking scenarios."
- FRANK: A taxonomy/tool distinguishing multiple factual error types in summarization. "More fine-grained typologies, such as FRANK~\citep{pagnoni2021understanding}, distinguish multiple error types (entity swaps, incorrect numbers, wrongly attributed facts, etc.)"
- HALoGEN: A benchmark measuring hallucinations across diverse knowledge-oriented domains. "HALoGEN ~\citep{ravichander2025halogen} introduces a benchmark to measure hallucinations in LLMs across 9 knowledge-oriented domains such as programming, scientific attribution, summarization, numerical reasoning, and false-presupposition."
- HallusionBench: A framework recasting multimodal hallucinations as knowledge conflicts between priors and context. "HallusionBench~\citep{guan2024hallusionbench}, which reframed the hallucination as a Knowledge Conflict between the model's powerful parametric priors (language memory) and its contextual understanding (visual input)."
- Intrinsic hallucinations: Statements that directly contradict the provided source. "intrinsic hallucinations are those that directly contradict the source, while extrinsic hallucinations are statements that cannot be verified from the source but are not necessarily false."
- KB (Knowledge base): An external structured repository of facts used as a source of truth. "(e.g., ``KB overrides in-context text'')"
- Knowledge Conflict: A mismatch between internal priors and contextual evidence leading to failure. "Knowledge Conflict between the model's powerful parametric priors (language memory) and its contextual understanding (visual input)."
- Knowledge conflict policy: The rule specifying which source (e.g., KB vs. context) takes precedence when facts disagree. "By varying the reference world model as well as the knowledge conflict policy (e.g., knowledge base vs. in-context), we arrive at the different existing definitions of hallucination present in the literature."
- Language Hallucination: A failure mode where parametric language priors override non-linguistic evidence. "Language Hallucination, where strong priors override visual evidence"
- LLM-as-a-judge: A setup where an LLM labels outputs/actions for faithfulness or correctness. "use an LLM-as-a-judge framework to label actions as faithful or unfaithful."
- Parametric knowledge: Information stored implicitly in model parameters rather than provided in-context. "Retrieved documents override parametric knowledge."
- Parametric priors: The model’s learned internal biases or expectations derived from training data. "parametric priors (language memory)"
- PGN (Portable Game Notation): A standard textual format for recording chess games. "a move log in a standard notation such as PGN."
- Reference world model: The formal gold-standard representation of truth for a task/environment. "A reference world model is a tuple W = (\mathcal{S}, \mathcal{H}, \mathcal{R}),"
- Retrieval-Augmented Generation (RAG): Generation paradigm that incorporates retrieved evidence to ground outputs. "Notably, this parallels the distinction in RAG settings between prioritizing the retrieved context and parametric knowledge as sources of truth."
- Truth function: A mapping that labels an atomic claim as true, false, or unknown under a given world and policy. "a truth function T_{W,P}(x, c) \in {\textnormal{true}, \textnormal{false}, \textnormal{unknown}}"
- View function: The mechanism that selects which portion of the world is visible/relevant for an input. "a view function V that selects the portion of the world that is relevant for x:"
- Visual Illusion: A VLM failure where perception misinterprets visual input despite available evidence. "Visual Illusion, where the perception module fails complex interpretation."
- World modeling: The model’s internal representation of environment states and dynamics used to produce outputs. "Hallucination as inaccurate (internal) world modeling"
Collections
Sign up for free to add this paper to one or more collections.