- The paper introduces an adaptive constraint-enhanced reward mechanism to decompose instructions for long-form generation.
- It employs Group Relative Policy Optimization (GRPO) to achieve up to 20.70% improvement over supervised fine-tuning methods.
- Human evaluations demonstrate that ACE-RL yields higher-quality and more coherent outputs than conventional RL baselines.
Introduction
The paper "ACE-RL: Adaptive Constraint-Enhanced Reward for Long-form Generation Reinforcement Learning" presents a framework aimed at enhancing the capabilities of LLMs in generating high-quality long-form content. Despite advancements in LLMs' understanding of extended contexts, generating coherent long-form outputs remains a challenge. The framework addresses key limitations in current methods by introducing a novel reward mechanism rooted in adaptive constraint criteria, which deconstructs instructions into fine-grained, verifiable components. This approach shifts the focus from coarse-grained optimization to precise, constraint-verified reinforcement learning.
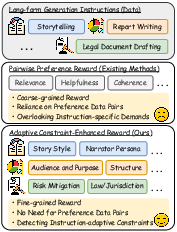
Figure 1: Comparison of reward mechanisms for long-form generation: conventional methods vs. our proposed method.
Methodology
The methodology of ACE-RL is centered around an automated pipeline that converts complex instructions into a constraint checklist. This list includes both explicit requirements and implicit expectations, providing a structured foundation for reward modeling. The reward mechanism contrasts conventional pairwise preference evaluations by scoring responses based on constraint satisfaction, transforming subjective assessment into objective verification tasks. The approach employs Group Relative Policy Optimization (GRPO) for training, removing additional value models to simplify computation and enhance efficiency.
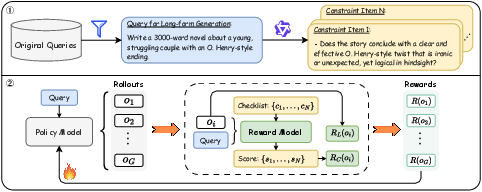
Figure 2: The overall framework of ACE-RL. First, we collect diverse instructions for long-form generation tasks and create an instruction-adaptive constraint checklist for each. Second, a reward model is deployed to verify whether the policy model's responses meet each constraint. This constraint-enhanced reward, along with a length reward, are then used for RL training.
Experimental Results
ACE-RL significantly surpasses existing baselines, including both supervised fine-tuning (SFT) and reinforcement learning using pairwise preference rewards. Its effectiveness is validated through extensive benchmarks, showing an average improvement of 20.70% over SFT methods and 7.32% over RL baselines on WritingBench. Additionally, the framework achieves a notable competitive edge over proprietary systems, with one model outperforming GPT-4o by 7.10%. These results underline the superiority of the constraint-verified reward mechanism in aligning LLMs with task-specific demands in diverse long-form generation scenarios.
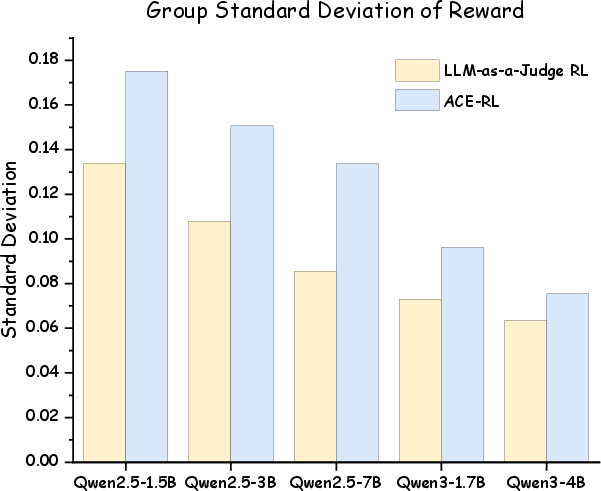
Figure 3: The comparison of the average group standard deviation of reward value.
Human Evaluation
Human evaluation further confirms the effectiveness of ACE-RL, demonstrating a higher preference rate compared to traditional methods. The alignment of responses with detailed constraint checklists enhances both the perceived quality and adherence to user expectations, establishing the framework as a robust solution for refining long-form AI-generated content.
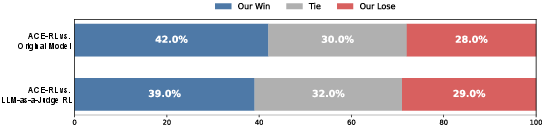
Figure 4: Human preference evaluation between our ACE-RL method and different baselines.
Conclusion
The ACE-RL framework represents an evolution in long-form generation training paradigms, leveraging constraint verification to transcend the limitations of coarse-grained evaluation. By focusing on detailed, instruction-specific rewards, it offers a pathway to more efficient, scalable reinforcement learning for LLMs, facilitating high-quality content creation across varied applications. The implications for AI development are profound, suggesting that detailed constraints can guide models toward enhanced capabilities without dependence on extensive preference datasets. Future work may explore integrating this approach into broader AI task domains, potentially revolutionizing reinforcement learning applications by emphasizing instruction-adaptive verifiability.