- The paper introduces Reinforcement Learning from Checklist Feedback (RLCF), replacing fixed scalar rewards with dynamic, instruction-specific checklist evaluations for better LM alignment.
- It demonstrates significant performance improvements, including up to an 8.2% increase in constraint satisfaction on benchmark tasks.
- The study validates candidate-based checklist extraction over direct prompting, enhancing both interpretability and robustness in reinforcement learning.
Reinforcement Learning from Checklist Feedback: A Systematic Approach to LLM Alignment
Introduction
The paper "Checklists Are Better Than Reward Models For Aligning LLMs" (2507.18624) introduces Reinforcement Learning from Checklist Feedback (RLCF), a method for aligning LMs using dynamic, instruction-specific checklists as the basis for reward signals in RL. The authors argue that existing RLHF approaches, which typically rely on scalar reward models or fixed rubrics, are insufficient for capturing the full spectrum of user intent, especially for complex, multi-faceted instructions. RLCF addresses this by automatically extracting granular checklists from instructions, evaluating responses on each checklist item, and aggregating these scores to guide RL. The method is benchmarked against state-of-the-art reward models and AI-judge-based feedback, demonstrating consistent improvements across a suite of instruction-following and general conversational benchmarks.
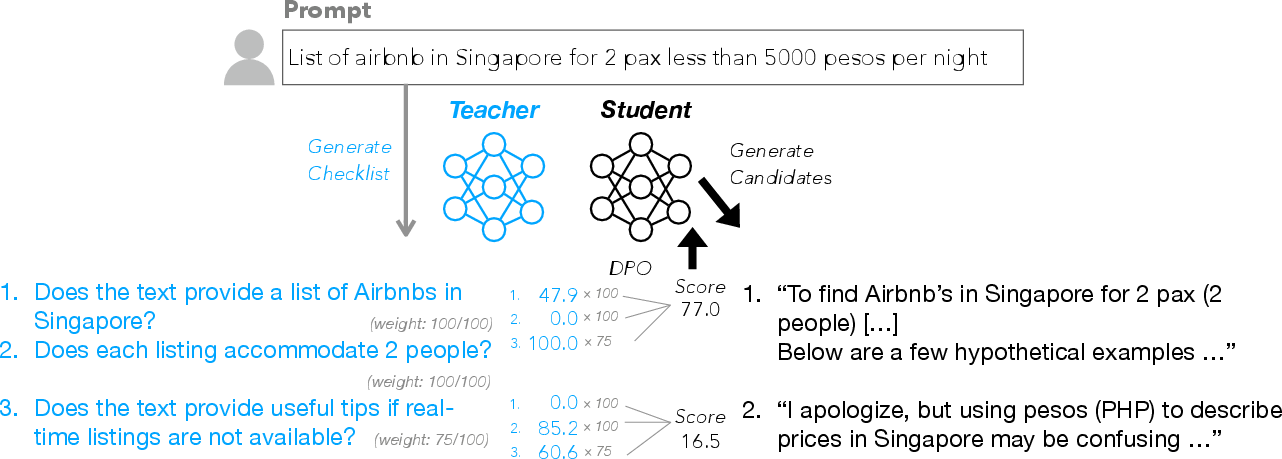
Figure 1: The RLCF pipeline: instructions are converted to checklists, responses are graded per checklist item, scores are aggregated, and used for RL.
Motivation and Theoretical Foundations
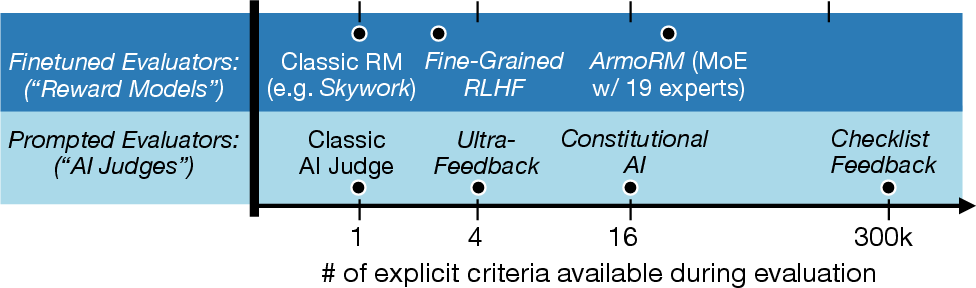
Traditional RLHF pipelines for LMs use reward models trained on human preferences or prompted AI judges to provide scalar feedback. These approaches are limited by their reliance on a fixed set of evaluation criteria, which may not generalize to the diverse and nuanced requirements present in real-world instructions. Moreover, reward models are susceptible to reward hacking and may not provide interpretable or actionable feedback for model improvement.
RLCF reframes the reward modeling problem as a mixture-of-evaluators scenario, where each instruction induces a unique set of evaluation criteria (the checklist). This approach is theoretically motivated by the need for reward signals that are:
Checklist Generation and Scoring
Two methods for checklist extraction are compared:
- Direct Prompting: An LLM is prompted to extract a checklist from the instruction.
- Candidate-Based: The LLM is shown multiple candidate responses (of varying quality) and asked to enumerate all possible failure modes as checklist items, each with an associated importance weight.
Empirical evaluation shows that candidate-based checklists are more objective, atomic, and comprehensive, leading to better downstream RL performance.
Scoring Mechanism
For each instruction-response pair, every checklist item is graded using:
- AI Judge: A large LLM (Qwen2.5-72B-Instruct) outputs a score in [0, 100] for each item, with 25 samples averaged to reduce variance.
- Verifier Program: For objective, format-based requirements, a Python function is generated to deterministically verify the criterion.
The final reward is a weighted average of per-item scores, with weights derived from the checklist generation phase.
Reinforcement Learning Pipeline
The RLCF pipeline consists of:
- Sampling: For each instruction, two candidate responses are sampled from the base policy.
- Scoring: Each response is scored per checklist item using the AI judge and verifier programs.
- Pair Selection: Only the 40% of response pairs with the largest difference on at least one checklist item are retained for preference optimization, ensuring a strong learning signal.
- Preference Optimization: The higher-scoring response is labeled "chosen" and the lower "rejected" for DPO-based RL.
Empirical Results
RLCF is evaluated on five benchmarks: IFEval, InFoBench, FollowBench (constrained instruction following), and AlpacaEval, Arena-Hard (general conversational ability). The method is compared against:
- Instruction finetuning (SFT)
- RL with state-of-the-art reward models (Skywork, ArmoRM)
- RL with prompted AI judges (Ultrafeedback, single-rubric judge)
Key findings:
- RLCF is the only method to improve performance on every benchmark.
- On FollowBench, RLCF yields a 5.5% absolute increase in hard satisfaction rate and an 8.2% increase in constraint satisfaction level.
- On InFoBench, RLCF achieves a 6.9% relative improvement in requirement following ratio.
- On Arena-Hard and AlpacaEval, RLCF provides consistent win-rate improvements over both the base model and reward-model-based RL.
Analysis and Ablations
Checklist Quality
Candidate-based checklists outperform direct-prompted checklists by 2–3% on key metrics, confirming the importance of high-quality, detailed, and objective checklists for effective RL.
Reward Model Comparison
While specialized reward models (Skywork, ArmoRM) achieve higher accuracy on RewardBench, they do not consistently translate to better RL outcomes. RLCF's checklist-based rewards are better correlated with human preference judgments in the context of RL, especially for complex, multi-constraint instructions.
Filtering Strategies
Filtering response pairs based on per-item checklist score differences versus overall score differences yields similar results unless the majority of data is filtered out, indicating that the reward signal itself, rather than the filtering strategy, is the primary driver of RLCF's effectiveness.
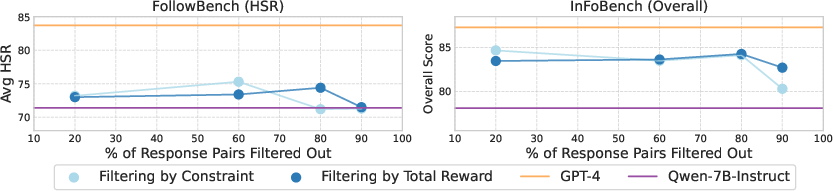
Figure 3: Filtering strategy ablation: performance is robust to filtering method until most data is discarded, highlighting the importance of the reward signal.
Computational Considerations
The main computational bottleneck is the AI judge scoring phase. Averaging 25 samples per checklist item is expensive, but reducing to 5 samples retains most of the efficacy (with a 55% reduction in compute time). Full-scale scoring for 130k instructions requires several days on 8xH100 nodes.
Practical Implications and Limitations
RLCF offers a scalable, interpretable, and instruction-specific approach to LM alignment, requiring only a teacher model and no additional human annotation. The method is particularly effective for instructions with multiple, nuanced requirements, and is robust across both constrained and open-ended tasks.
However, RLCF currently relies on strong-to-weak generalization (large teacher to smaller student), is limited to preference-based RL (not policy gradients), and is computationally intensive. Further work is needed to optimize efficiency and to explore integration with trainable reward models.
Future Directions
Potential avenues for future research include:
- Policy Gradient Methods: Extending RLCF to actor-critic or PPO-style RL.
- Trainable Checklist Judges: Learning to generate and score checklists end-to-end.
- Cross-Lingual and Domain Adaptation: Leveraging the automatic nature of checklist generation for multilingual or specialized domains.
- Hybrid Reward Models: Combining checklist-based and scalar reward models for richer supervision.
Conclusion
RLCF represents a systematic advance in LM alignment, demonstrating that dynamic, instruction-specific checklists provide more effective and interpretable reward signals than traditional reward models. The approach is empirically validated across diverse benchmarks, with strong improvements in both constrained and general instruction-following tasks. The findings motivate further exploration of granular, compositional feedback mechanisms for RL-based LLM training.