- The paper presents a closed-loop system where a single LLM acts as Actor, Judge, and Meta-Judge to continuously improve crypto predictions.
- It leverages multimodal data inputs and a multi-objective reward design to enhance trading strategies across various market regimes.
- Empirical results demonstrate superior performance, particularly in bearish conditions, outperforming state-of-the-art models on key metrics.
The paper "Meta-Learning Reinforcement Learning for Crypto-Return Prediction" presents the Meta-RL-Crypto framework—a novel approach for predicting cryptocurrency returns by integrating meta-learning with reinforcement learning (RL). This framework introduces a unique closed-loop system where a single LLM operates as an Actor, Judge, and Meta-Judge to continuously self-improve without human supervision. The system is designed to address challenges in cryptocurrency prediction driven by dynamic on-chain data, news, and social sentiment, utilizing a multi-objective reward design to enhance trading strategies.
The Meta-RL-Crypto system employs a transformer-based architecture that cyclically performs the roles of Actor, Judge, and Meta-Judge. The Actor processes market signals from a multimodal input comprising on-chain metrics, news reports, and sentiment scores to generate cryptocurrency forecasts. Each forecast is evaluated by the Judge using a multi-dimensional reward vector, which includes metrics such as absolute returns, the Sharpe ratio, and sentiment alignment. The Meta-Judge refines these evaluations, ensuring preference consistency and preventing reward drift.
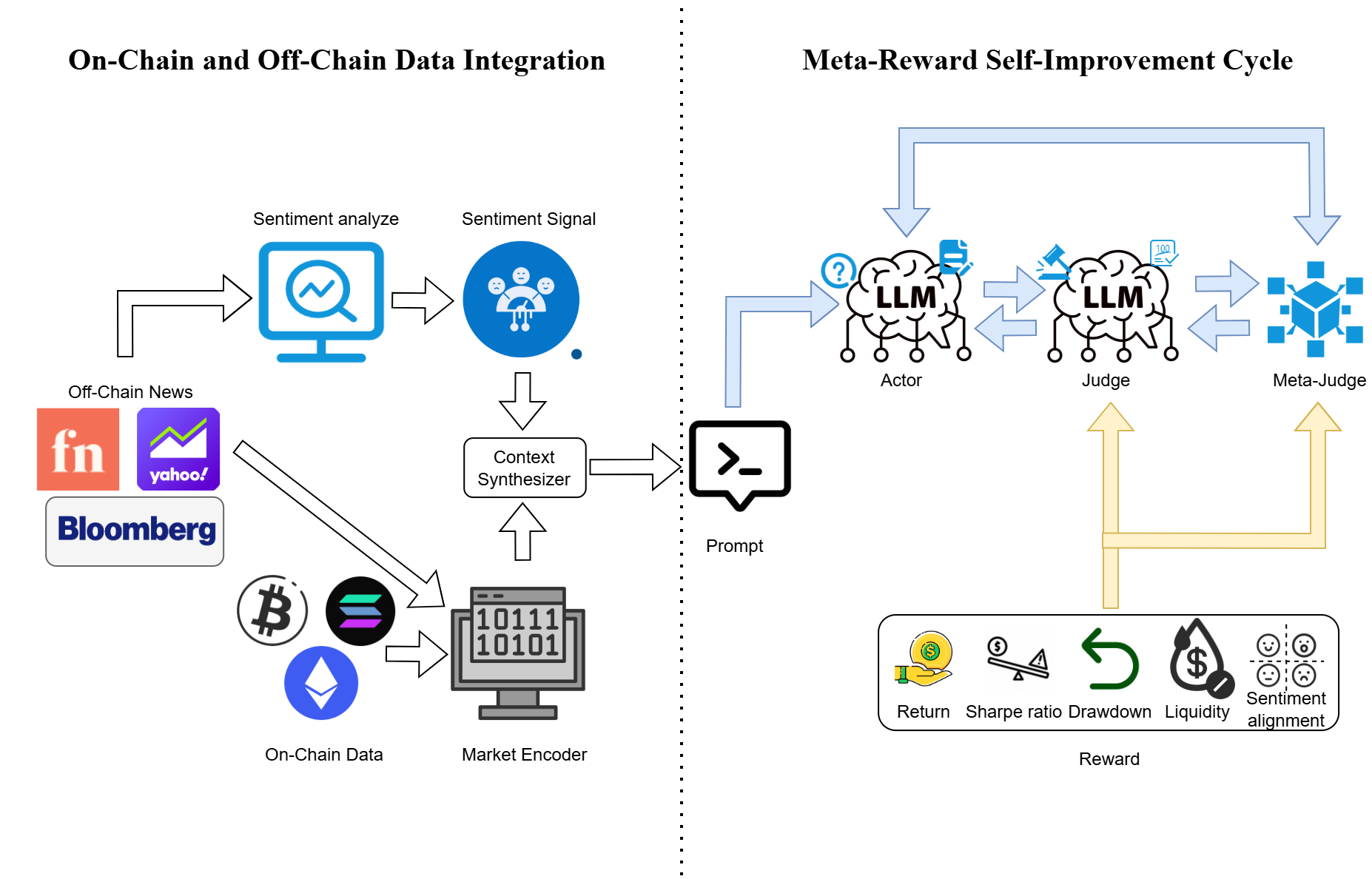
Figure 1: Overall Architecture of Meta-RL-Crypto, demonstrating the cyclical roles of Actor, Judge, and Meta-Judge in a closed-loop system.
Data Collection and Reward Framework
Data Collection
The system integrates both on-chain and off-chain data sources to capture cryptocurrency market dynamics. On-chain metrics are sourced from platforms like CoinMarketCap and Dune Analytics, providing transaction data, active wallet counts, and network congestion indicators. Off-chain data is retrieved from the GNews API, focusing on high-credibility financial reports, which are sentiment-scored using a sentiment-aware LLM (Sentilm).
Reward Construction and Aggregation
The framework constructs multiple reward channels to evaluate financial performance, risk, market impact, and sentiment utilization. These include Return-Based Reward, Risk-Adjusted Reward, Drawdown Reward, Liquidity Reward, and Sentiment Alignment Reward. Aggregation of these signals is managed by the Meta-Judge, which employs Generalized Preference-based Reinforcement Optimization (GPRO) to optimize the Actor and Judge roles via a closed feedback loop, employing a preference-based learning strategy for robust policy development.
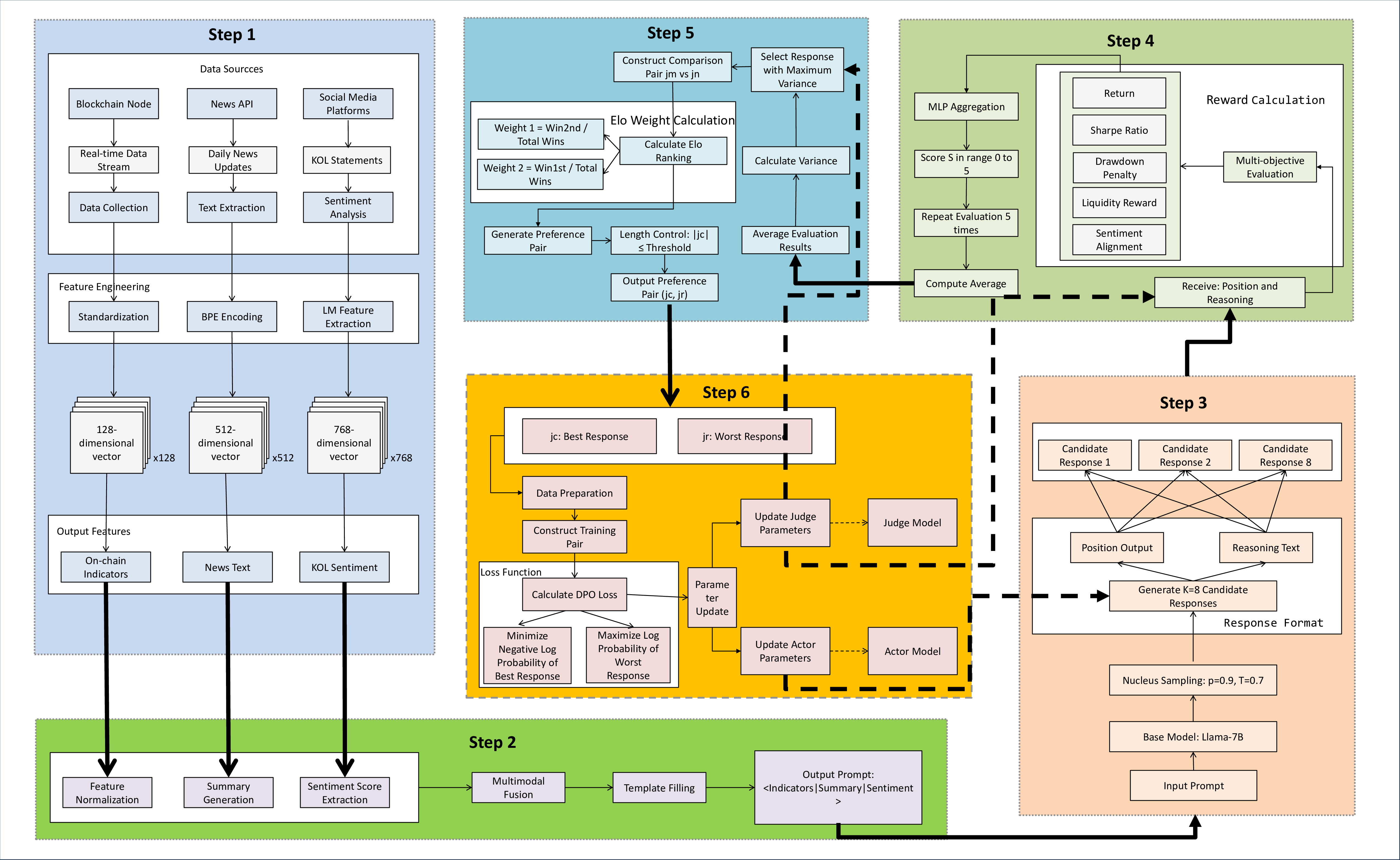
Figure 2: Meta-RL-Crypto Architecture detailing the data processing cycle and role-specific contributions to model performance improvement.
Empirical Evaluation
Experiment Settings
The evaluation of Meta-RL-Crypto employs a real-market dataset for cryptocurrencies BTC, ETH, and SOL, across distinct market regimes: bearish, sideways, and bullish. The experimental setup features a $1,000,000 starting portfolio with dynamical rebalancing based on the Actor's position signals, assessing total return, Sharpe ratio, and daily return mean.
As shown in the comparative analysis, Meta-RL-Crypto outperforms state-of-the-art models, especially in bearish market conditions, achieving a superior Sharpe ratio and total return across all tested regimes. Additionally, the model's interpretability scores, evaluated on metrics like Market Relevance, Risk-Awareness, and Adaptive Rationale, outperform other models, including GPT-4, highlighting its capability to adapt and reason over volatile market scenarios effectively.
Conclusion
The Meta-RL-Crypto framework offers a robust self-improving system for cryptocurrency return prediction, integrating on-chain and off-chain data with an innovative reinforcement learning approach within a multi-objective reward design. The model effectively manages market complexity without the need for human-labeled data, demonstrating high adaptability and performance across dynamic market environments. Future research can explore extending this framework to other financial markets or integrating additional types of market signals to further enhance prediction accuracy and model robustness.