RGB-Only Supervised Camera Parameter Optimization in Dynamic Scenes
Abstract: Although COLMAP has long remained the predominant method for camera parameter optimization in static scenes, it is constrained by its lengthy runtime and reliance on ground truth (GT) motion masks for application to dynamic scenes. Many efforts attempted to improve it by incorporating more priors as supervision such as GT focal length, motion masks, 3D point clouds, camera poses, and metric depth, which, however, are typically unavailable in casually captured RGB videos. In this paper, we propose a novel method for more accurate and efficient camera parameter optimization in dynamic scenes solely supervised by a single RGB video. Our method consists of three key components: (1) Patch-wise Tracking Filters, to establish robust and maximally sparse hinge-like relations across the RGB video. (2) Outlier-aware Joint Optimization, for efficient camera parameter optimization by adaptive down-weighting of moving outliers, without reliance on motion priors. (3) A Two-stage Optimization Strategy, to enhance stability and optimization speed by a trade-off between the Softplus limits and convex minima in losses. We visually and numerically evaluate our camera estimates. To further validate accuracy, we feed the camera estimates into a 4D reconstruction method and assess the resulting 3D scenes, and rendered 2D RGB and depth maps. We perform experiments on 4 real-world datasets (NeRF-DS, DAVIS, iPhone, and TUM-dynamics) and 1 synthetic dataset (MPI-Sintel), demonstrating that our method estimates camera parameters more efficiently and accurately with a single RGB video as the only supervision.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper is about teaching a computer to figure out how a camera moved while filming a video, using only the video itself (the RGB frames), even when things in the scene are moving. The “camera parameters” it learns are:
- where the camera was (position),
- which way it was facing (rotation), and
- how zoomed-in it was (focal length).
Knowing these helps build 3D models of the scene and lets us render new views that weren’t originally filmed.
The main goals and questions
The authors ask:
- Can we estimate camera motion and zoom accurately using just a normal video (no extra sensors, no depth, no special labels), even when the scene includes moving people, cars, or other objects?
- Can we do it faster than popular existing methods that can be slow or need extra information?
- Will better camera estimates improve 3D reconstructions and the quality of rendered images from new viewpoints?
How the method works (with easy analogies)
Think of trying to track stickers on objects in a video to see how the camera moved. If some stickers are on moving people, those confuse you. If some are blurry or on plain walls, they’re not reliable. The method has three big ideas to deal with this:
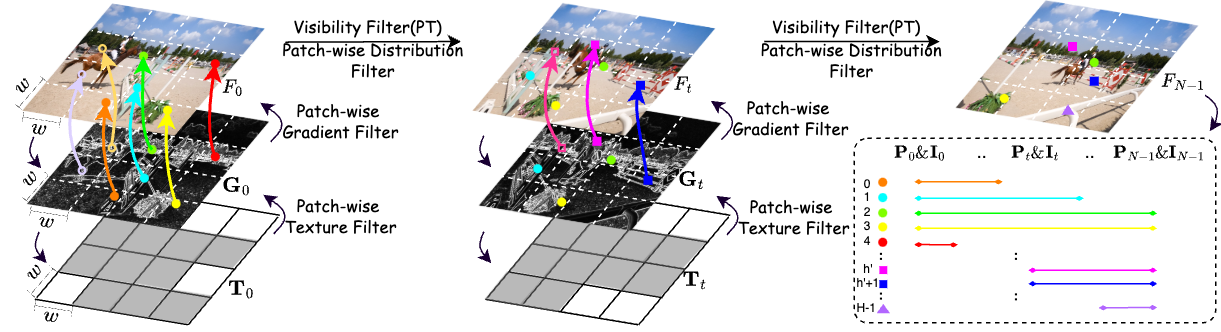
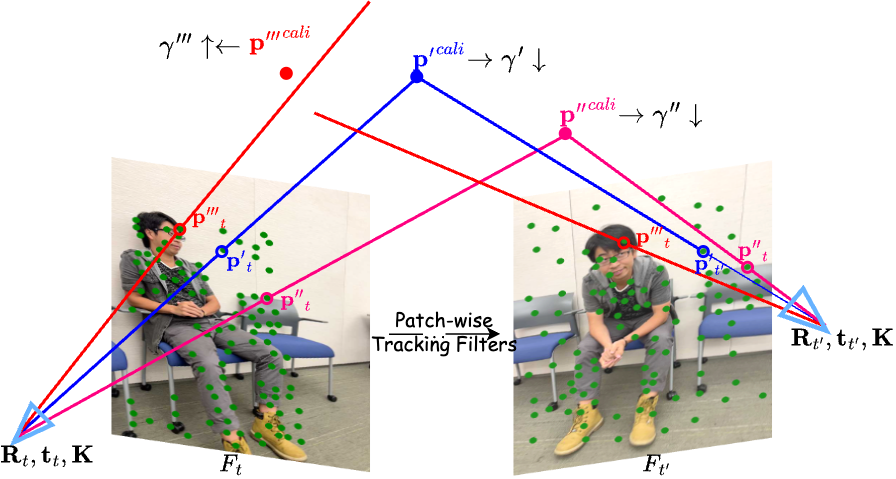
- Patch-wise tracking filters: picking the best stickers to follow
- The video frame is split into small squares (patches), like a chessboard.
- The method looks for textured, detailed spots (like corners or strong edges) in those patches because they’re easier to track reliably.
- It keeps at most one very strong, easy-to-see point per patch so points aren’t bunched up in one area.
- It throws away points when they disappear or reappear (which often makes tracking unreliable).
- Result: a small set of high-quality “dots” to follow across the video, making the supervision sparse but strong.
- Outlier-aware joint optimization: learning while ignoring troublemakers
- Some tracked points are on moving objects (like a walking person). These are “outliers” because they don’t reflect the camera’s motion.
- The method assigns each tracked 3D point a “trust meter” (called uncertainty). If a point acts weird compared to the camera’s guess, its uncertainty goes up, so it counts less in the learning process.
- This “trust meter” is modeled with a mathematical tool (the Cauchy distribution) that naturally down-weights big mistakes, which often come from moving objects.
- At the same time, it learns everything together: the 3D points, the camera’s position and rotation for each frame, and the focal length.
- Two-stage optimization: first get close, then fine-tune
- Stage 1: Get a quick, stable rough estimate of the camera without adjusting the “trust meters.”
- Stage 2: Use the rough result to initialize the uncertainty (trust) values wisely, then fine-tune everything together for stability and speed.
- A simple math trick (Softplus) keeps the uncertainties positive and smooth to optimize.
In short: pick a few great points to track, learn camera movement while down-weighting moving objects, and do it in two steps for speed and stability.
What they found and why it matters
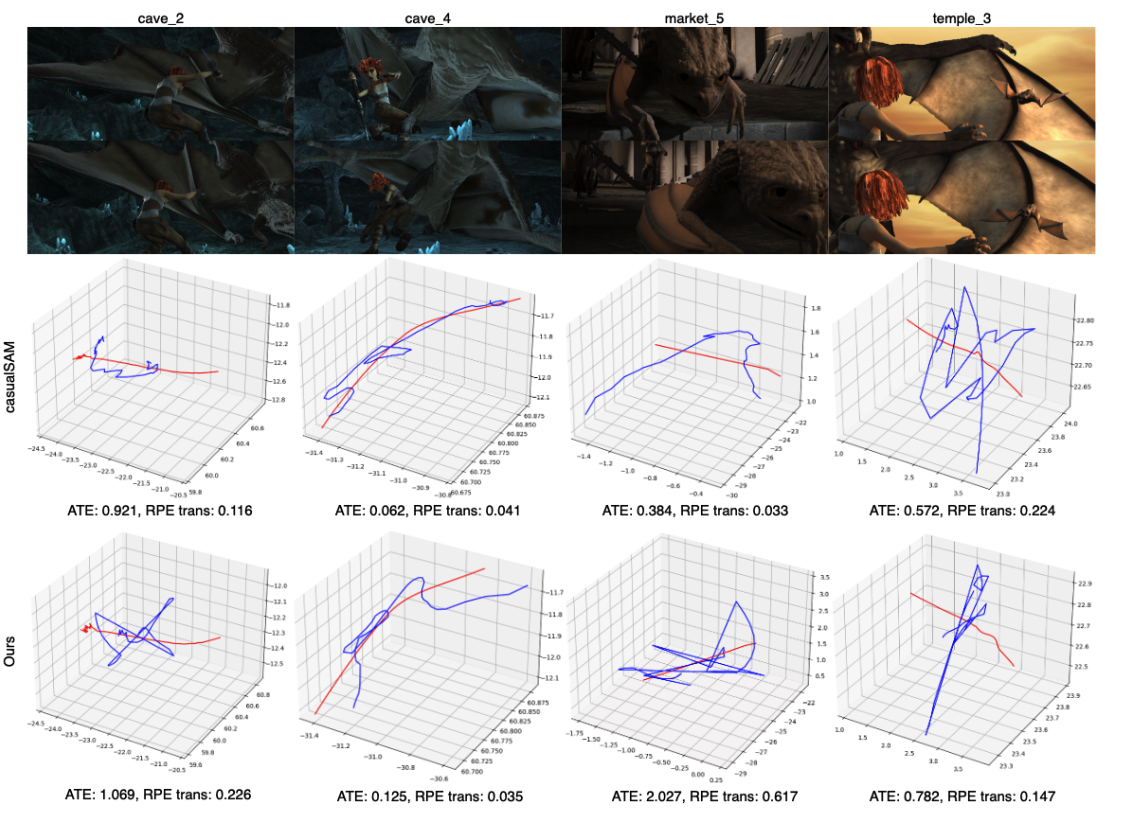
The authors tested on several real and synthetic video sets (like DAVIS, NeRF-DS, iPhone videos, TUM, and MPI-Sintel). Here’s what stood out:
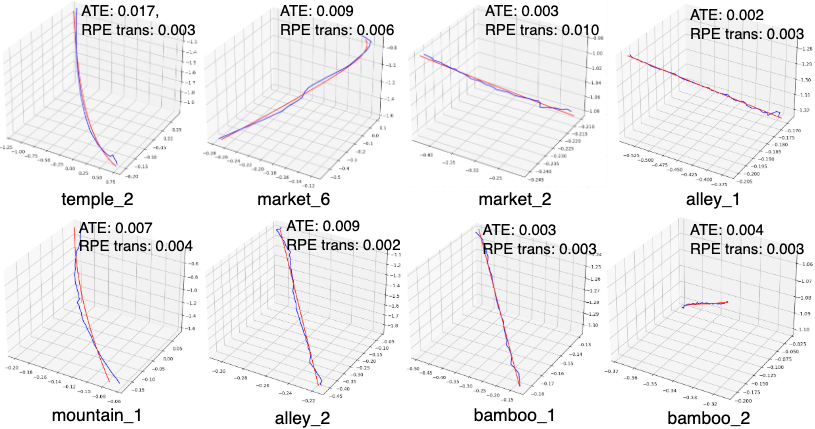
- More accurate camera paths: Their method often matched or beat other approaches, including some that need extra information like depth or motion masks.
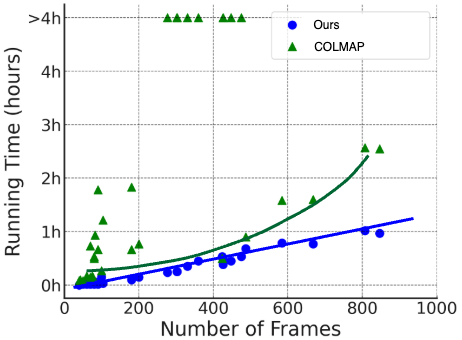
- Faster: As videos get longer, their runtime grows almost linearly (predictably), unlike some common methods that slow down a lot. They were often the fastest among RGB-only methods.
- Better 3D reconstructions and new views: When they fed their estimated camera parameters into a popular 4D (dynamic) scene renderer, the resulting images and depth maps looked sharper and more realistic. This shows the camera estimates were truly better, not just lucky numbers.
- Sometimes even beat LiDAR-based results: On some iPhone videos, their RGB-only approach produced reconstructions that were on par with or better than results based on LiDAR data provided by a mobile app.
Why this matters:
- It means you can take a normal video on a phone and, without special sensors or labels, recover the camera’s motion and build high-quality 3D scenes—even when the scene is full of motion.
What this could change in the future
- Easier 3D creation from everyday videos: People could build 3D/4D models or produce new, realistic viewpoints from casual phone videos without special equipment.
- Faster workflows: Filmmakers, game designers, and AR creators could get camera motion and 3D data more quickly and cheaply.
- More robust systems: Because the method doesn’t depend on many external, pre-trained components or extra sensors, it can be more reliable across a wide variety of scenes.
In short, the paper shows a practical and efficient way to recover camera motion from ordinary, dynamic videos, which can improve many applications in 3D graphics, virtual reality, and visual effects.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, phrased to guide actionable future research.
- Intrinsics modeling is limited to a single global focal length f; support for full intrinsics (fx, fy, principal point, skew) and lens distortion (radial/tangential) is not addressed.
- Dynamic intrinsics (e.g., zoom, autofocus-induced focal changes, rolling shutter effects) are not modeled; robustness under such camera behaviors is unknown.
- The pinhole, global-shutter assumption excludes fisheye/omnidirectional lenses and rolling-shutter sensors common in mobile devices; explicit modeling and evaluation are missing.
- Metric scale remains fundamentally ambiguous in monocular RGB-only settings; the method does not propose strategies for consistent or metric scale recovery (e.g., via size priors, IMU, or self-calibration cues).
- The approach uses a single per-track uncertainty parameter Γ; it cannot capture frame-varying reliability (occlusion, motion blur, illumination change) within the same track—per-frame (or anisotropic) uncertainties are unexplored.
- Tracks that become invisible at any time are discarded entirely; strategies for partial-track utilization, occlusion-aware likelihoods, or track re-identification are not explored.
- The method presumes sufficient static background to anchor motion; performance when dynamic objects dominate the field-of-view or backgrounds are non-rigid (e.g., foliage, water) is not systematically studied.
- Degenerate or near-degenerate motion cases (pure rotation, very low parallax, stationary camera, planar scenes) are not theoretically characterized; conditions for identifiability and failure detection are missing.
- Dependence on a pre-trained point tracker (CoTracker/CoTracker3) is a single point of failure; robustness when tracking degrades (heavy blur, low light, severe occlusions, specular/reflection surfaces) is underexplored.
- The “patch-wise tracking filters” rely on simple texture and gradient thresholds (τ_var, w, B) tuned per resolution; no automatic, adaptive selection or sensitivity analysis for these hyperparameters is provided.
- Enforcing at most one feature per patch may under-sample highly informative regions and over-sample weak regions; adaptive per-patch quotas or multi-scale selection is not investigated.
- The “hinge-like relations” are not formally defined or analyzed; there is no theoretical justification of sparsity conditions vs. pose observability or triangulation quality.
- The Average Cumulative Projection (ACP) error averages residuals across time; it does not explicitly weight by track length, per-frame confidence, or heteroscedastic noise—alternative weighting schemes are unexplored.
- Only the Cauchy loss is examined; comparisons with other robust M-estimators (Huber, Tukey, Geman–McClure), heavy-tail families (Student-t with learnable dof), or mixture models for outlier handling are missing.
- The two-stage optimization is heuristic (Stage 1: Γ fixed; Stage 2: Γ initialized to ACP error) without convergence guarantees or analysis of stability across initializations, scales, or sequence lengths.
- Units and normalization of residuals are not discussed (e.g., pixel residuals vs. image size); cross-resolution robustness and the effect of normalization on Γ learning are unclear.
- No temporal regularization on camera motion (e.g., smoothness priors on rotation/translation) is used; potential benefits for stability and jitter reduction are not evaluated.
- Principal point drift and pixel aspect ratio are assumed fixed; their estimation could matter for mobile cameras and are not investigated.
- The approach ignores epipolar geometry priors and essential/fundamental matrix constraints that could regularize early iterations; benefits and trade-offs remain unexplored.
- Removing entire tracks upon any invisibility may dramatically reduce constraints in highly occluded scenes; fallback strategies for constraint sufficiency are not proposed.
- Scalability is demonstrated up to ~900 frames; behavior on much longer sequences (several thousand frames), memory footprints, and incremental/streaming optimization are not evaluated.
- Loop-closure or global consistency mechanisms are absent; long-horizon drift and strategies to detect/correct it are not discussed.
- The method is tested on limited trackers; systematic cross-tracker evaluation (including failure-aware ensembles or confidence calibration from the tracker) is missing.
- Evaluation could be confounded by the reconstruction backend (4DGS); pose accuracy is not isolated on more dynamic-scene datasets with ground-truth (beyond TUM/MPI-Sintel), nor are re-projection residual distributions reported.
- Failure modes are only briefly alluded to; explicit qualitative/quantitative analyses of when and why the method fails (e.g., severe blur, ultra-low texture, dominant non-rigid motion) are absent.
- The positive-depth regularizer enforces sign but not metric fidelity; its interaction with scale, near-plane placement, and numerical stability is not analyzed.
- Per-axis (x/y) uncertainty in the image plane is not modeled; anisotropic residuals (e.g., motion blur along a direction) might be better handled with directional uncertainties.
- Integration of weak or opportunistic priors (e.g., inertial sensors, gravity direction, known object sizes) while retaining minimal supervision is not explored.
- Potential by-products such as motion segmentation or dynamic/static masks derived from learned uncertainties (Γ) are not investigated or validated.
- Multi-camera or multi-clip fusion (shared scene, differing viewpoints/times) is out of scope; extension to collaborative or distributed capture is unexplored.
- The choice of one-point-per-patch based on gradient magnitude might bias towards edges; evaluating alternative feature selection (e.g., cornerness, learned keypoint quality) is not conducted.
- Initialization strategies for poses, focal length, and 3D points are not detailed; sensitivity to poor initial guesses and robust initialization schemes remain open.
Glossary
- 3D Gaussian field: A 3D scene representation composed of Gaussian primitives depicting geometry/radiance. "Front view of the 3D Gaussian field reconstructed by our camera estimates at time ."
- 3D Gaussian Splatting (3DGS): A method that models scenes with 3D Gaussian primitives and rasterizes them efficiently for fast rendering and optimization. "Recently, 3DGS~\cite{3dgs} effectively addressed this issue by using 3D Gaussian-based representations and presented Differential-Gaussian-Rasterization in CUDA."
- 4D Gaussian Splatting (4DGS): An extension of Gaussian splatting to dynamic (time-varying) scenes enabling real-time novel view synthesis. "With the estimated camera parameters, we use 4DGS~\cite{4dgs} for scene reconstruction."
- 4D reconstruction: Reconstructing dynamic scenes over time (3D + temporal dimension). "we feed the camera estimates into a 4D reconstruction method"
- Absolute Trajectory Error (ATE): A metric measuring the deviation between estimated and ground-truth camera trajectories. "we directly evaluate methods by ATE, RPE trans, and RPE rot metrics."
- Adam optimizer: An adaptive stochastic optimization method commonly used to train deep models. "The optimization is conducted on 1 NVIDIA A100 40GB GPU with Adam~\cite{adam} optimizer"
- Average Cumulative Projection (ACP) error: A per-point average of cumulative reprojection errors across frames used to quantify 2D–3D alignment. "we replace the commonly used projection error ... with our proposed Average Cumulative Projection (ACP) error"
- Cauchy distribution: A heavy-tailed probability distribution used to robustly model uncertainty and down-weight outliers. "We model such uncertainty parameters with the Cauchy distribution"
- Cauchy loss: A negative-log-likelihood loss derived from the Cauchy distribution to attenuate outlier influence. "we propose the novel Average Cumulative Projection error and Cauchy loss"
- COLMAP: A popular structure-from-motion pipeline for camera parameter and sparse 3D reconstruction. "Although COLMAP has long remained the predominant method for camera parameter optimization in static scenes"
- CoTracker: A pre-trained point tracking model used to extract accurate sparse trajectories across frames. "We also choose to build our patch-wise tracking filters on CoTracker~\cite{cotracker}"
- Convex minima: Global minimizers of convex functions; here referencing the inner convex term of the loss to stabilize optimization. "a trade-off between the Softplus limits and convex minima in losses."
- CUDA: NVIDIA’s GPU computing platform used for high-performance differentiable rasterization. "presented Differential-Gaussian-Rasterization in CUDA."
- Depth regularization: A loss term encouraging positive (physically valid) depths during projection. "a depth regularization term to encourage positive depth."
- Differential-Gaussian-Rasterization: A differentiable rasterization technique for Gaussian primitives that enables gradient-based optimization. "presented Differential-Gaussian-Rasterization in CUDA."
- DROID-SLAM: A SLAM system leveraging learned optical flow and depth supervision for camera pose estimation. "The most representative SLAM-based method - DROID-SLAM~\cite{droidslam}"
- Ground Truth (GT): Reference annotations or measurements used as supervision. "reliance on ground truth (GT) motion masks"
- Hinge-like relations: Sparse relational constraints built from tracked patches to robustly link points across time. "to establish robust and maximally sparse hinge-like relations across the RGB video."
- Intrinsic: Camera intrinsic parameters (e.g., focal length, principal point) that define the internal geometry of the camera. "Record3D is a mobile app that factory-calibrates the intrinsic"
- LiDAR: Active sensing technology that measures distances via laser pulses to obtain metric depth. "uses LiDAR sensors to collect metric depth"
- LPIPS: A learned perceptual similarity metric for comparing image quality. "evaluate each NVS performance (PSNR, SSIM, and LPIPS)."
- Metric depth: Depth values measured in real-world units (e.g., meters). "uses LiDAR sensors to collect metric depth"
- NeRF (Neural Radiance Fields): An implicit neural representation that enables high-fidelity view synthesis from posed images. "NeRF~\cite{nerf} enables high-fidelity NVS."
- Novel View Synthesis (NVS): Rendering novel viewpoints of a scene from estimated geometry and appearance. "Dynamic Scene Reconstruction/Novel View Synthesis (NVS)."
- Orthogonality (rotation constraints): The property of rotation matrices (orthonormal columns and determinant ±1) required for valid rotations. "circumvents the difficult-to-enforce orthogonality and ± 1 determinant constraints required for rotation matrices during optimization."
- Parallax: Apparent displacement of scene points due to viewpoint change; low parallax implies limited baseline and is challenging for depth estimation. "performs better on low-parallax videos"
- Patch-wise tracking filters: A filtering pipeline selecting high-texture, high-gradient, well-distributed, and visible points for robust trajectory extraction. "Patch-wise Tracking Filters, to establish robust and maximally sparse hinge-like relations across the RGB video."
- Perspective projection matrix: The camera intrinsics matrix that maps 3D points to 2D image coordinates via perspective geometry. "The perspective projection matrix is derived from ,"
- Pinhole camera: An idealized camera model that projects 3D points onto an image plane through a single point. "we also assume a pinhole camera."
- Point Tracking (PT) model: A model that tracks the positions of points across frames to form trajectories used as pseudo-supervision. "Built on a pre-trained PT model"
- PSNR: Peak Signal-to-Noise Ratio, a fidelity metric comparing reconstructed images to references. "evaluate each NVS performance (PSNR, SSIM, and LPIPS)."
- Quaternion (matrix): A rotation parameterization using quaternions to avoid matrix orthogonality and determinant constraints during optimization. "Notably, we learn the quaternion matrix instead of optimizing the and additional constraints."
- ReLU: Rectified Linear Unit activation; here used to penalize negative depths. ""
- Relative Pose Error (RPE): Pose consistency metric computed over short intervals for translation (trans) and rotation (rot). "we directly evaluate methods by ATE, RPE trans, and RPE rot metrics."
- Simultaneous Localization and Mapping (SLAM): Joint estimation of camera trajectory and a map of the environment from sensor data. "The most representative SLAM-based method - DROID-SLAM~\cite{droidslam}"
- Softplus function: A smooth function ensuring positivity; used to parameterize uncertainty scales differentiably. "we analyze the asymptotic behavior of the Softplus function"
- Triangulation: Recovering 3D point positions from multiple 2D observations; sensitive to point distribution and resolution. "which might result in triangulation errors."
- Visual odometry: Estimating camera motion directly from video sequences. "Despite recent progress in visual odometry"
- World-to-camera transformation matrix: The extrinsic transformation (rotation and translation) mapping world coordinates into the camera frame. "the world-to-camera transformation matrix consists of rotation and translation ."
Collections
Sign up for free to add this paper to one or more collections.