- The paper presents a virtual camera system that reduces pose estimation dimensions from 6 to 4.
- It employs progressive training with 2D masks and sparse matches to incrementally refine object shape and pose.
- Results on the HO3D dataset show superior reconstruction quality and pose accuracy compared to traditional methods.
Free-Moving Object Reconstruction and Pose Estimation with Virtual Camera
The paper "Free-Moving Object Reconstruction and Pose Estimation with Virtual Camera" addresses the challenge of reconstructing free-moving objects from monocular RGB videos without relying on pose or object category priors. This approach significantly reduces optimization complexity through the use of a virtual camera system to simplify pose estimation.
Problem Statement
Most existing methods for object reconstruction assume specific conditions like static scenes or use hand-provided priors. In contrast, this paper tackles the free-moving object scenario, where objects can be manipulated freely in front of a moving camera. Traditional methods either rely on segment-wise optimization or assume specific priors that limit real-world applicability.
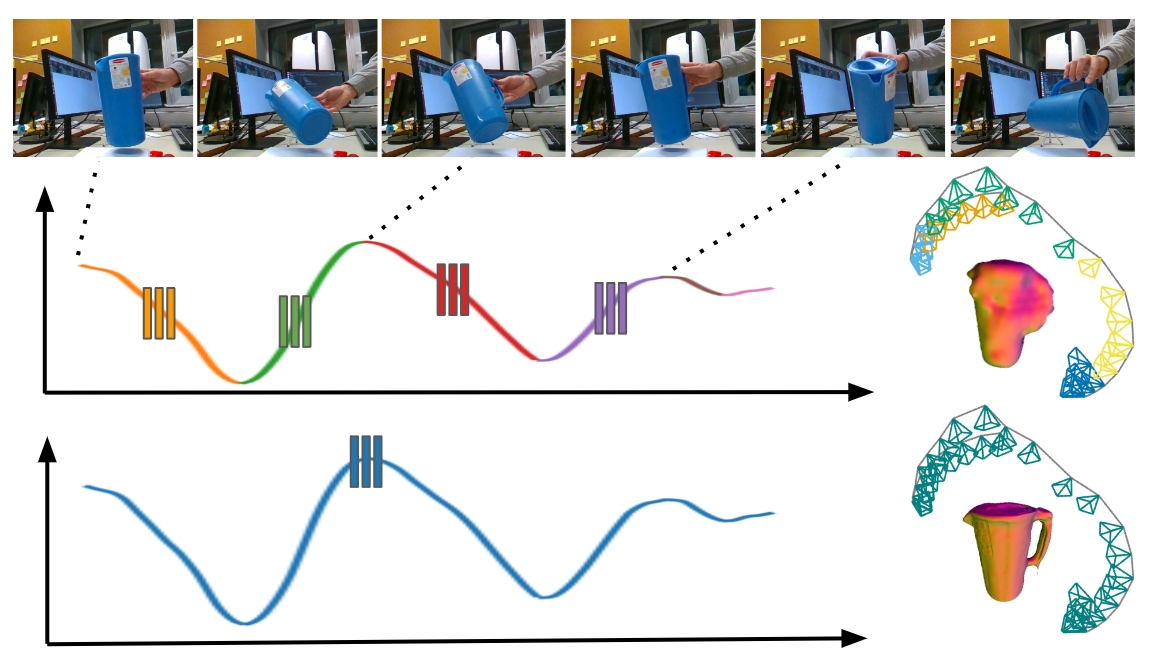
Figure 1: Paradigms of pose-free object reconstruction showcasing traditional segment-based optimization versus our global optimization approach.
Proposed Method
Virtual Camera System
The introduction of a virtual camera system is a key innovation in this paper. The virtual camera always points towards the object center, significantly reducing the search space for pose estimation from six degrees of freedom to four—rotation and distance. This simplification allows for more efficient optimization.


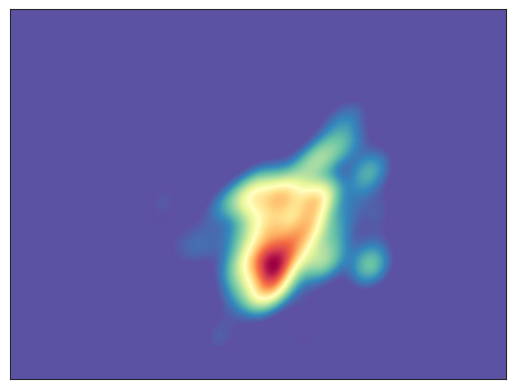

Figure 2: Effect of the virtual camera demonstrating simplified trajectories and reduced optimization complexity.
Progressive Training and Global Refinement
The paper proposes a progressive training strategy that sequentially optimizes pose trajectories and object shape. This process utilizes 2D object masks and sparse 2D matches to leverage temporal consistency effectively.
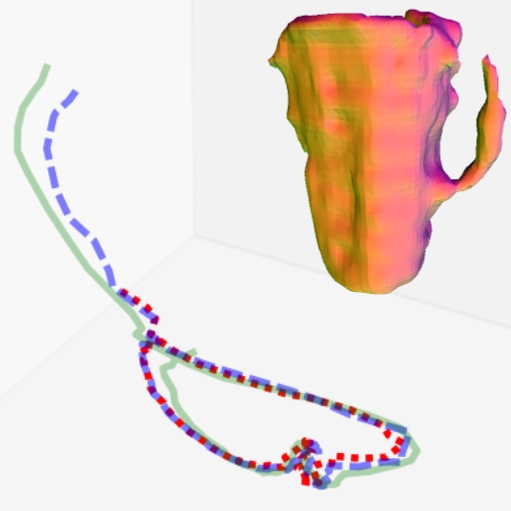
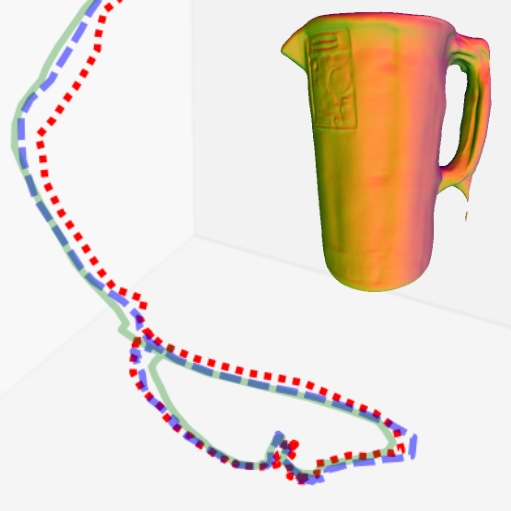
Figure 3: Progressive training shows improvements with incremental image addition and refinement.
After progressive optimization, a global refinement phase converts virtual camera poses back to real camera coordinates using a PnP solver, ensuring physically-compliant and accurate final results.
Results on HO3D Dataset
Evaluations on the HO3D dataset demonstrate the method's superiority over existing techniques without the need for segmented data or hand priors. Our approach yields significantly better positing and reconstruction results compared to prior methods like COLMAP and recent RGB-based methods.

















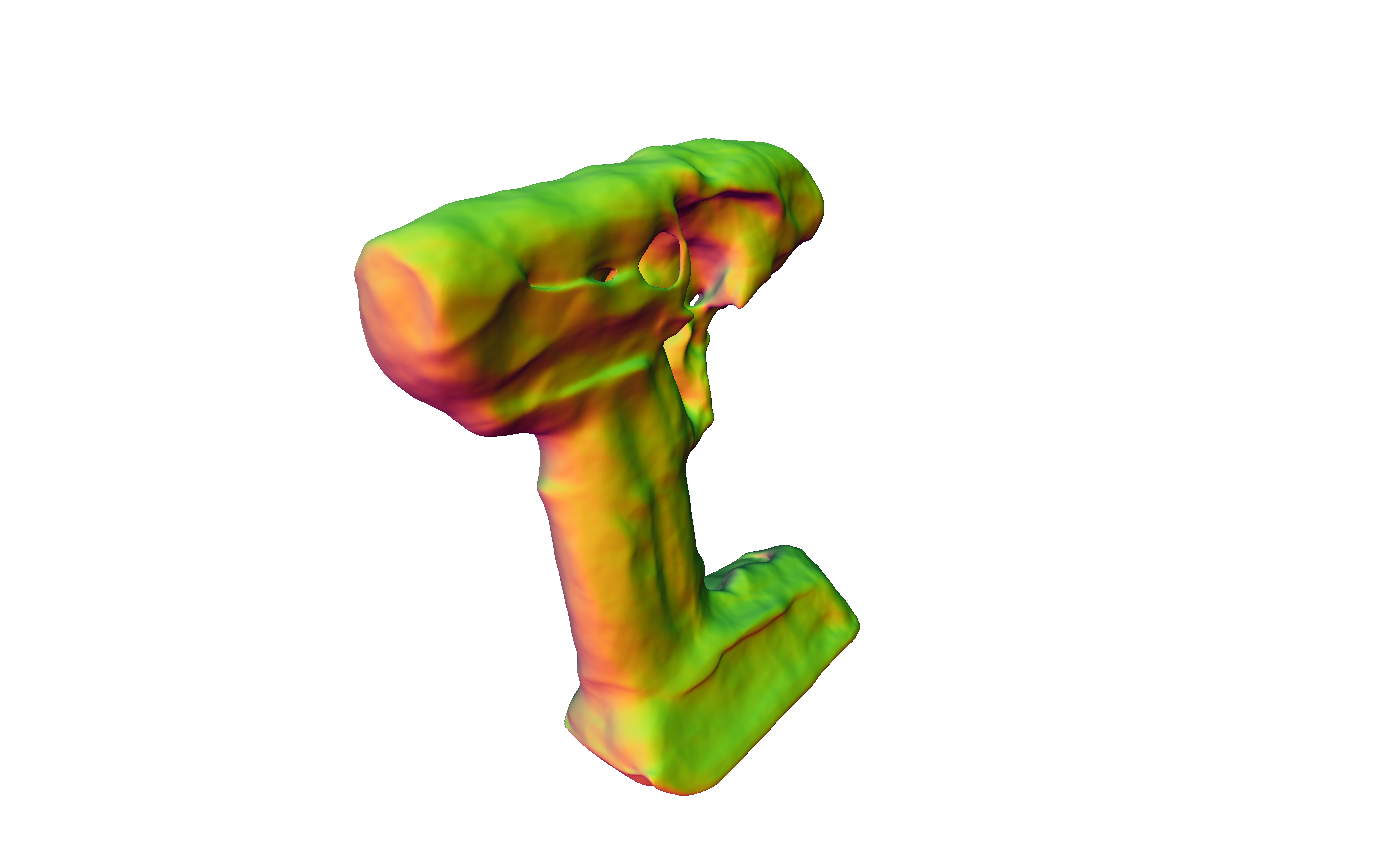
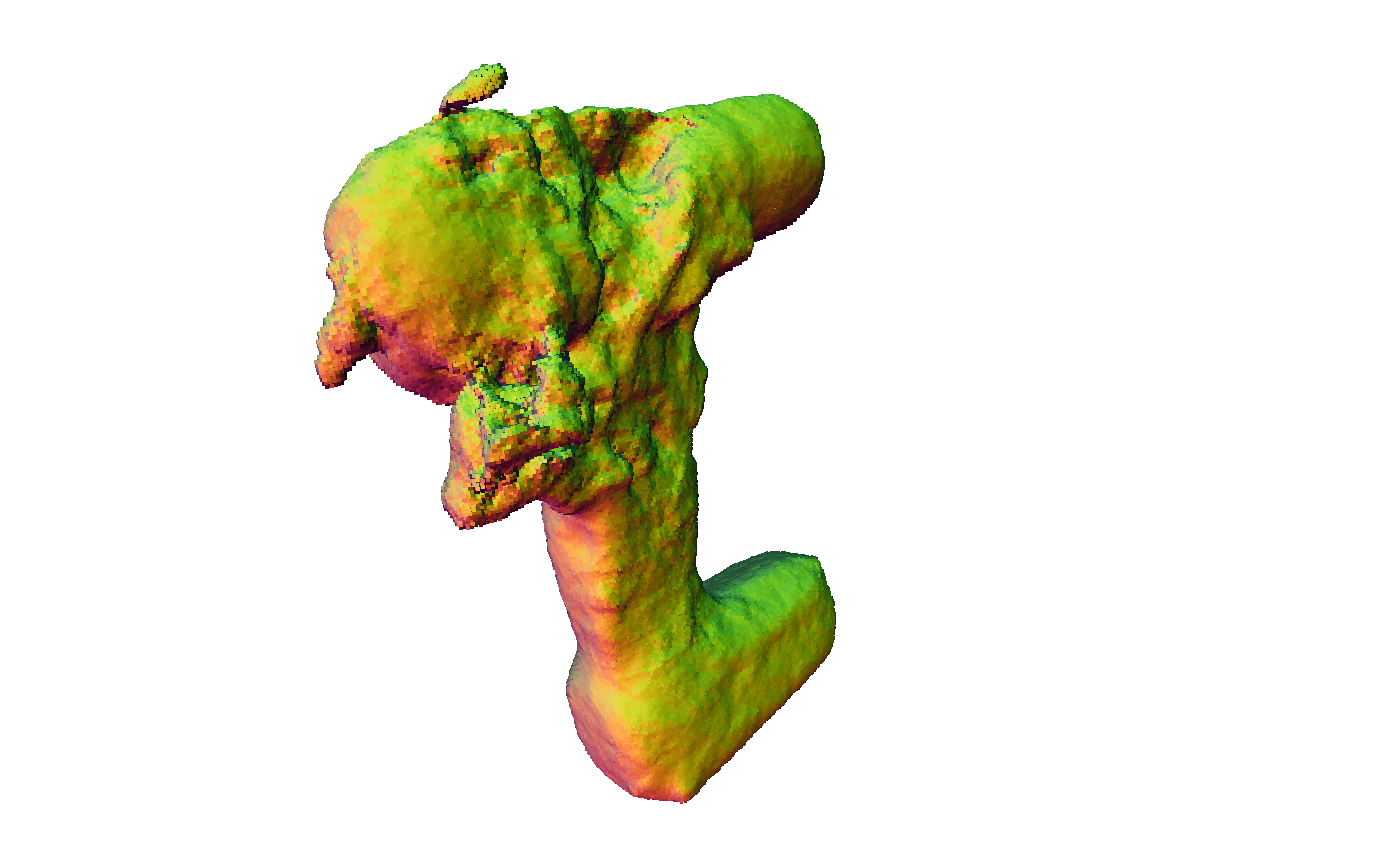
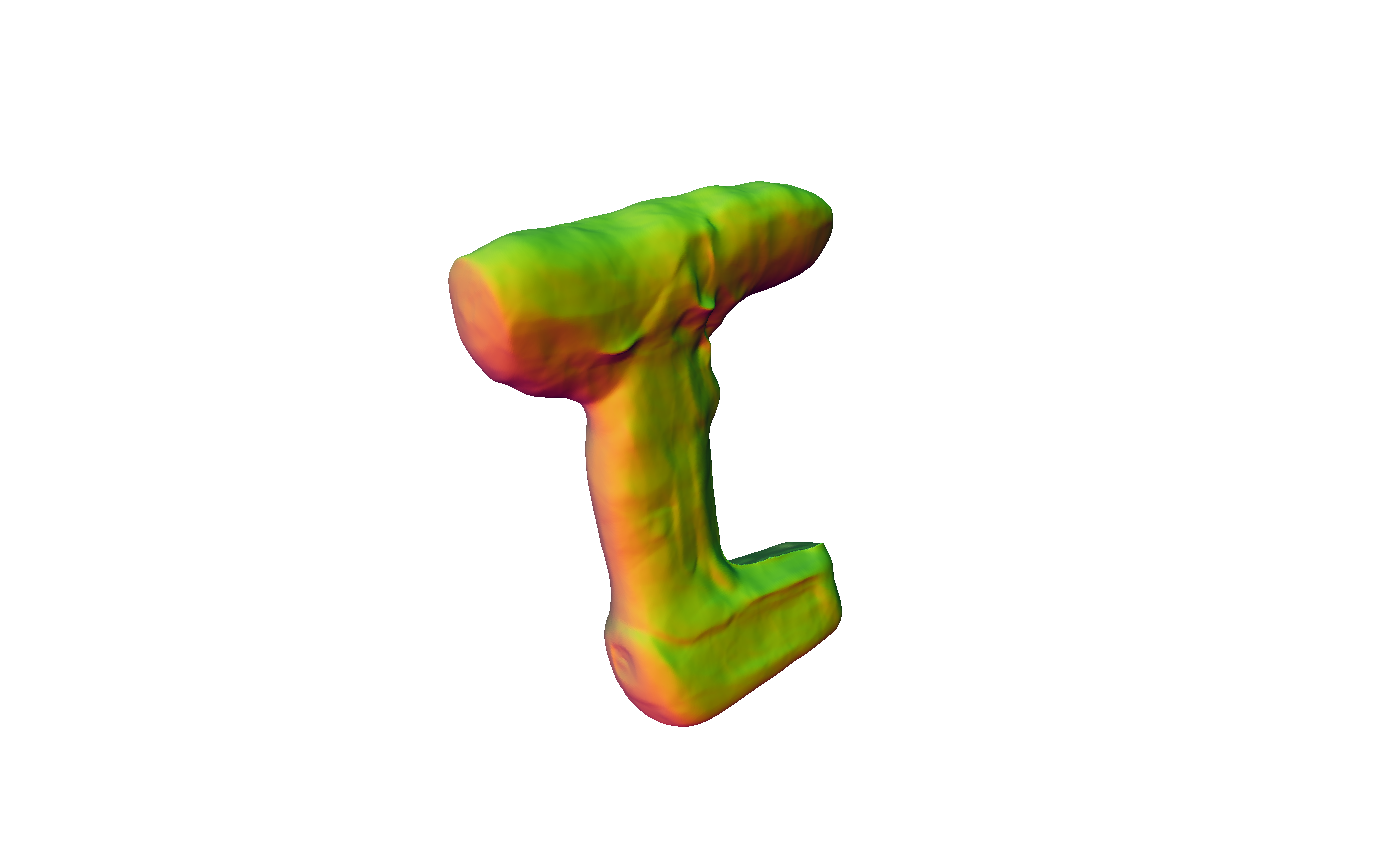



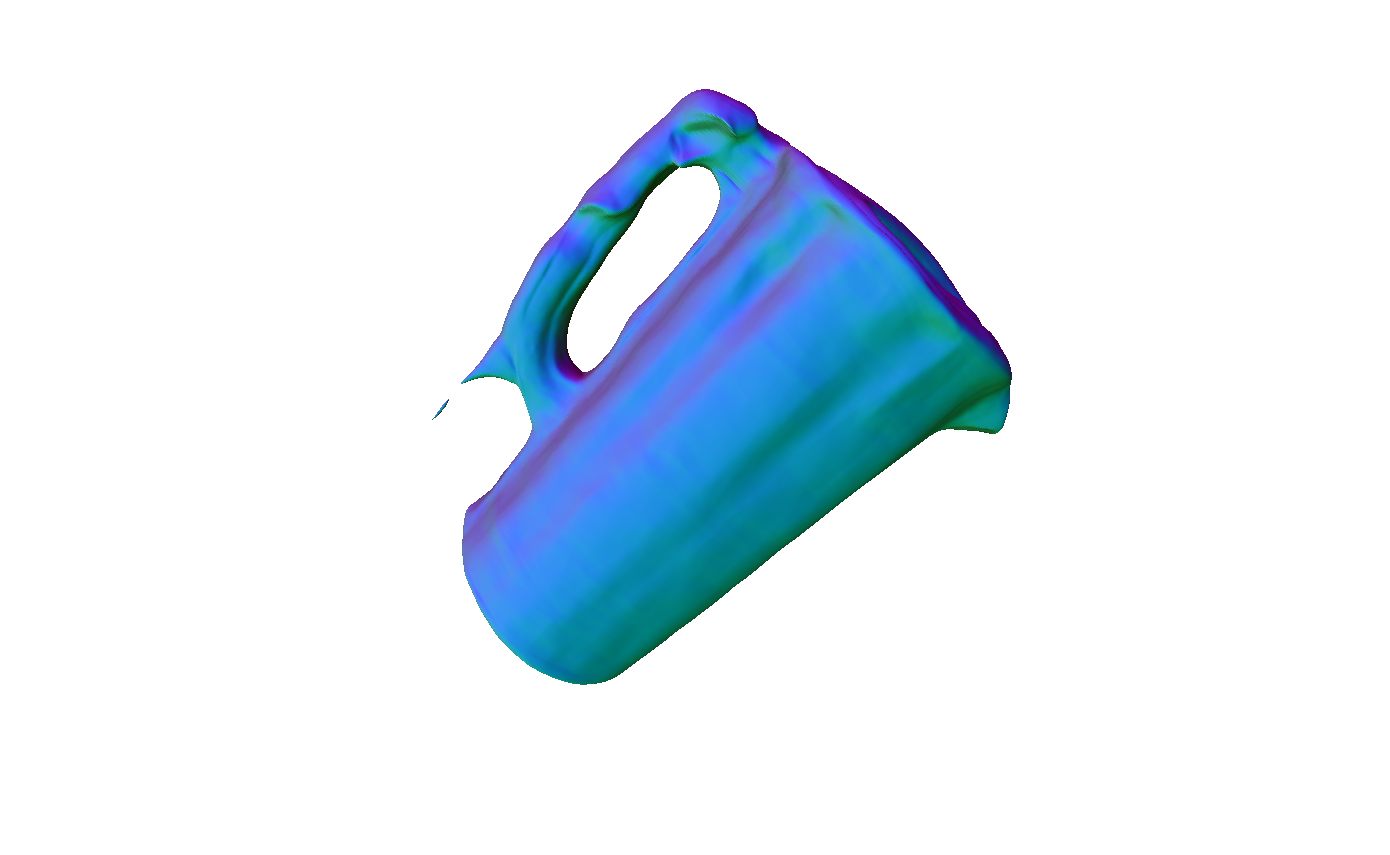
Figure 4: Reconstruction results showing superior mesh quality compared to existing methods.
Generalization to Egocentric Views
To explore generalization, sequences recorded with head-mounted cameras were tested, emphasizing dynamic manipulation environments. Despite the lack of category-specific training, the system managed to produce robust reconstruction results.
Limitations and Conclusion
While the approach is effective in most scenarios, limitations arise in cases with prolonged occlusions or extremely texture-less objects. These issues highlight areas for future enhancement, focusing on robustness for complex real-world applications.
In conclusion, the paper presents a system for joint reconstruction and pose estimation of free-moving objects, taking advantage of a novel virtual camera system to efficiently solve complex optimization problems without relying on category-specific data. Future work aims to expand its applicability across diverse environments and object types.