- The paper introduces a robust SLAM pipeline that leverages deep visual odometry, automatic camera intrinsic recovery, and monocular depth regularization for accurate 3D reconstructions.
- It employs advanced techniques such as dynamic object masking and loop closure integration to minimize drift and ensure continuous camera trajectories.
- Experimental results show superior performance over baseline methods, with smoother trajectories and enhanced robustness in unconstrained, real-world video settings.
Large-scale Visual SLAM for In-the-wild Videos
The "Large-scale Visual SLAM for in-the-wild Videos" paper addresses the pressing challenge of generating accurate 3D reconstructions from casual, unconstrained videos—a pivotal application for mobile robot deployment and autonomous navigation. The authors propose a robust pipeline leveraging deep visual odometry, automatic camera intrinsic recovery, dynamic object masking, and monocular depth estimates to advance scene comprehension without relying on structured environments or calibrated settings.
Problem Statement
The primary obstacle in 3D scene reconstruction from in-the-wild video is ensuring reliable camera pose estimation amid uncontrolled conditions, such as rapid camera rotations, forward movements, dynamic objects, and textureless regions. Classical visual SLAM and structure-from-motion (SfM) methods falter under these circumstances, frequently resulting in locally inconsistent models or split trajectories. To address these limitations, the authors introduce a method capable of generating consistent and contiguous trajectories for real-world applications.
Methodology
The proposed system begins by initializing the reconstruction using a structure-from-motion process to recover camera intrinsics from early video frames, setting the foundation for accurate visual SLAM. The pipeline comprises several innovative modules:
- Dynamic Object Masking: A semantic segmentation model identifies and excludes dynamic objects and sky regions, thus improving correspondence accuracy across frames.
- Deep Visual Odometry: The DPVO method is used for feature extraction and matching, which enhances correspondence estimation especially in textureless environments by employing deep optical flow rather than relying on keypoints.
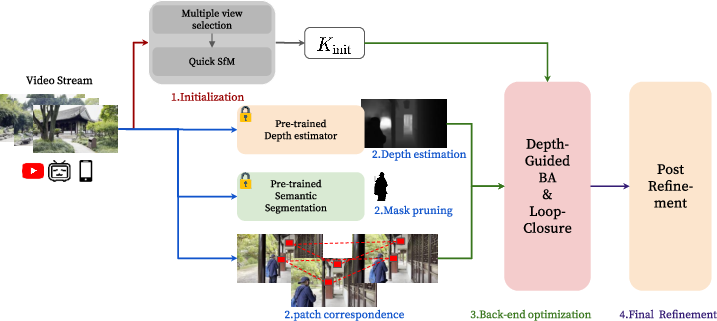
Figure 1: Overview of our method for large-scale visual SLAM.
- Monocular Depth Regularization: Depth maps estimated from monocular cues serve as regularization in bundle adjustment, addressing scenarios with small baselines and reducing pose estimation errors.
- Loop Closure Integration: NetVLAD-based place recognition and SIM(3) pose graph optimization minimize drift and improve trajectory consistency.
- Post-Refinement: Following initial mapping, a global bundle adjustment refines camera and scene parameters, ensuring the model’s fidelity over its longer paths.
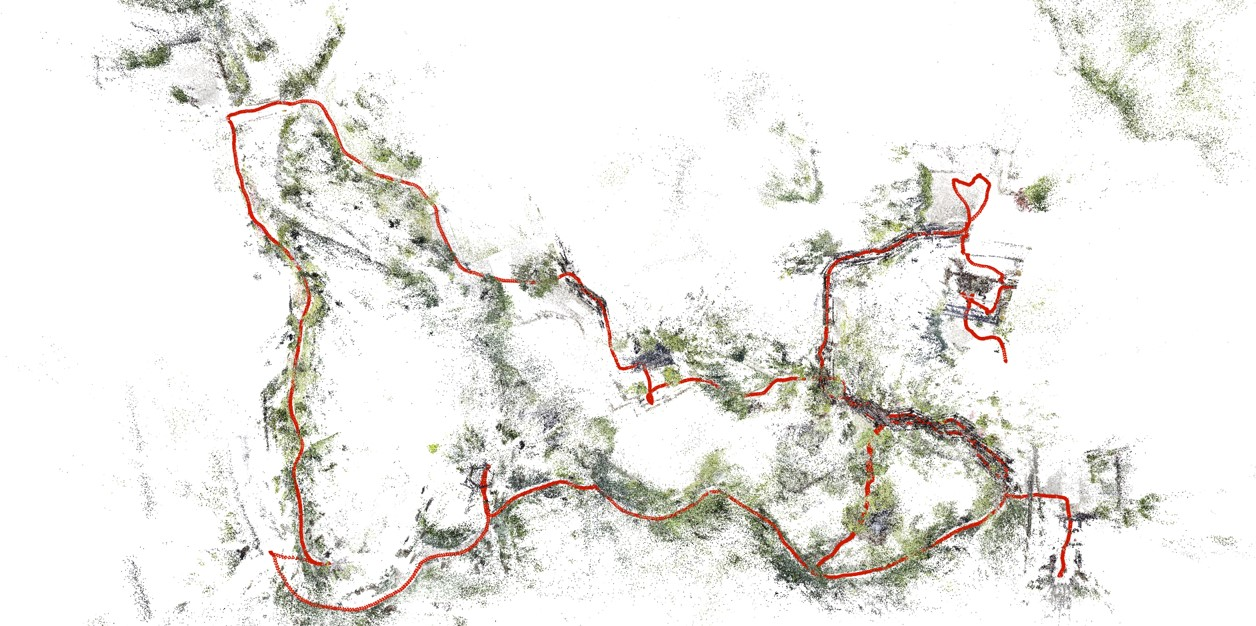

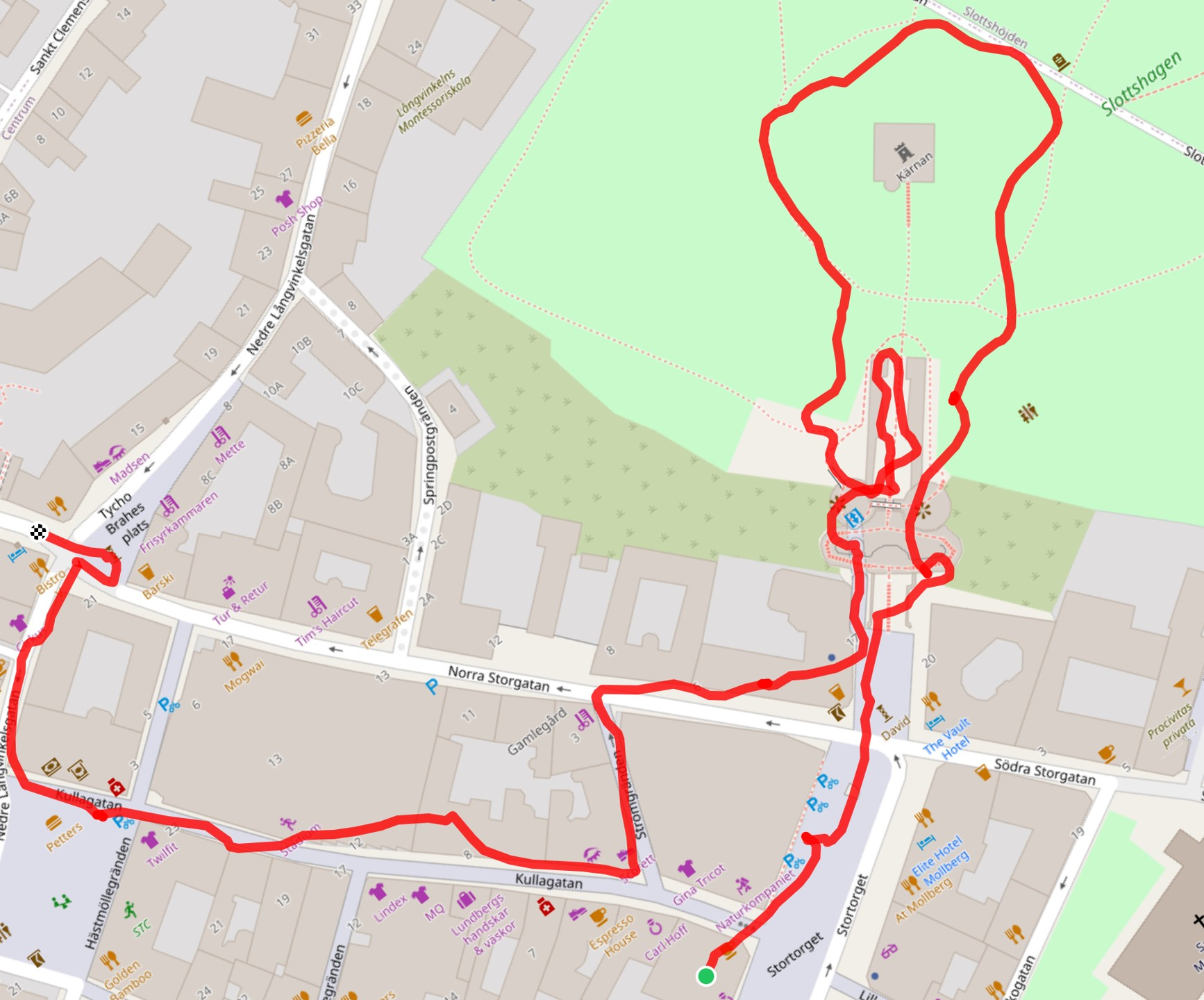
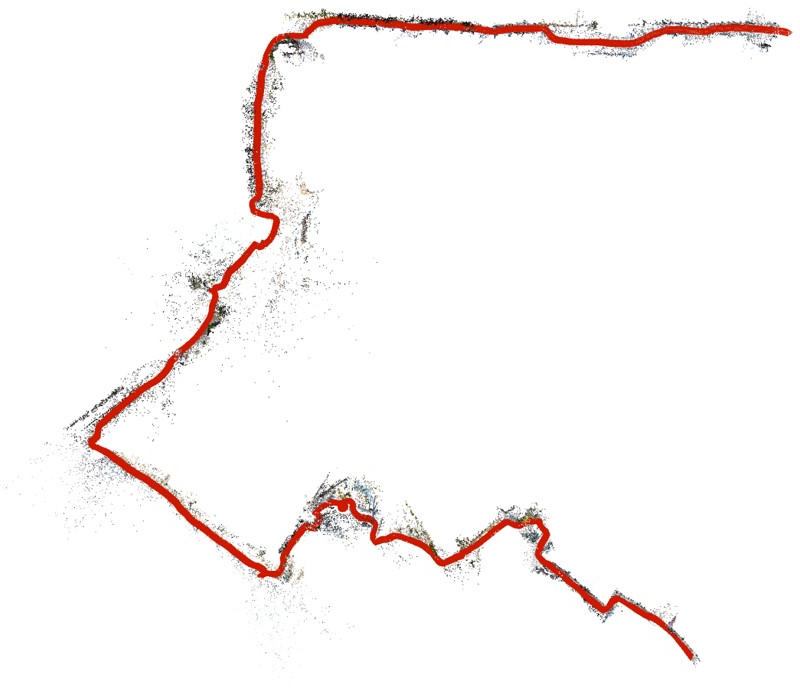
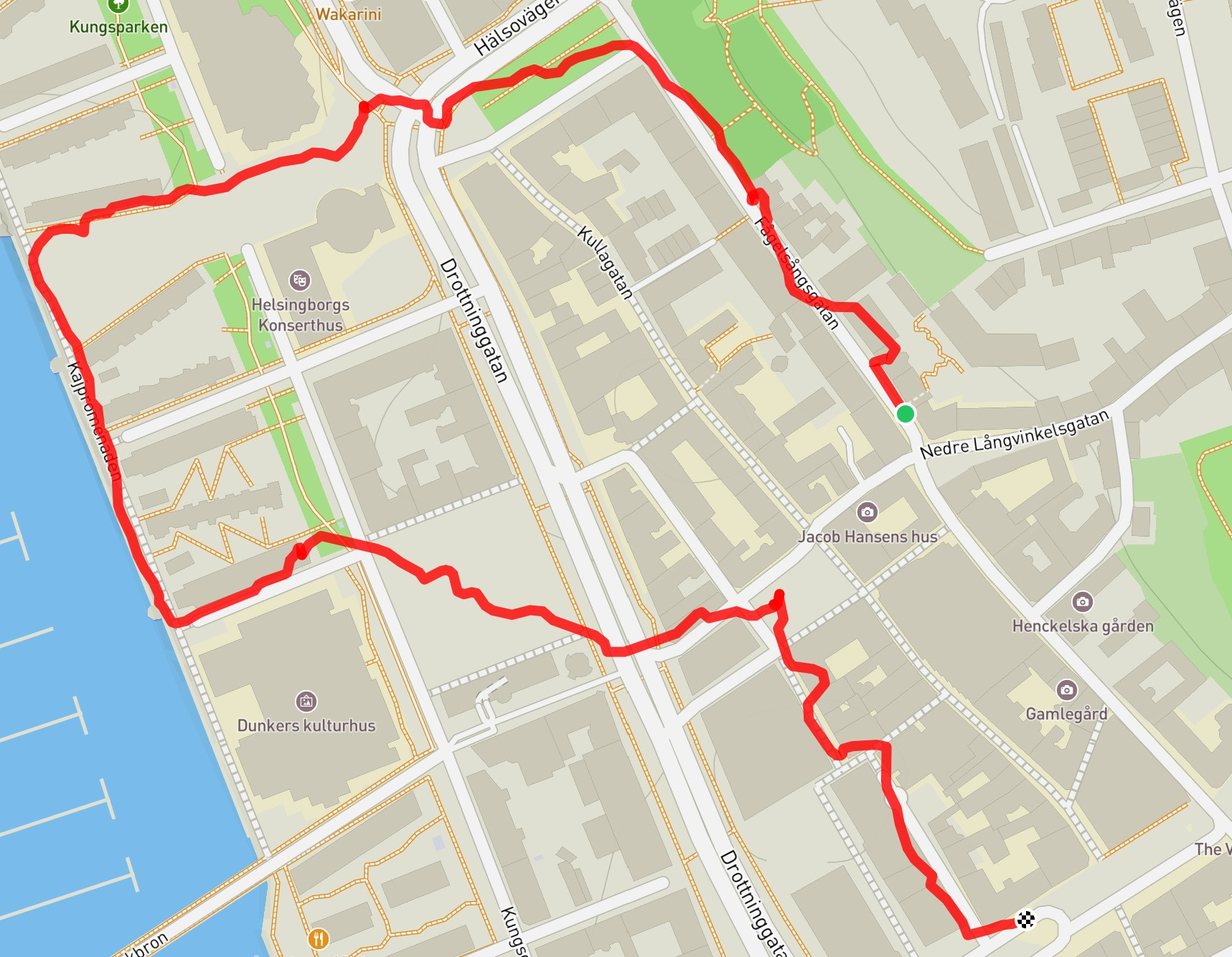
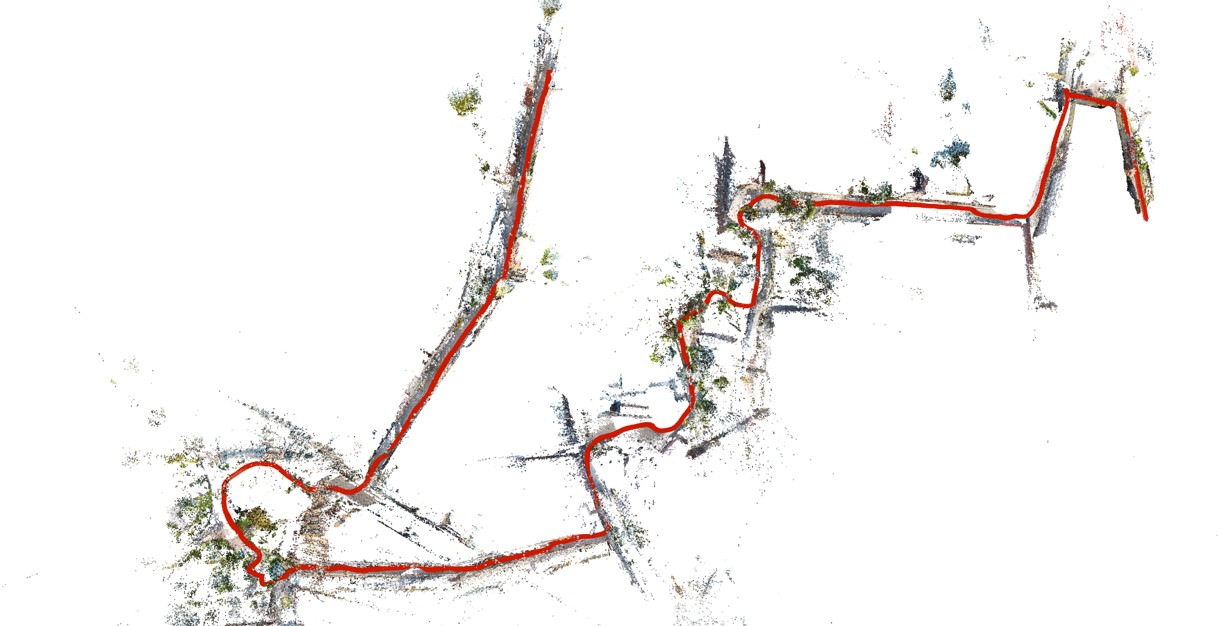
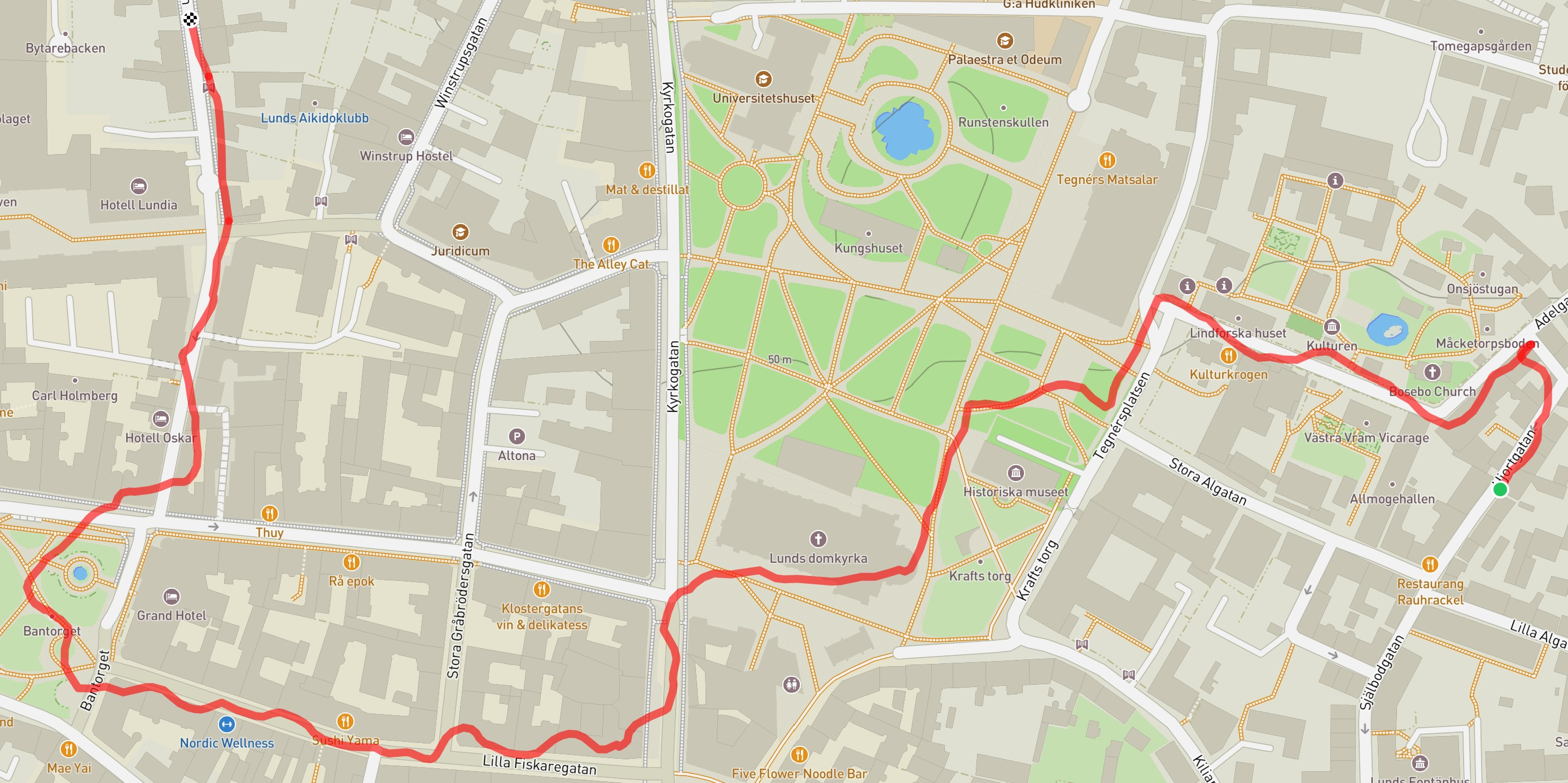
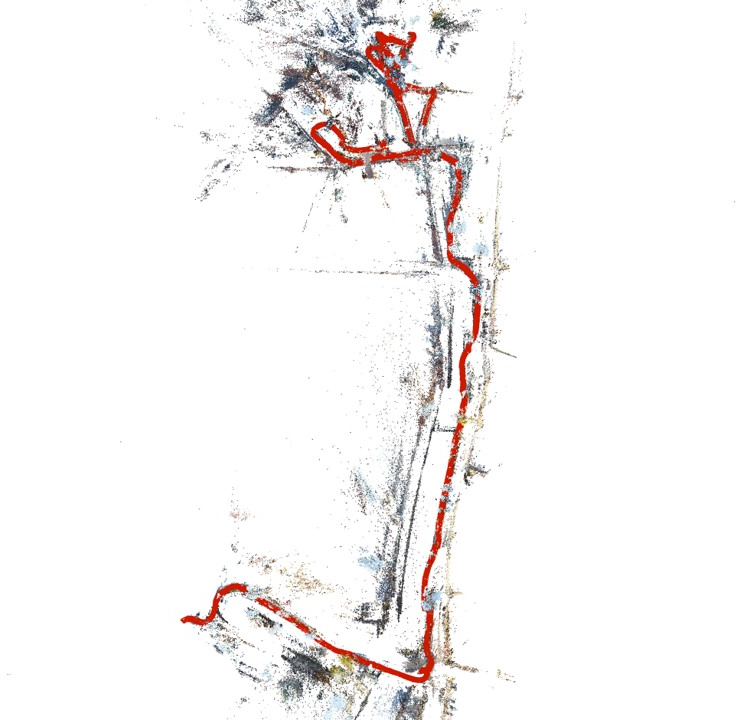
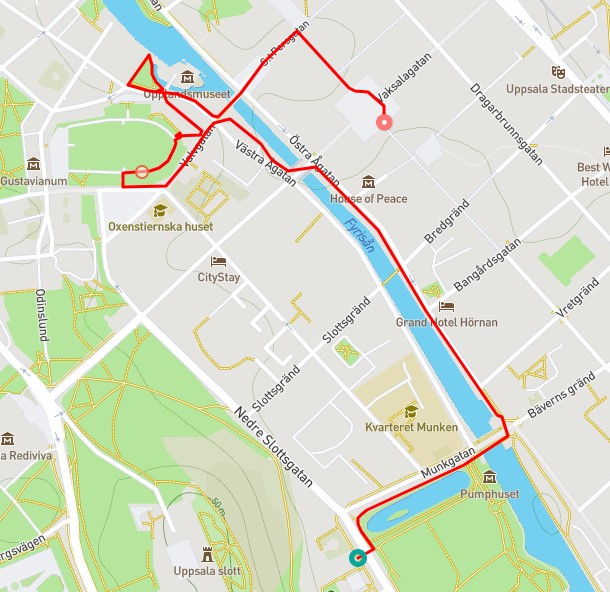
Figure 2: Reconstruction result visualization.
Experimental Results
Quantitative assessments showcase the proposed method's efficacy in registering the majority of frames across several indeterminate video sequences while maintaining contiguous paths without disruptions, contrasting sharply with COLMAP and GLOMAP baselines.
The qualitative analysis reveals smoother trajectory generation with fewer breaks and superior consistency, affirming the system's robustness. Evaluation metrics verified against NeRF-rendered scenes further underscore higher precision due to effective depth regularization and object masking.
Ablation Studies
Ablation experiments highlight the critical contributions of depth regularization, object masking, and loop closure detection—each contributing distinct improvements to performance and trajectory stability.
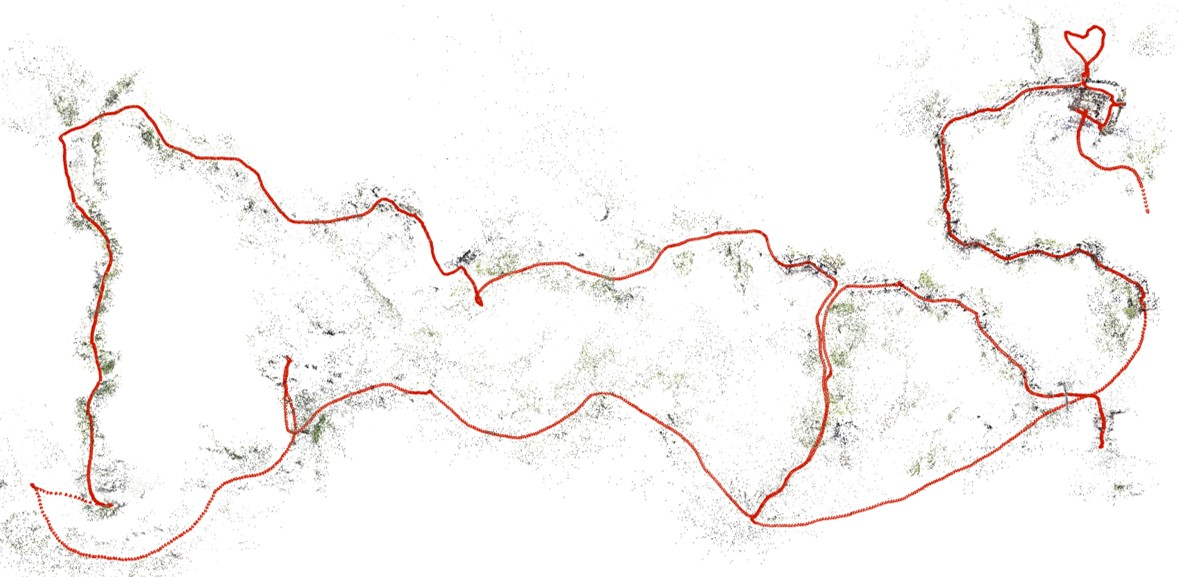
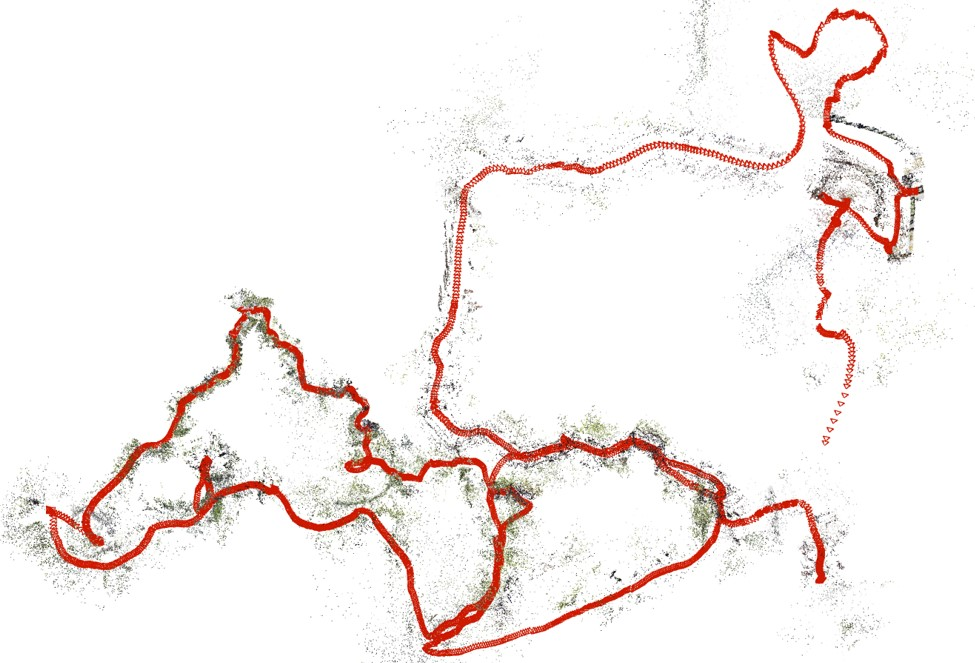
Figure 3: Robust focal estimations iteratively enhance long-sequence accuracy.
Conclusion
This paper's contributions emphasize a paradigm shift in visual SLAM, addressing intrinsic uncertainties of uncontrolled videos within large environments. The proposed system efficiently produces reliable reconstructions suitable for robotics and AR applications. While strides in robustness have been made, future directions will explore further drift reduction strategies and integration with increasingly dynamic settings to propel real-world navigation and mapping further.