- The paper introduces a hybrid de-duplication approach merging rule-based techniques with contrastive learning models to accurately identify duplicate MIDI files.
- The evaluation employs metrics like nDCG, precision, and recall, demonstrating that neural network-based models outperform simple hash and entropy methods.
- The proposed multi-level de-duplication filters enhance dataset integrity, ensuring more reliable results in symbolic music generation experiments.
On the De-duplication of the Lakh MIDI Dataset
This essay provides a comprehensive overview of the methods, results, and implications of the paper "On the de-duplication of the Lakh MIDI dataset" (2509.16662). The research focuses on addressing dataset duplication in the Lakh MIDI Dataset (LMD), a large-scale dataset widely utilized in music information retrieval (MIR) and music generation. Duplication within datasets is a critical issue that can impair the validity of experiments due to data leakage, and thus, the study explores various approaches to effectively detect and remove such duplicates.
The importance of large-scale datasets for deep learning models cannot be overstated, particularly in the domain of MIR where LMD is frequently used. However, the presence of duplicated data in LMD can lead to unreliable evaluations and biased training outcomes. Previous studies in other domains have tackled similar duplication issues, but the MIR community has yet to explore this problem extensively.
The LMD itself comprises several subsets, with variations based on matched files or different processing levels. Notably, the dataset duplication has been somewhat ignored, even as duplicated data can lead to significant data leakage, skewing the evaluation metrics used in academic studies. By addressing this oversight, the paper aims to mitigate issues in symbolic music generation experiments that rely on LMD.
Duplication Detection Methods
The authors explore a range of approaches for identifying and filtering duplicated files, including both rule-based methods and more sophisticated neural network models.
Rule-based Methods
The simplest methods rely on static file characteristics:
- MIDI Encoding Hash: This method utilizes MD5 hashes as a straightforward means to identify files with identical MIDI encodings.
- Beat Position Entropy: This technique checks for distribution uniformity of note positions within a measure, identifying files with identical beat structures.
- Chroma-DTW: By leveraging chromagram alignments and dynamic time warping (DTW), this approach measures pitch content similarity, although it discards temporal information.
Neural Network-Based Approaches
Several symbolic music embedding models were employed:
- MusicBERT and CLaMP Models: These pre-trained models use embeddings to determine similarity through cosine distance, with CLaMP models particularly optimized for retrieval tasks.
- Contrastive Learning-Based CAugBERT: The study introduces a custom BERT model trained with contrastive learning using various MIDI data augmentations to create positive sample pairs. This model aims to enhance duplication detection by accommodating variations in music arrangements.
Results and Evaluation
The evaluation of these methods involved retrieval metrics such as nDCG and classification metrics like precision and recall. Neural network-based methods generally outperformed rule-based strategies, with the MusicBERT and CLaMP series models achieving high fidelity in both retrieval and classification tasks. In terms of detectability, the proposed CAugBERT model exhibited superior performance when combined with the CLaMP-1024 model.
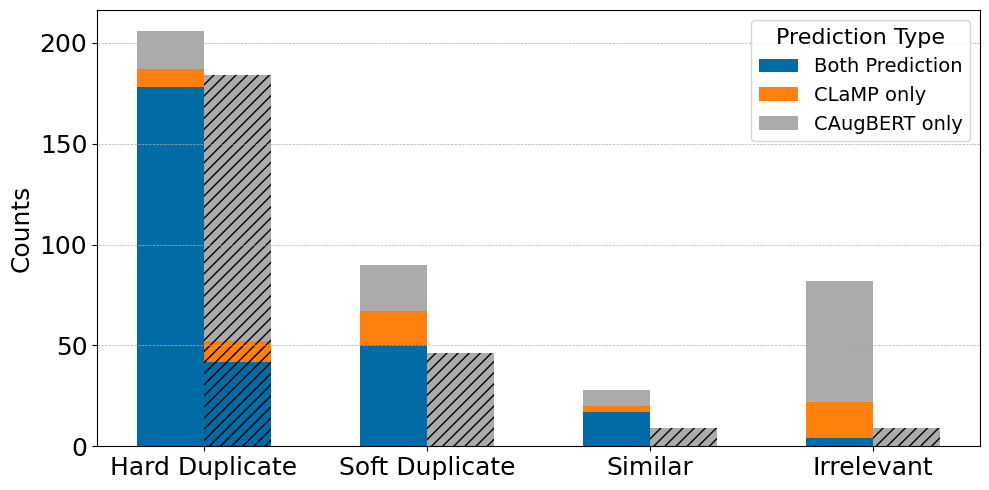
Figure 1: Listening test on 100 random LMD-full samples with detected duplicates. X-axis shows classified categories from Section \ref{section: deduplication.
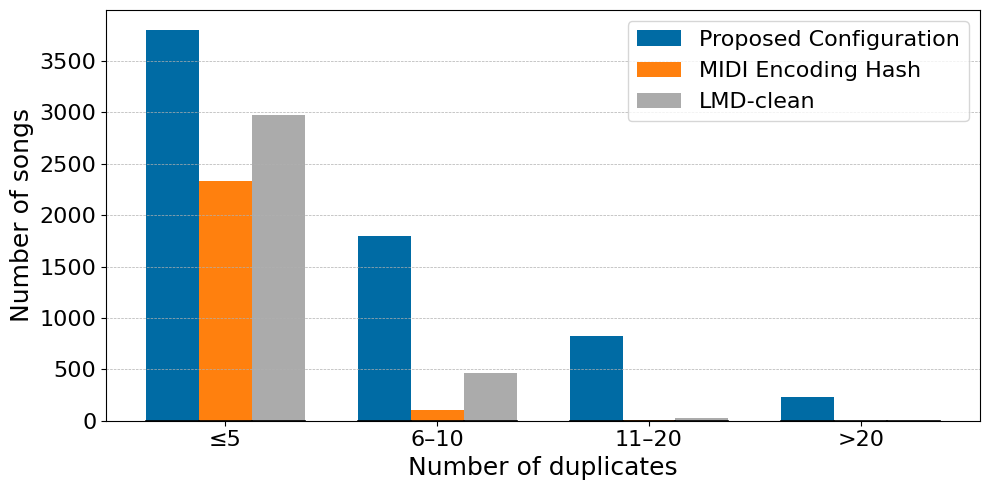
Figure 2: Duplicate count in LMD-full when queried with LMD-clean, using three different methods. LMD-clean duplicates based on the artist folder and filename.
The authors also highlight the limitations, noting the residual false negatives in detection, especially for more complex "soft" duplicates that involve significant variations in arrangements.
Implications and Contributions
The study's findings underscore the efficacy of incorporating contrastive learning and curated augmentations in tackling duplication within symbolic music datasets. By proposing a de-duplication strategy that combines rule-based and neural methods, the paper offers a practical solution that significantly reduces the duplication rate in LMD.
Three de-duplication versions of LMD are proposed, varying in the level of duplication filtering based on similarity thresholds. These filters aim to assist researchers in ensuring dataset integrity and validity when conducting symbolic music generation experiments.
Conclusion
The presented methods and findings pave the way for more reliable symbolic music generation, free from the biases introduced by dataset duplication. By improving the reliability of one of the most widely used datasets in MIR, this work fosters more accurate assessments and further research into advanced music generation models. Future explorations could focus on improving the robustness of existing detection models and extending similar methodologies to other symbolic music datasets.