- The paper presents a novel OC25 dataset with over 7 million DFT calculations to improve ML models for simulating solid-liquid interfaces.
- It employs high-temperature molecular dynamics and off-equilibrium sampling to capture diverse solvent and ion effects.
- Key evaluations show state-of-the-art models achieve low errors (0.105 eV energy, 0.015 eV/Å force), demonstrating robust predictive capabilities.
"The Open Catalyst 2025 (OC25) Dataset and Models for Solid-Liquid Interfaces" (2509.17862)
Introduction
The "Open Catalyst 2025 (OC25) Dataset and Models for Solid-Liquid Interfaces" paper introduces a comprehensive dataset aimed at improving machine learning models for solid-liquid interfaces, which are critical for understanding heterogeneous (electro)catalysis. Existing efforts such as OC20 and OC22 have focused on solid-gas interfaces, lacking the consideration of solvent effects crucial at solid-liquid interfaces. OC25 addresses this gap with over 7 million calculations covering 88 elements and various solvent and ion environments. Such data are vital for simulating long timescales and large length scales, fundamental for energy storage and chemical production applications.
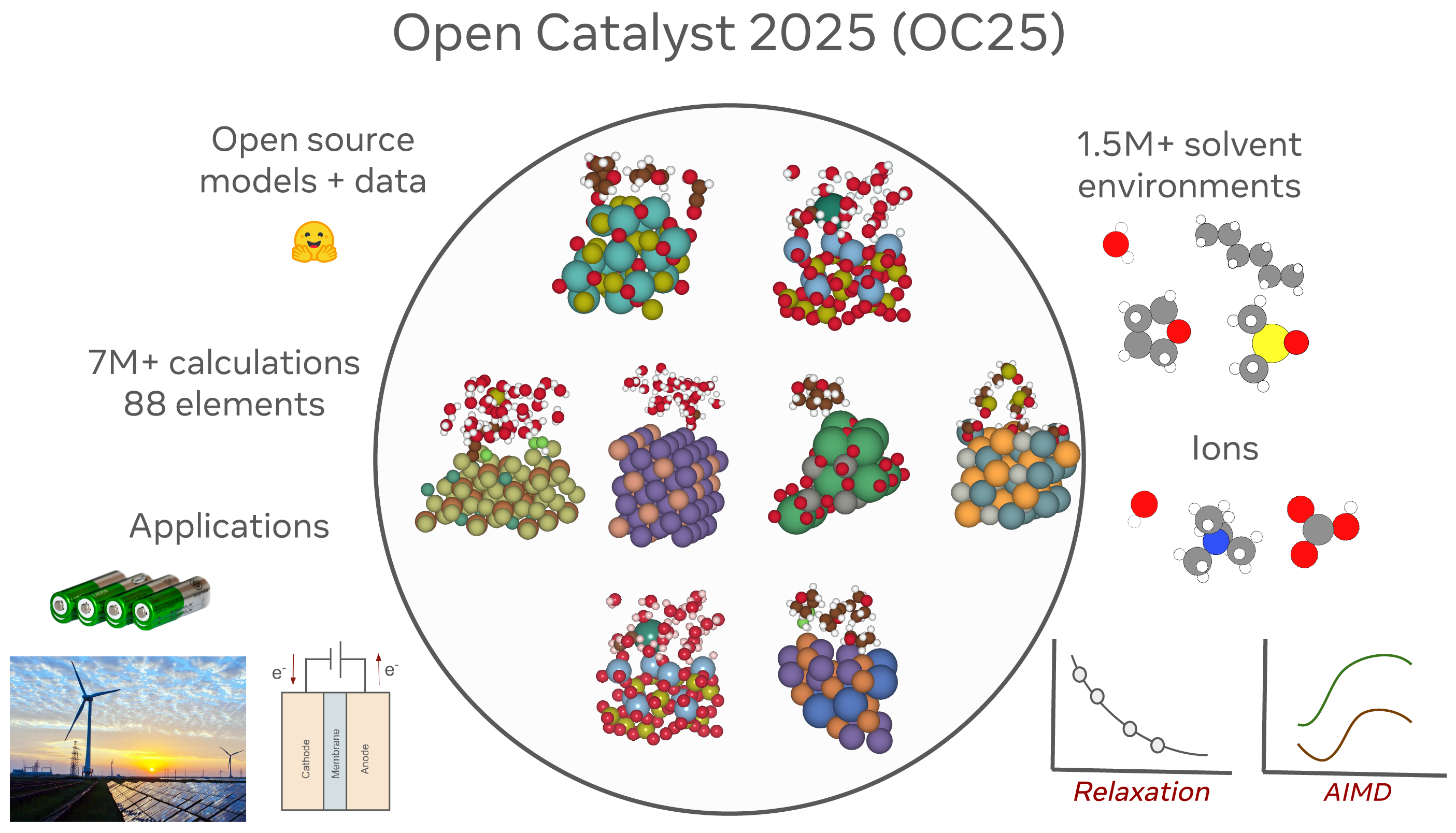
Figure 1: Overview of OC25, including dataset statistics, sampling strategies, relevant applications, and sample snapshots of the dataset.
OC25 Dataset Overview
The OC25 dataset is constructed from density functional theory (DFT) calculations, spanning over 1.5 million unique configurations. These configurations include distinct solvent and adsorption surface environments, capturing detailed solvent and ion effects at solid-liquid interfaces. The dataset's configurational diversity is achieved by sampling from the Materials Project and utilizing various solvents and ions to form complex adsorbate structures. Off-equilibrium sampling strategies allow the dataset to cover highly reactive configurations, aiding ML model training.
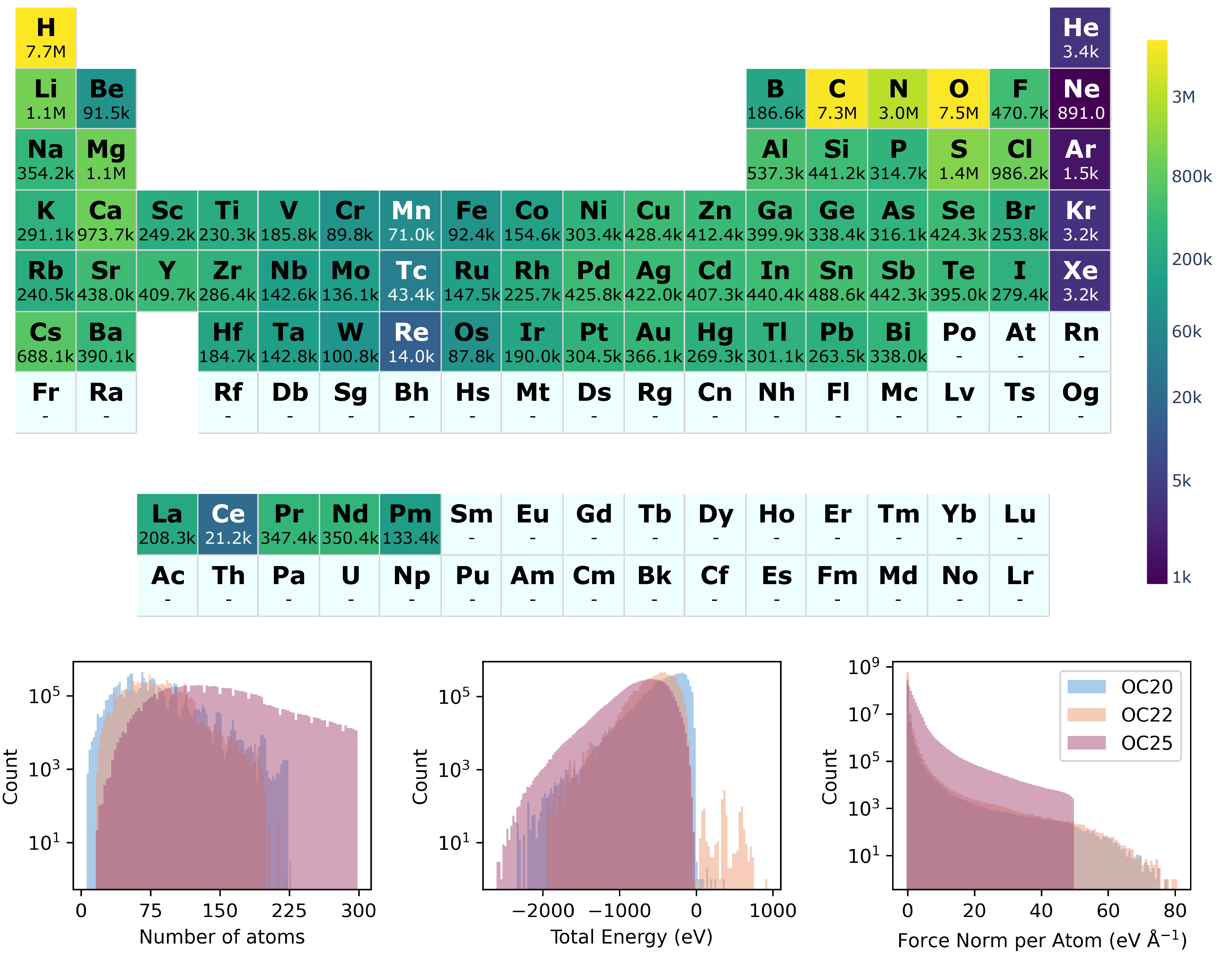
Figure 2: OC25 dataset distribution. (top) OC25 element distribution, with counts corresponding to the number of systems containing an element. (bottom) Distribution of the number of atoms, total energy, and force norm across the OC25, OC20, and OC22 datasets.
Methodology for Dataset Generation
OC25 follows a structured pipeline similar to OC20, with extensions for solvated interfaces. The dataset includes vacuum-based surface configurations and subsequent solvent and ion box additions. High-temperature molecular dynamics simulations provide off-equilibrium configurations, and pre-existing models (EquiformverV2-31M, UMA-S-1) are employed for geometry relaxation.
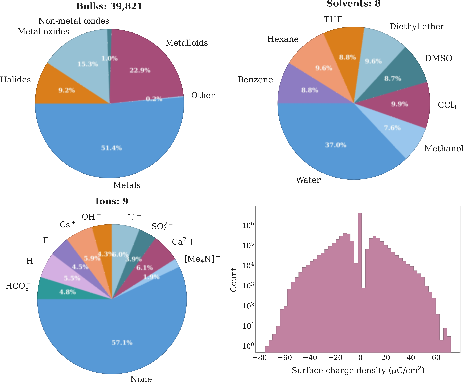
Figure 3: Overview of the bulks, solvents, ions sampled in OC25 and the surface charge distribution (in µC/cm2) for the metallic interfaces in the dataset.
Evaluations and Model Training
OC25 serves as a baseline for training state-of-the-art ML models like UMA and eSEN. Models are evaluated using mean absolute error (MAE) in energy and force prediction. Results show eSEN models achieve lower errors (e.g., 0.105 eV for energy and 0.015 eV/Å for forces), demonstrating the dataset's utility in capturing critical intermolecular interactions. Models trained on OC25 are robust against noise in force predictions, reflecting their capability to generalize across noise-imposed training conditions.
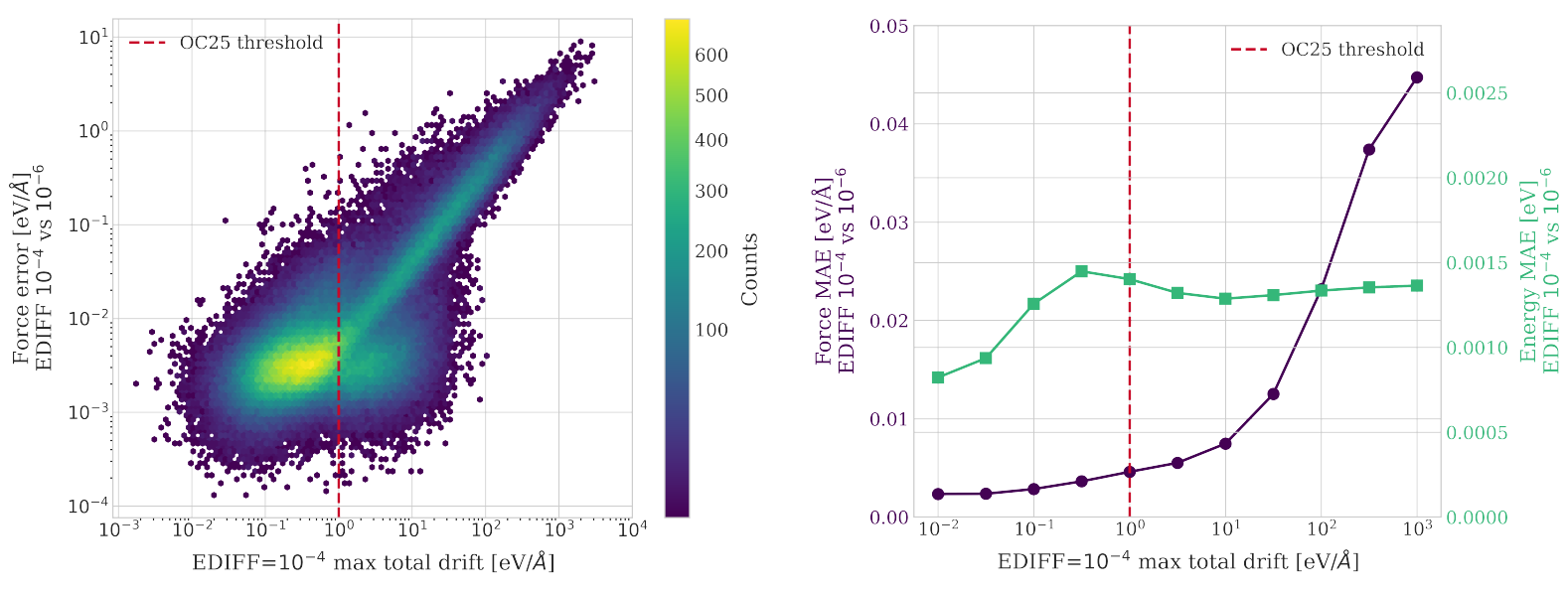
Figure 4: DFT force convergence errors as a function of the total drift in calculations with an electronic termination of 10−4 eV.
Force Convergence and Data Filtering
Force consistency in DFT is imperative to reliable dataset construction. OC25 employs electronic termination criteria aligned with broader works to balance accuracy and computation. Analyzing drift correlations, OC25 sets a conservative 1 eV/Å force drift threshold for dataset inclusion, ensuring high data quality for training.
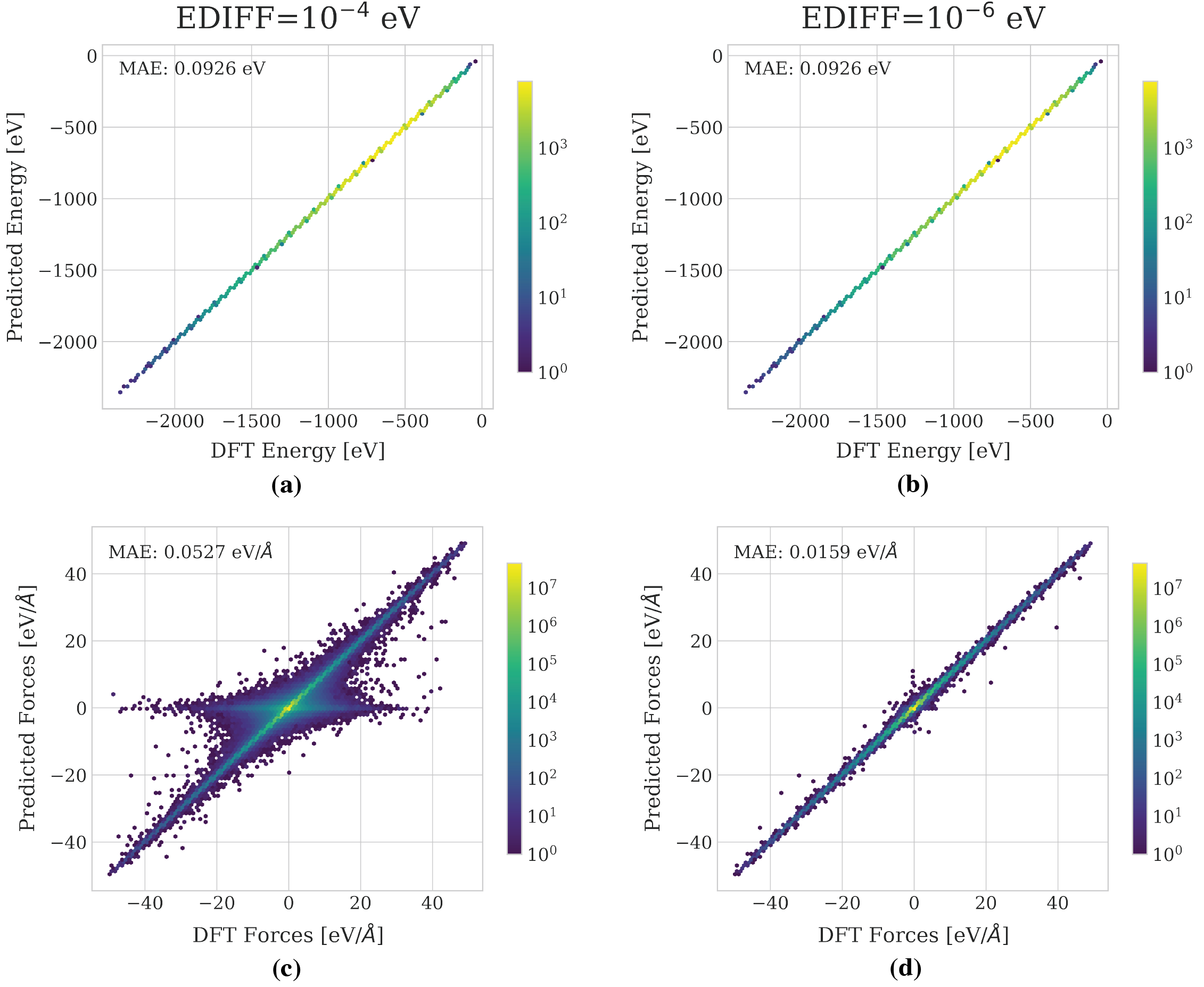
Figure 5: Parity plots of energy and force predictions of OC25 under different evaluation paradigms. A single model is trained on the unfiltered OC25 dataset and evaluated on an identical validation set calculated with the original (EDIFF=10−4) and tighter (EDIFF=10−6) settings.
Conclusion
The introduction of OC25 provides a significant resource for advancing machine learning models tailored to complex solid-liquid interfaces, crucial for catalysis and sustainable chemical production technologies. Despite its extensive coverage, OC25's model prediction accuracy, particularly in force and energy estimation, opens opportunities for enhanced ML techniques focusing on long-range interactions and charge distribution. Future research will benefit from exploring these aspects to accommodate larger solvent and ion spaces, ultimately propelling developments in energy storage and conversion.
This dataset and accompanying models enable significant advancements in the comprehension and simulation of catalytic processes, reinforcing the potential of ML-driven innovations in chemistry and materials science.